This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. The streaming data store makes the system extensible to support other use-cases (e.g. System Components. Component Design. API Design. Problem Statement.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? Where Does CrUX’s RTT Data Come From?
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform.
It involves a combination of techniques and best practices aimed at reducing latency, improving user experience, and increasing the overall efficiency of the system. API performance optimization is the process of improving the speed, scalability, and reliability of APIs.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
Welcome back to the blog series in which we share how you can easily solve three common problem scenarios by using Dynatrace and xMatters Flow Designer. This is where xMatters Flow Designer comes into play, by automating remediation steps at the touch of a button. Step 5 – xMatters triggers a runbook in Ansible to fix the disk latency.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets.
In this article, we will explore one of the most common and useful resilience patterns in distributed systems: the circuit breaker. The circuit breaker is a design pattern that prevents cascading failures and improves the overall availability and performance of a system. What Is a Circuit Breaker?
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. cell): Titus Job Coordinator is a leader elected process managing the active state of the system. For example, a batch workflow orchestration system may create multiple jobs which are part of a single workflow execution.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
In this article, we discuss the concepts of dependability and fault tolerance in detail and explain how the Ably platform is designed with fault tolerant approaches to uphold its dependability guarantees. Fault tolerant design approaches address these shortfalls to provide continuity both to business and to the user experience.
Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients. Uploading and downloading data always come with a penalty, namely latency. There are existing distributed file systems for the cloud as well as off-the-shelf FUSE modules for S3.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The first generation of this system went live with the streaming launch in 2007. Delivery?—?A
Sample system diagram for an Alexa voice command. The other main use case was RENO, the Rapid Event Notification System mentioned above. To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability.
This is where large-scale system migrations come into play. By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. But what happens when this machinery needs a transformation?
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
AWS Lambda enables organizations to access many types of functions from AWS’ cloud-based services, such as: Data processing, to execute code based on triggers, system states, or user actions. You will likely need to write code to integrate systems and handle complex tasks or incoming network requests.
The network latency between cluster nodes should be around 10 ms or less. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms network latency due to asynchronous data replication between regions. In the image below, three downed nodes make an entire cluster unavailable.
GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues. Dynatrace provides end-to-end observability of AI applications As AI systems grow in complexity, a holistic approach to the observability of AI-powered applications becomes even more crucial.
Monitors signals The first attribute of a good SLO is the ability to monitor the four “golden signals”: latency, traffic, error rates, and resource saturation. In practice, however, SLOs’ value varies significantly based on how teams design, deploy, and manage them.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
This architecture shift greatly reduced the processing latency and increased system resiliency. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications.
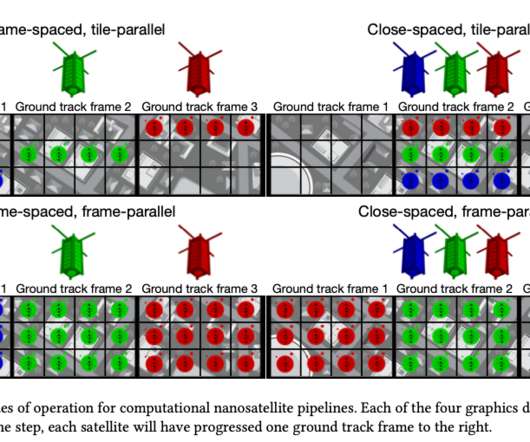
Orbital edge computing: nanosatellite constellations as a new class of computer system , Denby & Lucia, ASPLOS’20. Only space system architects don’t call it request-response, they call it a ‘ bent-pipe architecture.’. The old ground-initiated command-and-control style systems aren’t going to work for these finer-grained systems.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. The architects and developers who create the software must design it to be observed. Dynatrace news. But what is observability? What is observability?
For each route we migrated, we wanted to make sure we were not introducing any regressions: either in the form of missing (or worse, wrong) data, or by increasing the latency of each endpoint. Being able to canary a new route let us verify latency and error rates were within acceptable limits. This meant that data that was static (e.g.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. How Bulldozer leverages Spark, Protobuf and KV DAL for moving the data.
An AI observability strategy—which monitors IT system performance and costs—may help organizations achieve that balance. AI observability is the use of artificial intelligence to capture the performance and cost details generated by various systems in an IT environment. Additionally, organizations need to consider AI observability.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
System Setup Architecture The following diagram summarizes the architecture description: Figure 1: Event-sourcing architecture of the Device Management Platform. Fault Tolerance If the underlying KafkaConsumer crashes due to ephemeral system or network events, it should be automatically restarted.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. Use cases We found several use cases where a system like AutoOptimize can bring tons of value. We can also reorganize the metadata to make file scanning much faster.
We designed a unique concept called Annotation Operations which allows teams to create data pipelines and easily write annotations without worrying about access patterns of their data from different applications. But we cannot search or present low latency retrievals from files Etc. This is obviously very expensive.
Analyzing a clinician’s clickstream when using an electronic medical record system to better improve the efficiency of data entry. Providing insight into the service latency to help developers identify poorly performing code. Tracking users’ paths through the conversion funnel and using that data for attributing revenue.
False negatives are closely related to the statistical concept of power , which gives the probability of a true positive given the experimental design and a true effect of a specific size. As a result, if the test treatment results in a small reduction in the latency metric, it’s hard to successfully identify?
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content