This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
a contiguous chunk of data (typically 64 bytes on x86 systems) transferred to and from the cache. a usage pattern occurring when 2 cores reading from / writing to unrelated variables that happen to share the same L1 cache line. Cache line is a concept similar to memory page?—?a
Building resilient systems requires comprehensive error management. Errors could occur in any part of the system / or its ecosystem and there are different ways of handling these e.g. Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc.
In the realm of operating systems, the Real-Time Operating System (RTOS) stands out as a specialized player, tailored for applications where timeliness and determinism are paramount. An RTOS is an operating systemdesigned with a specific purpose in mind: to manage hardware resources and execute tasks within a stringent time frame.
Linux is a popular open-source operating system that offers various distributions to suit every need. While some distributions are aimed at experienced Linux users, there are distributions that cater to the needs of beginners or users with older hardware.
Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. Greenplum Architectural Design. What Exactly is Greenplum?
Development and designing are crucial, yet equally significant is making sure that you have developed the software product as per the necessities. Compatibility is the Non-Functional Requirement (NFR) and hence concentrates on delivering superior-quality and consistent performance.
When an application runs on a single large computing element, a single operating system can monitor every aspect of the system. Modern operating systems provide capabilities to observe and report various metrics about the applications running. Just as the code is monolithic, so is the logging.
Ransomware encrypts essential data, locking users out of systems and halting operations until a ransom is paid. Remote code execution (RCE) vulnerabilities, such as the Log4Shell incident in 2021, allow attackers to run malicious code on a remote system without requiring authentication or user interaction.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Simplicity.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Test tools are software or hardwaredesigned to test a system or application. Some test tools are intended for developers during the development process, while others are designed for quality assurance teams or end users.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional systemhardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
Five years ago when Google published The Datacenter as a Computer: Designing Warehouse-Scale Machines it was a manifesto declaring the world of computing had changed forever. The world is still changing, so Google published a new edition: The Datacenter as a Computer: Designing Warehouse-Scale Machines, Third Edition.
Teams can then act before attackers have the chance to compromise key data or bring down critical systems. This data helps teams see where attacks began, which systems were targeted, and what techniques attackers used. Proactive protection, however, focuses on finding evidence of attacks before they compromise key systems.
Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Save on costs for hardware and network bandwidth to optimize total cost of ownership. Take your time to prepare hardware, network and other infrastructure adjustments so you are ready. How it works.
A few months ago, I wrote the post " Amazon Aurora ascendant: How we designed acloud-native relational database ," and now I'm excited to share some news about the people behind the service.
IBM Z and LinuxONE mainframes running the Linux operating system enable you to respond faster to business demands, protect data from core to cloud, and streamline insights and automation. Dynatrace is designed to scale easily across the entire Kubernetes stack.
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
This shift is driven by the need for greater control over costs, data privacy, and system customization. This article explores the essential components of such infrastructure, focusing on the technical considerations for GPU-agnostic design, container optimization, and workload scheduling.
AWS Lambda enables organizations to access many types of functions from AWS’ cloud-based services, such as: Data processing, to execute code based on triggers, system states, or user actions. You will likely need to write code to integrate systems and handle complex tasks or incoming network requests.
Touch Design For Mobile Interfaces: Defining Mobile Devices (Excerpt). Touch Design For Mobile Interfaces: Defining Mobile Devices (Excerpt). Mobile phones are rapidly becoming touchscreens and touchscreen phones are increasingly all-touch, with the largest possible display area and fewer and fewer hardware buttons.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. The architects and developers who create the software must design it to be observed. Dynatrace news. Benefits of observability.
But what is the metric that shows service hardware monopolization by a group of users? Quality metrics contain: The ratio of successfully processed requests. Distribution of processing time between requests. Number of requests dependent curves. This metric absence reduces the quality and user satisfaction of the service.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. We want to extend the system to support CPU oversubscription. can we actually make this work in practice?
Cloud providers then manage physical hardware, virtual machines, and web server software management. Because a third party manages part of the infrastructure, IT teams give up a measure of control over system architecture. Consider a monolithic application, for example, designed to perform a host of functions.
Note that most of the changes we’ve introduced so far and those that are detailed below are all designed to be invisible to you, taking place entirely automatically in the background. However these improvements are of critical importance for those who have been exposed to the problems that these improvements are designed to solve.
