This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? Where Does CrUX’s RTT Data Come From?
While we understand it’s virtually impossible to achieve a linear increase in throughput as the number of vCPUs grow, a near-linear increase is attainable. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.” This was our starting point for troubleshooting.
Uploading and downloading data always come with a penalty, namely latency. Figure 2: Cloud Resource and Job Sizes This initial architecture was designed at a time when packaging from a list of chunks was not possible and terabyte-sized files were not considered.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
The first was voice control, where you can play a title or search using your virtual assistant with a voice command like “Show me Stranger Things on Netflix.” (See To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability.
Virtually any application with a user interface can benefit from regular real user monitoring. Providing insight into the service latency to help developers identify poorly performing code. And UX designers can use that data to better understand how users interact with an application and how developers can streamline the interface.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). PC, smartphone, server) or virtual (virtual machines, cloud gateways). Endpoints can be physical (i.e.,
We ran performance tests for MongoDB on DigitalOcean vs. AWS vs. Azure and found that DigitalOcean performance was in line with, if not better, on both high throughput and low latency in the deployment. DigitalOcean specialized in SSD-based virtual machines called Droplets that are broken down into four simple categories.
Virtualization can be a key player in your process’ performance, and Dynatrace has built-in integrations to bring metrics about the Cloud Infrastructure into your Dynatrace environment. And don’t worry if you’re on a different cloud platform, you can use a custom ActiveGate plugin to get insights into your virtualization.
But to understand if your cloud-based applications, as well as environments they run in, are working as designed, you need to see how every single application component communicates and interacts with the others. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Requirements.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Amazon DynamoDB offers low, predictable latencies at any scale. Comments ().
Today we have a wealth of tools, both OSS and commercial, all designed for cloud-native environments. To improve availability, we designed systems where components could fail separately and avoid single points of failure. There is a downside to fetching this data on-demand: this adds latency to the first request to a cluster.
But to understand if your cloud-based applications, as well as environments they run in, are working as designed, you need to see how every single application component communicates and interacts with the others. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Requirements.
Many of those failure scenarios can be anticipated beforehand, but many more are unknown at design and build time. We knew that designing APIs was a very important task as we’d only have one chance to get it right. For some time now, support for encryption has been integrated at the design phase of each new service.
Fig 3: POSIX interface of Netflix Drive The POSIX files and folders interface for Netflix Drive is designed as a layered system with the FUSE implementation hooks forming the top layer. Security is one of the cornerstones of Netflix Drive design. The final encoded copy needs to be persisted and the ephemeral data can be deleted.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Powering the virtual instances and other resources that make up the AWS Cloud are real physical data centers with AWS servers in them. Even though the network design for each data center is massively redundant, interruptions can still occur. This design has a double benefit. How Availability Zones have changed over the years.
On April 24, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. Were experiencing high latency in responses.
The Amazon Virtual Private Cloud extends on-premises compute with all the power of AWS, making it elastic, scalable and highly reliable. Amazon S3 is designed to sustain the concurrent loss of data in two facilities, redundantly storing your data on multiple devices across multiple facilities in an AWS Region. s storage infrastructure.
Various forms can take shape when discussing workloads within the realm of cloud computing environments – examples include order management databases, collaboration tools, videoconferencing systems, virtual desktops, and disaster recovery mechanisms. This applies to both virtual machines and container-based deployments.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. The key specifications for the Lsv2 series virtual machines are shown in Table 1. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0
Infrastructure Excellence ScaleGrid’s infrastructure is designed to facilitate hosting in your cloud account and provides cost-saving options with AWS or Azure Reserved Instances or GCP. Meeting Business Demands with Hybrid Cloud A range of business demands can be met by the design of hybrid cloud solutions.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. There are roughly 50 performance tests, each one designed to reproduce an aspect of member engagement. Every test runs on a combination of devices (physical and virtual) and platform versions ( SDKs ).
With these requirements in mind, and a willingness to question the status quo, a small group of distributed systems experts came together and designed a horizontally scalable distributed database that would scale out for both reads and writes to meet the long-term needs of our business. This was the genesis of the Amazon Dynamo database.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. Today, we are further expanding the choices available for designing and developing highly scalable and high performance apps.
On-Premises Data Center A hybrid cloud architecture necessitates that an organization retains full authority over its physical or virtual infrastructure within the private cloud segment. Defining Hybrid Cloud Strategy The decision-making process about where to situate data and applications is vital to any hybrid cloud solution.
