This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Component Design. API Design. We have provided the API design of posting an image on Instagram below. API Design. Problem Statement. Architecture. Fetching User Feed.
The goal is to help developers, technical managers, and business owners understand the importance of API performance optimization and how they can improve the speed, scalability, and reliability of their APIs. API performance optimization is the process of improving the speed, scalability, and reliability of APIs.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency.
Speed and scalability are significant issues today, at least in the application landscape. We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases. However, the question arises of choosing the best one.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This decoupling simplifies system architecture and supports scalability in distributed environments. Choosing between RabbitMQ and Kafka depends on your specific messaging needs.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? How can we design systems that recognize these nuances and empower every title to shine and bring joy to ourmembers?
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Why Use Spring WebFlux?
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. This setup prioritizes data safety, with most replicas online at any given time.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. It also serves as central configuration of access patterns such as consistency or latency targets.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
It's HighScalability time: Have a very scalable Xmas everyone! Tim Bray : How to talk about [Serverless Latency] · To start with, don’t just say “I need 120ms.” See you in the New Year. Do you like this sort of Stuff? Please support me on Patreon. I'd really appreciate it. Explain the Cloud Like I'm 10.
Every new origin we need to visit needs a connection opening, and that can be very costly: DNS resolution, TCP handshakes, and TLS negotiation all add up, and the story gets worse the higher the latency of the connection is. On a slower, higher-latency connection, the story is much, mush worse. All completely avoidable. to just 3.6s.
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. This is not an easy task, considering the wide variety of supported devices and the sheer volume of actions our members perform.
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. We started seeing increased response latencies and leader servers running at dangerously high utilization.
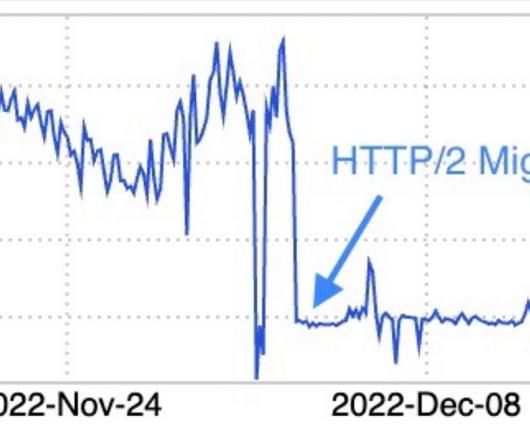
LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. By Rafal Gancarz
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The third generation, called Reloaded , has been online for about seven years and has proven to be stable and massively scalable.
SRE is the transformation of traditional operations practices by using software engineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Designating and managing Service Level Objectives (SLOs) as availability targets for a service.
However, only highly scalable real user monitoring solutions can collect data on all user actions, while less scalable tools have to sample user actions and make inferences from partial data. Providing insight into the service latency to help developers identify poorly performing code. How real user monitoring works.
In particular, it’s our job to design and build the systems and protocols that enable customers from all over the world to sign up for Netflix with the plan features and incentives that best suit their needs. This was a perfectly sufficient design for many years. To name a few: Updating XML files is error-prone and manual in nature.
Lambda’s toolbox of automated processes helps developers streamline to build fast, robust, and scalable applications on accelerated timelines. AWS continues to improve how it handles latency issues. As The New Stack reports, developers spend only 32% of their time at work actually coding. It helps SRE teams automate responses.
When an observability solution also analyzes user experience data using synthetic and real-user monitoring, you can discover problems before your users do and design better user experiences based on real, immediate feedback. The architects and developers who create the software must design it to be observed. Benefits of observability.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
By adopting a cloud- and edge-based AI approach, teams can benefit from the flexibility, scalability, and pay-per-use model of the cloud while also reducing the latency, bandwidth, and cost of sending AI data to cloud-based operations. Use containerization. Continuously monitor AI models’ performance.
By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Increased latency during peak loads. Introduce scalable microservices architectures to distribute computational loads efficiently.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. Figure 1 shows how we use Bulldozer to move data at Netflix. Moving data with Bulldozer at Netflix.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Storage: don’t break the bank!
We will share how its design has evolved over the years and the lessons learned while building it. To understand Axion’s design, we need to know the various components that interact with it. The motivation has not changed since then; the design has. Design evolution Axion fact store has four components?—?fact
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. We explore all the systems necessary to make and stream content from Netflix.
The breadth of fully-featured services, the pay-as-you-go scalability, and the agility of cloud platforms enable organizations to expand their modern approaches to building and managing digital services in a way they can’t with on-premises apps and infrastructure. Increased scalability. Reduced cost.
Since its inception , Metaflow has been designed to provide a human-friendly API for building data and ML (and today AI) applications and deploying them in our production infrastructure frictionlessly. In other cases, it is more convenient to share the results via a low-latency API.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. Transparency to end-users.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. Purpose-built databases.
As VMAF evolves and is integrated with more encoding and streaming workflows within Netflix, we need scalable ways of fostering video quality innovations. For example, when we design a new version of VMAF, we need to effectively roll it out throughout the entire Netflix catalog of movies and TV shows. The workflow is initiated.
The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post. By the following morning, alerts were received regarding high memory consumption and GC latencies, to the point where the service was unresponsive to HTTP requests.
You can use these services in combinations that are tailored to help your business move faster, lower IT costs, and support scalability. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Metrics for each service instance are presented in detailed charts—see the example for ECS below.
To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures. This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked.
However, this design decision led to a different set of challenges. Additionally, instead of implementing business logic by composing multiple individual Processors together, users could express their logic in a single SQL query, avoiding the additional resource and latency overhead that came from multiple Flink jobs and Kafka topics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content