This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Component Design. API Design. We have provided the API design of posting an image on Instagram below. API Design. Problem Statement. Architecture. Fetching User Feed.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? Where Does CrUX’s RTT Data Come From?
Recently, we added another powerful tool to our arsenal: neural networks for video downscaling. In this tech blog, we describe how we improved Netflix video quality with neural networks, the challenges we faced and what lies ahead. How can neural networks fit into Netflix video encoding?
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
Imagine a bustling city with a network of well-coordinated traffic signals; RabbitMQ ensures that messages (traffic) flow smoothly from producers to consumers, navigating through various routes without congestion. Quorum queues can still function during a network partition as long as most nodes communicate.
Remote calls are never free; they impose extra latency, increase probability of an error, and consume network bandwidth. How can we achieve a similar functionality when designing our gRPC APIs? This can become an issue for some applications, for example, on mobile devices with limited network bandwidth.
Compressing them over the network: Which compression algorithm, if any, will we use? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Read the complete test methodology.
The circuit breaker is a design pattern that prevents cascading failures and improves the overall availability and performance of a system. A dependency can become unhealthy or unavailable for various reasons, such as network failures, high latency, timeouts, errors, or overload. What Is a Circuit Breaker?
The networklatency between cluster nodes should be around 10 ms or less. Minimized cross-data center network traffic. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms networklatency due to asynchronous data replication between regions.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets.
Penalty: Network Negotiation. Every new origin we need to visit needs a connection opening, and that can be very costly: DNS resolution, TCP handshakes, and TLS negotiation all add up, and the story gets worse the higher the latency of the connection is. On a slower, higher-latency connection, the story is much, mush worse.
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. We started seeing increased response latencies and leader servers running at dangerously high utilization.
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. The desire for CPU efficiency and lower latencies is easy to understand. SOSP’19. Emphasis mine). It reminds me of ZeroMQ.
For each route we migrated, we wanted to make sure we were not introducing any regressions: either in the form of missing (or worse, wrong) data, or by increasing the latency of each endpoint. Being able to canary a new route let us verify latency and error rates were within acceptable limits. This meant that data that was static (e.g.
Uploading and downloading data always come with a penalty, namely latency. It is worth pointing out that cloud processing is always subject to variable network conditions. Doing so has the added advantage of being able to design and tune the enhancement to suit the requirements of packager and our other encoding applications.
ITOps refers to the process of acquiring, designing, deploying, configuring, and maintaining equipment and services that support an organization’s desired business outcomes. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. If you use AWS cloud services to build and run your applications, you may be familiar with the AWS Well-Architected framework.
This network connection heterogeneity made choosing a single delivery model difficult. Scaling Policies To address the thundering herd problem and to keep latencies under acceptable thresholds, the cluster scale-up policies are configured to be more aggressive than the scale-down policies.
You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. You can eliminate the latency issues caused by cold starts — an increase in normal response time when a new instance receives its first request — by using edge-optimized functions that run code closer to users and other projects.
To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability. In our case, we value low latency — the faster we can read from KeyValue, the faster these messages can get delivered.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Isolated parts of the database can serve read/write requests in case of network partition. Read/Write latency. Data Placement.
By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Increased latency during peak loads. Inconsistent network performance affecting data synchronization. Managing data residency while leveraging global edge networks.
When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN. Fault Tolerance If the underlying KafkaConsumer crashes due to ephemeral system or network events, it should be automatically restarted. million elements.
With DEM solutions, organizations can operate over on-premise network infrastructure or private or public cloud SaaS or IaaS offerings. STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables).
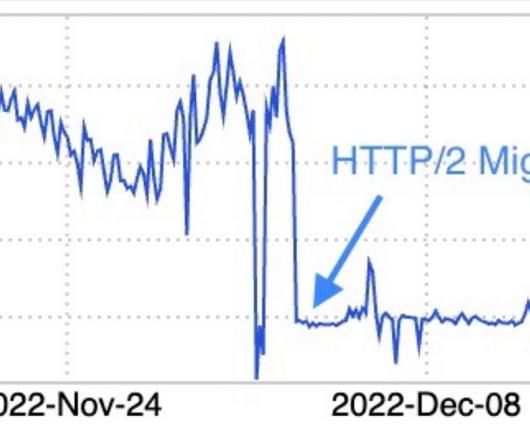
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. We explore all the systems necessary to make and stream content from Netflix.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. Transparency to end-users.
We often forget or take for granted the network hops involved and the additional overhead it creates on the overall performance. TCP/IP connection, triggered me to write about other aspects of network impact on performance. How to detect and measure the impact There is no easy mechanism for measuring the impact of network overhead.
In this blog, we will discuss both data and network-level compression offered in MongoDB. We will discuss snappy and zstd for data block and zstd compression in a network. By default, MongoDB provides a snappy block compression method for storage and network communication. I am using PSMDB 6.0.4
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Metrics for each service instance are presented in detailed charts—see the example for ECS below.
To meet user-defined goals for performance (request latency) and cost, the monitoring service tracks and adjusts resources to workload changes. This increases the cores and network bandwidth available to serve common requests. In order to implement these mechanisms, we had to make two significant changes to the design of Anna.
The pool of resources, at this time, is the CPU, memory, and networking resources of Amazon EC2 instances as partitioned by containers. networks ports, memory, CPU, etc). To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures.
We will share how its design has evolved over the years and the lessons learned while building it. To understand Axion’s design, we need to know the various components that interact with it. The motivation has not changed since then; the design has. Design evolution Axion fact store has four components?—?fact
A few years ago, we decided to address this complexity by spinning up a new initiative, and eventually a new team, to move the complex handling of user and device authentication, and various security protocols and tokens, to the edge of the network, managed by a set of centralized services, and a single team.
Each bare-metal instance is in a separate rack by design (for fault tolerance). The post Cross rack networklatency in AWS appeared first on n0derunner. The bandwidth is 25GbE however, the response time between the hosts is so high that I need multiple streams to consume that bandwidth.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Metrics for each service instance are presented in detailed charts—see the example for ECS below.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. Similarly, an increased throughput signifies an intensive workload on a server and a larger latency.
With insights from Dynatrace into networklatency and utilization of your cloud resources, you can design your scaling mechanisms and save on costly CPU hours. Dynatrace provides out-of-the-box support for VMware, AWS, Azure, Pivotal Cloud Foundry, and Kubernetes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content