Their design emphasizes increasing availability by spreading out files among different nodes or servers — this approach significantly reduces risks associated with losing or corrupting data due to node failure. Variations within these storage systems are called distributed file systems.
On Saturday, the ISO C++ committee completed the second-last design meeting of C++26, held in Hagenberg, Austria. The main change last week is that the committee decided to postpone supporting contracts on virtual functions; work will continue on that and other extensions. This can create variable latency during iteration.
Operating System (OS) settings Swappiness Swappiness is a Linux kernel setting that influences the behavior of the Virtual Memory manager when it needs to allocate a swap, ranging from 0-100. The CFQ works well for many general use cases but lacks latency guarantees. Without further ado, let’s start with the OS settings.
You could play with it until you felt like building something else and turning the current models into interior design pieces. Digital twins : Creates virtual models of physical assets for real-time analysis, offering insights into asset performance and maintenance needs. The beauty of Legos was (is) the “one and done” aspect of it.
It was – like the hypothetical movie I describe above – more than a little bit odd, as you could leave a session discussing ever more abstract layers of virtualization and walk into one where they emphasized the critical importance of pinning a network interface to a specific VM for optimal performance.
In both cases, when using virtually-synchronous replication, the process will require certification from each node and local (by node) write; as such, the number of writes is NOT distributed across multiple nodes but duplicated. Because the solutions still rely on writing in one single node that works as Primary. eu-central-1.elb.amazonaws.com
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
There are different considerations when deciding where to allocate resources with latency and cost being the two obvious ones, but compliance sometimes plays an important role as well. The Cloud First strategy is most visible with new Federal IT programs, which are all designed to be â??Cloud Cloud Readyâ??; Recent Entries.
If products are not designed, keeping testability in mind, achieving continuous testing may become a distant dream. Maintaining test data in a central repository and then accessing it from different test environments may ease this problem but may introduce other issues like network latency in tests. Not always!
The General Purpose tier is designed for applications with typical performance and I/O latency requirements and provides built-in HA. The Business Critical tier is designed for applications that require low I/O latency and higher HA requirements. Managed Instance provides two tiers for performance. GB per vCore.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
using Compute Express Link or CXL), organizing memory components for optimal performance, adapting system software traditionally designed for homogeneous memory systems, and developing memory abstractions and programming constructs for HCM management. Figure 2: Latency characteristics of memory technologies (source: Maruf et al.,
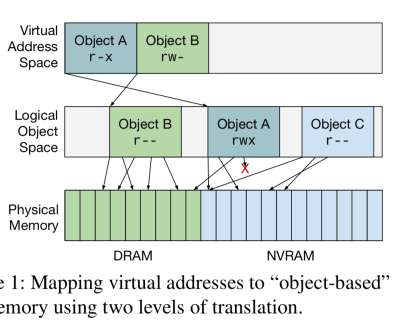
This is a companion paper to the " persistent problem " piece that we looked at earlier this week, going a little deeper into the object pointer representation choices and the mapping of a virtual object space into physical address spaces. " Epheremal virtual addresses don’t cut it as the basis for persistent pointers.
ITSM defines how teams design, create, and deliver their services. You cannot virtualize everything…yet. Knowing when and where an error, downtime, or application latency occurs is a critical factor in limiting the impact to users and customers. It is much more than just IT support. Asset Management.
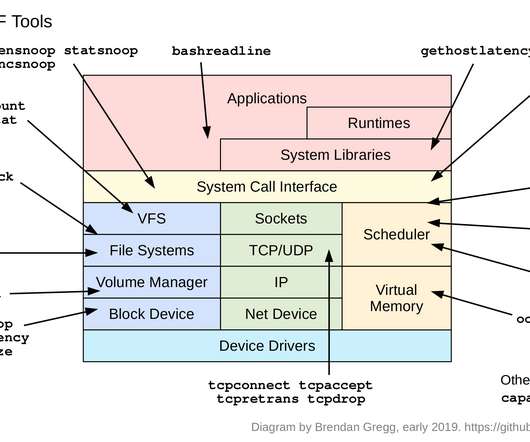
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. bpftrace uses BPF (Berkeley Packet Filter), an in-kernel execution engine that processes a virtual instruction set.
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content