This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dynatrace introduced numerous powerful features to its Infrastructure & Operations app, addressing the emerging requirement for enhanced end-to-end infrastructure observability. These enhancements are designed to empower IT operations and SRE teams with more comprehensive visibility and increased efficiency at any time.
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
What began with an engineering plan to pave the path towards our first Live comedy special, Chris Rock: Selective Outrage , has since led to hundreds of Live events ranging from the biggest comedy shows and NFL Christmas Games to record-breaking boxing fights and becoming the home of WWE.
How to achieve sustainable IT practices Use observability tools The first step in driving improvements is to obtain a comprehensive view of your IT infrastructure’s climate impact. Platform engineers can set defaults for development teams, such as the number of replicas a service should have or whether it scales automatically.
Attracting over 20 million members each month, Tudum is designed to enrich the viewing experience by offering additional context and insights into the content available on Netflix. Client applications like web, mobile, and TV devices, act as rendering engines for SDUI data.
While infrastructure-level monitoring provides valuable insights, it might not reveal the root causes of database-related slowdowns. Query execution plans offer even more insights into how a database engine executes queries. Query execution plan Execution plans provide a roadmap for how the database engine executes queries.
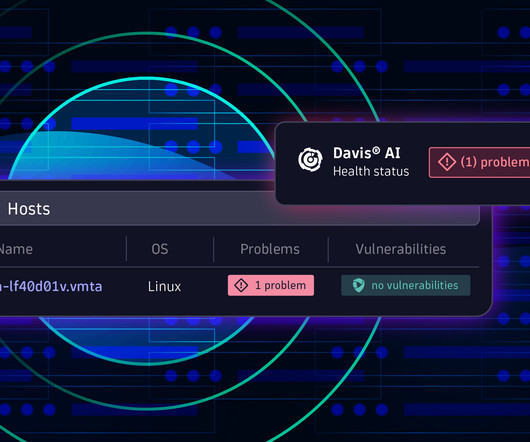
This latest integration with Microsoft Sentinel expands our partnership, providing joint customers with a holistic view of their entire cloud environment; from application to infrastructure, data, and security. “As The Davis AI engine automatically and continuously delivers actionable insights based on an environment’s current state.
This has been a guiding design principle with Metaflow since its inception. Subsequent versions of the model will result from experimenting with hyper parameters, tweaking feature engineering, or conducting feature diets. demo.branch_demox.demo_features_f workflows/demo.main.sch.yaml (binding=default): cluster=sandbox, workflow.id=demo.branch_demox.main
NVIDIA Blackwell systems provide high-performance infrastructure for enterprise AI, and now, thanks to the Dynatrace integration with the NVIDIA Enterprise AI Factory reference design, enterprises can add Dynatrace Full-Stack Observability to NVIDIA Blackwell infrastructure.
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Our Business Analytics solution is a prominent beneficiary of this commitment. Business process monitoring and optimization.
Key insights from this shiftinclude: A Data-Centric Approach : Shifting focus from model-centric strategies, which heavily rely on feature engineering, to a data-centric one. This approach prioritizes the accumulation of large-scale, high-quality data and, where feasible, aims for end-to-end learning.
The inherent latencies of data traveling across physical links, compounded by Internet infrastructure components like routers and network stacks, can disrupt a seamless viewing experience. Our custom-built servers, known as Open Connect Appliances (OCAs), are designed for both efficiency and cost-effectiveness.
Handling this surge is like facing a self-induced DDoS attack, and the question is: can your infrastructure handle the stampede or will it buckle under pressure? As a seasoned engineer might say, these mega-sale events are the ultimate scalability test. Smart design can ensure your system handles sudden load gracefully:
A slow-loading page, unexpected layout shifts, or unresponsive interactions can frustrate potential customerscausing higher bounce rates, abandoned carts, and low search engine rankings. To combat these issues, Google introduced Core Web Vitals (CWVs): a set of metrics designed to measure and improve the user experience of websites.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? How can we design systems that recognize these nuances and empower every title to shine and bring joy to ourmembers?
There are some crude keyword tags and summaries in the MCP server and eventually I asked Cursor/Claude to “Summarize the content related to platform engineering, including links to videos, medium posts etc.” The Evolution of Platform Engineering The journey from traditional operations to modern platform engineering has been remarkable.
Its PostgreSQL-native design ensures compatibility with popular extensions like PostGIS, making it highly versatile for modern use cases. It introduces a comprehensive set of features designed to empower high-performance distributed PostgreSQL: Real-time Sharding: Allows users to shard existing tables with live data and minimal downtime.
The pivoting queries concept allows engineers to quickly change the investigation context by switching the scope of a query using available pivoting dimensions. It’s designed for evidence-driven security use cases based on the logs, metrics, and traces ingested into the Dynatracer Grail® data lakehouse.
The concept of cloud sovereignty minimizing external dependencies and exerting full control over data, applications, and infrastructure has become a critical business imperative. Embrace sovereignty by design, powered by observability. PurePath is at the heart of the Dynatrace platforms DNA. group of companies.
