This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Component Design. API Design. Problem Statement.
Non-compliance and misconfigurations thrive in scalable clusters without continuous reporting. The time has come to move beyond outdated practices and adopt solutions designed for the realities of Kubernetes environments. This empowers teams to efficiently deliver secure, compliant Kubernetes applications by design.
Have you ever wondered how large-scale systems handle millions of requests seamlessly while ensuring speed, reliability, and scalability? Behind every high-performing application whether its a search engine, an e-commerce platform, or a real-time messaging service lies a well-thought-out system design.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Design an instant messenger platform such as WhatsApp or Signal which users can utilize tosend messages to each other. This is a guest post by Ankit Sirmorya. Ankit is working as a Machine Learning Lead/Sr.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Design a location-based social search application similar to Tinder which if often used as a dating service. This is a guest post by Ankit Sirmorya. Ankit is working as a Machine Learning Lead/Sr. Problem Statement.
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. In response to this shift, platform engineering is growing in popularity. Why is platform engineering important?
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. This is a guest post by Ankit Sirmorya. Ankit is working as a Machine Learning Lead/Sr. Ankit has been working on applying machine learning to solve ambiguous business problems and improve customer experience.
This thoughtful approach doesnt just address immediate hurdles; it builds the resilience and scalability needed for the future. Challenge: Dont understand the cascading effects of their setup on these perceived black box personalization systems - Personalization System Engineers Role: Develop and operate the personalization systems.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. Different types of search queries are supported using the Elasticsearch as a backend search engine. As an example, the label can be ‘shower curtain’.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Design a video streaming platform similar to Netflix where content creators can upload their video content and viewers are able to play video on different devices. This is a guest post by Ankit Sirmorya. Problem Statement.
Although Dynatrace has its headquarters in Massachusetts and is publicly traded on the New York Stock Exchange ( NYSE:DT ), the epicenter of product design and creation is in Linz, Austria, where the company was founded in 2005. Key to this recognition as a uniquely global company is an agile and scalable approach to creativity.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. These practices are commonly known as “ chaos engineering. ”
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. Recovery time of the latency p90.
We’re therefore excited to announce that Dynatrace has received the Amazon RDS Service Ready designation. Achieving this designation differentiates Dynatrace as an AWS Advanced Technology Partner with a product that is integrated with Amazon RDS and is generally available and fully supported. Next steps.
This standardization enhances adoption within the personalization stack, simplifies the system, and improves understanding and debuggability for engineers. They must also provide enough information for partner engineers to identify the problem with the underlying service in cases of system-level issues.
By Ricky Gardiner , Alex Borysov Background In our previous post , we discussed how we utilize FieldMask as a solution when designing our APIs so that consumers can request the data they need when fetched via gRPC. This solution is not scalable. What if we want to update more than one field and do it atomically in a single RPC?
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? Most backend engineering teams follow a process very similar to what is shown below. If so, we invite you to begin the interview process.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? How can we design systems that recognize these nuances and empower every title to shine and bring joy to ourmembers?
The Growth Engineering team is responsible for executing growth initiatives that help us anticipate and adapt to this change. In particular, it’s our job to design and build the systems and protocols that enable customers from all over the world to sign up for Netflix with the plan features and incentives that best suit their needs.
that offers security, scalability, and simplicity of use. are technologically very different, Python and JMX extensions designed for Extension Framework 1.0 Python code also carries limited scalability and the burden of governing its security in production environments and lifecycle management. Extensions 2.0 Extensions 2.0
A transformative journey into the realm of system design with our tutorial, tailored for software engineers aspiring to architect solutions that seamlessly scale to serve millions of users.
He designed the Merlin engine. No one knows Tom Mueller, even though Tom is the one currently designing a rocket that will put humans on Mars. ??????. Consume Explain the Cloud Like I'm 10 (35 nearly 5 star reviews). He's CTO of Propulsion. His name is Tom Mueller. Everyone knows Elon Musk. This way to more quotes.
The reality of the startup is that engineering teams are often at a crossroads when it comes to choosing the foundational architecture for their software applications. The allure of a microservice architecture is understandable in today's tech state of affairs, where scalability, flexibility, and independence are highly valued.