Rendering is the final step in the VFX creation process, and processing on a render farm often can take several hours to complete just a single frame of a show, even when this process runs on the latest high-end hardware. Additionally, Conductor supports render management systems?—?including
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
As organizations train generative AI systems with critical data, they must be aware of the security and compliance risks. Likewise, with observability of systems that run AI models, organizations can predict and control costs, performance, and data reliability. Dive into the following resources to learn more.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. In fact, it can be difficult to make code changes that won’t disrupt the entire system.
An equally important aspect of this AI growth equation is the ever-expanding demands it places on computer system requirements to deliver higher AI performance. What’s more is that this AI performance boost driven by software optimizations is free, requiring almost no code changes or developer time and no additional hardware costs.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., Systems built with lots of microservices have different operational characteristics to those built from a small number of monoliths, we’d like to study and better understand those differences.
Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites.
Meet Touch Design For Mobile Interfaces, A New Smashing Book By Steven Hoober. Meet Touch Design For Mobile Interfaces, A New Smashing Book By Steven Hoober. Conventional computers now sport touchscreens and otherwise blur the lines between device types – and between mobile and desktop operating systems. Vitaly Friedman.
AV1 playback on TV platforms relies on hardware solutions, which generally take longer to be deployed. Throughout 2020 the industry made impressive progress on AV1 hardware solutions. While software decoders enable AV1 playback for more powerful devices, a majority of Netflix members enjoy their favorite shows on TVs.
This stems from a combination of Jevon’s paradox and the interconnectedness of systems – doing more in one area often leads to a need for more elsewhere too. At the end of the day, there are three basic ways we can increase capacity: Increasing the number of units in a system (subject to Amdahl’s law ). IDS/IPS requirements.
By Fabio Kung , Sargun Dhillon , Andrew Spyker , Kyle , Rob Gulewich, Nabil Schear , Andrew Leung , Daniel Muino, and Manas Alekar As previously discussed on the Netflix Tech Blog, Titus is the Netflix container orchestration system. It runs a wide variety of workloads from various parts of the company?—?everything
In the event of a primary server failure, standby servers are prepared to assume control, which helps reduce system downtime. They activate failover mechanisms designed to sustain high availability with minimal interruption. The primary server is responsible for handling all write operations and maintaining data accuracy.
Werner Vogels weblog on building scalable and robust distributed systems. Amazon Redshift and Designing for Security. Amazon Redshift can also be set up to encrypt all data at rest using hardware-accelerated AES-256. All data includes all data blocks, system metadata, partial results from queries and backups stored in S3.
Cloud computing has become a widely-used model of computing, as it offers a number of benefits over traditional, on-premises computing systems. This means that users only pay for the computing resources they actually use, rather than having to invest in expensive hardware and software upfront.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. System Setup Architecture The following diagram summarizes the architecture description: Figure 1: Event-sourcing architecture of the Device Management Platform.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Some disruption might occur, but it will be minimal. More in the following sub-section.)
Build evolvable systems. But we couldn’t adopt the old style approach of upgrading systems through a maintenance outage, as many businesses around the world are relying on our platform for 24/7 availability. This is a given, whether you are using the highest quality hardware or lowest cost components. Primitives not frameworks.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































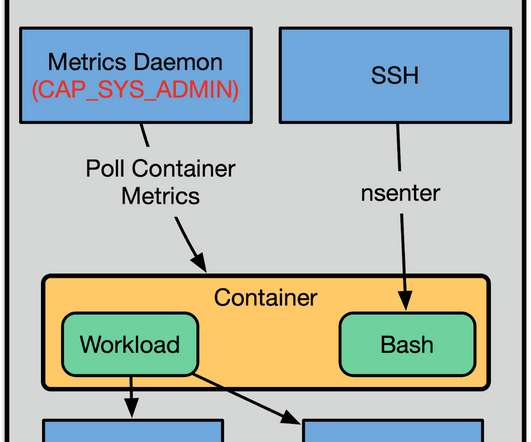












Let's personalize your content