Seamlessly monitor SAP systems with Dynatrace The latest version of the Dynatrace PowerConnect app for SAP Monitoring gives you a streamlined, intuitive experience thats designed to make SAP observability faster to provision and easier to use. This is achieved by leveraging standard capabilities of the Dynatrace platform to observe SAP.
They discuss how WAL addresses critical challenges like data loss, corruption, multi-partition mutations, and replication, showcasing its architecture and the strategic trade-offs considered for a resilient data infrastructure at Netflix's immense scale. By Prudhviraj Karumanchi, Vidhya Arvind
The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers. Configuring Quorum Queues Quorum queues in RabbitMQ are designed to maintain functionality as long as most replicas are operational.
This creates a whole new set of challenges that traditional software development approaches simply weren’t designed to handle. With the advent of generative AI, therell be significant opportunities for product managers, designers, executives, and more traditional software engineers to contribute to and build AI-powered software.
Matthew Liste, Head of Infrastructure at American Express, shared insights at QCon London 2025 on building robust cloud platforms in financial services. By Steef-Jan Wiggers
Tech services firms are instead applying AI to their own offerings to do things like accelerate the reverse-engineering of existing code and expedite forward engineering of new solutions. McKinsey last week posted a blog touting their proprietary AI platform for rejuvenating legacy infrastructure). Not the customers business.
Best for On-Premise Monitoring Zabbix for MySQL Agent-based tracking, configurable alerts, strong monitoring for in-house infrastructure. Tools like Paessler PRTG Network Monitor provide comprehensive solutions by combining database monitoring with broader IT infrastructure oversight.
I’ve known folks at CitSec for many years now (including some who participate in WG 21) and have long known it to be a great organization with some of the brightest minds in engineering and beyond. To all of those experts: Again, thank you !
Nothing is more discouraging than the idea that it will take tens of millions of dollars to train a model and billions of dollars to build the infrastructure necessary to operate it. What about computing infrastructure? Jevons paradox has a big impact on what kind of data infrastructure is needed to support the growing AI industry.
Refreshed look and feel The Dynatrace Community has long wished for a modern design, and thanks to the Dynatrace platform, its finally here. Analyzing status changes over time can exclude temporary infrastructure issues or find patterns. Once again, Extensions comes in handy. There is no easier way to enter it than by the front door.
This has serious implications for how we design, deploy, and govern AI systems across institutions, economies, and everyday life. Even with well-intentioned design, these systems can easily cross into overreach if they’re not built with human experience in mind. Fei-Fei doesn’t describe AI as a feature or even an industry.
Distributed systems are designed to improve performance, provide redundancy, and support scalability. Despite their complexity, distributed systems are designed to provide transparency to present a unified interface to users without exposing underlying intricacies. Automated alerts and failure recovery mechanisms are essential.
Essentially youre designing the interface that the AI will see. By documenting it, you also help AI prompt engineers know how to prompt the model. Theres active research and engineering going into making AI agents more reliable (techniques like better prompt chaining, feedback loops, or fine-tuning on tool use).
For organizations operating at global scale, Content Delivery Networks (CDNs) have become indispensable infrastructure for delivering fast, reliable user experiences. During high-traffic periods or after cache purges, this can create significant load on origin infrastructure, potentially leading to cascading performance issues or even outages.
Symptom Machine Learning engineer Luca Pozzi reported to our Data Platform team that their JupyterLab UI on their workbench becomes slow and unresponsive when running some of their Notebooks. Be part of shaping the future of Data Security and Infrastructure, Data Developer Experience, Analytics Infrastructure and Enablement, and more.
This is the kind of thing the terminal shows as it was coding the conciousness engine. Let me update my todo and spawn the agents: ● Update Todos ⎿ ☒ Read consciousness-engine-guide.md to understand requirements ☒ Analyze current project structure and dependencies ☐ Execute: work through plans/consciousness-engine-guide.md
New forms of interaction will take a long time to develop, and the improvements in infrastructure are dwarfed by the improvements in model efficiency. Persona answer: As I see it, the next major leap in AI will likely be driven by a combination of better models, new forms of human-AI interaction, and infrastructure innovation.
We no longer need to spend loads of time training developers; we can train them to be “prompt engineers” (which makes me think of developers who arrive on time), and they will ask the AI for the code, and it will deliver. As AI improves, it will probably even give you an answer that works. This is great!
Teams with thoughtfully designed data viewers iterate 10x faster than those without them. Their product manager, a learning design expert, would create detailed PowerPoint decks explaining pedagogical principles and example dialogues. Shed present these to the engineering team, who would then translate her expertise into prompts.
Our work focuses on the challenges that come with bringing PoCs to production, such as scaling AI infrastructure, improving AI system reliability, and producing business value. As Steve Yegge says, you have to demand that the AI writes code that meets your quality standards as an engineer.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Component Design. API Design. Problem Statement.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. A platform encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications.
a Netflix member via Twitter This is an example of a question our on-call engineers need to answer to help resolve a member issue?—?which Now let’s look at how we designed the tracing infrastructure that powers Edgar. Now let’s look at how we designed the tracing infrastructure that powers Edgar.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content