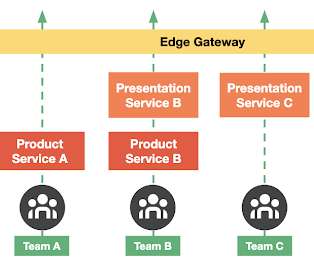
The making of Edge Gateway, the highly-available and scalable self-serve gateway to configure, manage, and monitor APIs of every business domain at Uber. In October 2014, Uber had started its journey of scale in what … The post Designing Edge Gateway, Uber’s API Lifecycle Management Platform appeared first on Uber Engineering Blog.
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. This setup prioritizes data safety, with most replicas online at any given time.
In this article, we discuss the concepts of dependability and fault tolerance in detail and explain how the Ably platform is designed with fault tolerant approaches to uphold its dependability guarantees. Fault tolerant design approaches address these shortfalls to provide continuity both to business and to the user experience.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Scalability. Finally, there’s scalability. The first benefit is simplicity. Let’s explore each in more detail. Compute services.
Because the device in question is a high-speed unit designed to process a high volume of ballots for an entire county, hacking just one of these machines could enable anattacker to flip the Electoral College and determine the outcome of a presidential election?. I used to comment sparingly. Comments tell you about the state, not the code.
Key insights from this shiftinclude: A Data-Centric Approach : Shifting focus from model-centric strategies, which heavily rely on feature engineering, to a data-centric one. This approach prioritizes the accumulation of large-scale, high-quality data and, where feasible, aims for end-to-end learning.
Performances testing helps establish the scalability, stability, and speed of the software application. Performance testing is mainly a subset of Performance engineering and is also referred to as ' Perf Tests.' Confirming scalability, dependability, stability, and speed of the app is crucial.
When we talk about conversational AI, were referring to systems designed to have a conversation, orchestrate workflows, and make decisions in real time. By predefined, tested workflows, we mean creating workflows during the design phase, using AI to assist with ideas and patterns. What Does Structured Automation Look Like in Practice?
It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. At a glance – TLDR.
Amazon’s new general-purpose Linux for AWS is designed to provide a secure, stable, and high-performance execution environment to develop and run cloud applications. Saving your cloud operations and SRE teams hours of guesswork and manual tagging, the Davis AI engine analyzes billions of events in real time.
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. Personalized Experience Refresh Netflix Recommendation engine continuously refreshes recommendations for every member.
Data Engineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “Data Engineers of Netflix” interview series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. The culture was also something that piqued my interest.
The goal was to develop a custom solution that enables DevOps and engineering teams to analyze and improve pipeline performance issues and alert on health metrics across CI/CD platforms. Faced with these requirements, Omnilogy carefully evaluated the following two options for implementing a solution to the pipeline observability challenge.
It's HighScalability time: Have a very scalable Xmas everyone! Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading). See you in the New Year. I'd really appreciate it.
SRE is the transformation of traditional operations practices by using software engineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Designating and managing Service Level Objectives (SLOs) as availability targets for a service.
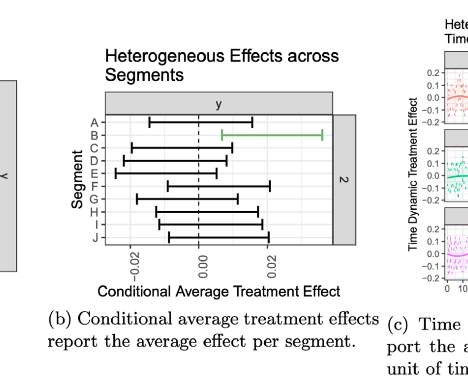
These methods can provide rich information for decision making, such as in experimentation platforms (“XP”) or in algorithmic policy engines. We want to amplify the effectiveness of our researchers by providing them software that can estimate causal effects models efficiently, and can integrate causal effects into large engineering systems.
Membership Engineering at Netflix is responsible for the plan and pricing configurations for every market worldwide. However, with our rapid product innovation speed, the whole approach experienced significant challenges: Business Complexity: The existing SKU management solution was designed years ago when the engagement rules were simple?—?three
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content