This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Component Design. API Design. We have provided the API design of posting an image on Instagram below. API Design. Problem Statement. Architecture. Fetching User Feed.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? Where Does CrUX’s RTT Data Come From?
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
It involves a combination of techniques and best practices aimed at reducing latency, improving user experience, and increasing the overall efficiency of the system. API performance optimization is the process of improving the speed, scalability, and reliability of APIs.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
Remote calls are never free; they impose extra latency, increase probability of an error, and consume network bandwidth. How can we achieve a similar functionality when designing our gRPC APIs? When we process a request it is often beneficial to know which fields the caller is interested in and which ones they ignore.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Why Use Spring WebFlux?
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers. While clustering across wide-area networks (WANs) is discouraged due to latency issues, leased links can mitigate some connectivity challenges.
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. When we talk about downloading files, we—generally speaking—have two things to consider: latency and bandwidth. It gets worse.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets.
The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency. Our service will be used by a lot of internal UI applications hence the latency for CRUD and search operations must be low. Search latency for the generic text queries are in milliseconds.
We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases. We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles.
Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. We designed experimental scenarios inspired by chaos engineering. This significantly increases event latency. Recovery time of the throughput metric.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? How can we design systems that recognize these nuances and empower every title to shine and bring joy to ourmembers?
The circuit breaker is a design pattern that prevents cascading failures and improves the overall availability and performance of a system. A dependency can become unhealthy or unavailable for various reasons, such as network failures, high latency, timeouts, errors, or overload. What Is a Circuit Breaker?
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
Every new origin we need to visit needs a connection opening, and that can be very costly: DNS resolution, TCP handshakes, and TLS negotiation all add up, and the story gets worse the higher the latency of the connection is. On a slower, higher-latency connection, the story is much, mush worse. All completely avoidable. to just 3.6s.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
A typical design pattern is the use of a semantic search over a domain-specific knowledge base, like internal documentation, to provide the required context in the prompt. With these latency, reliability, and cost measurements in place, your operations team can now define their own OpenAI dashboards and SLOs.
The network latency between cluster nodes should be around 10 ms or less. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms network latency due to asynchronous data replication between regions. In the image below, three downed nodes make an entire cluster unavailable.
Uploading and downloading data always come with a penalty, namely latency. Figure 2: Cloud Resource and Job Sizes This initial architecture was designed at a time when packaging from a list of chunks was not possible and terabyte-sized files were not considered. thus making this design viable. at most few parts at a time?—?thus
Welcome back to the blog series in which we share how you can easily solve three common problem scenarios by using Dynatrace and xMatters Flow Designer. This is where xMatters Flow Designer comes into play, by automating remediation steps at the touch of a button. Step 5 – xMatters triggers a runbook in Ansible to fix the disk latency.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Monitors signals The first attribute of a good SLO is the ability to monitor the four “golden signals”: latency, traffic, error rates, and resource saturation. In practice, however, SLOs’ value varies significantly based on how teams design, deploy, and manage them.
To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability. In our case, we value low latency — the faster we can read from KeyValue, the faster these messages can get delivered.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The subsystems all communicate with each other asynchronously via Timestone, a high-scale, low-latency priority queuing system. Warm capacity.
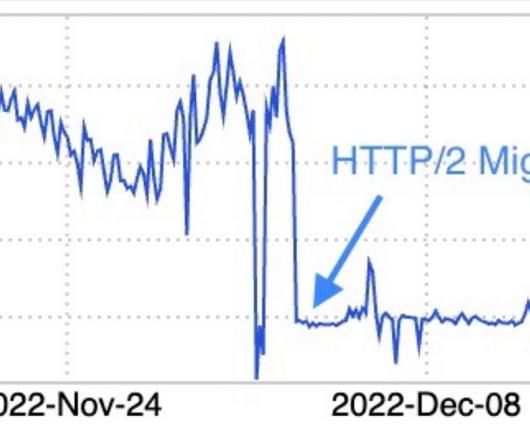
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. We started seeing increased response latencies and leader servers running at dangerously high utilization. The query rate in this test is set to 1K requests/second.
For each route we migrated, we wanted to make sure we were not introducing any regressions: either in the form of missing (or worse, wrong) data, or by increasing the latency of each endpoint. Being able to canary a new route let us verify latency and error rates were within acceptable limits. This meant that data that was static (e.g.
You can eliminate the latency issues caused by cold starts — an increase in normal response time when a new instance receives its first request — by using edge-optimized functions that run code closer to users and other projects. AWS continues to improve how it handles latency issues. It helps SRE teams automate responses.
As Google’s Ben Treynor explains , “Fundamentally, it’s what happens when you ask a software engineer to design an operations function.” Designating and managing Service Level Objectives (SLOs) as availability targets for a service. Reduced latency. Efficiency. Streamlined change management.
The Dynatrace Site Reliability Guardian is designed for this practice; it allows development teams to define quality objectives in their code, which is validated throughout the delivery process before the code reaches production. The queries are depicted below (sensitive data has been removed).
Our approach to NN-based video downscaling The deep downscaler is a neural network architecture designed to improve the end-to-end video quality by learning a higher-quality video downscaler. We employed an adaptive network design that is applicable to the wide variety of resolutions we use for encoding.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Amazon DynamoDB offers low, predictable latencies at any scale. Comments ().
Scaling Policies To address the thundering herd problem and to keep latencies under acceptable thresholds, the cluster scale-up policies are configured to be more aggressive than the scale-down policies. This approach enables the computing power to catch up quickly when the queues grow.
For production models, this provides observability of service-level agreement (SLA) performance metrics, such as token consumption, latency, availability, response time, and error count. Beyond SLAs, the emergence of machine learning technical debt poses an additional challenge for model observability.
Providing insight into the service latency to help developers identify poorly performing code. And UX designers can use that data to better understand how users interact with an application and how developers can streamline the interface. Want to learn more? There are also some limitations of real user monitoring.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content