This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why manual audits and custom scripts fall short for Kubernetes security posture management In the dynamic and complex world of Kubernetes, relying on manual audits, custom scripts, and general-purpose security tools is no longer enough to achieve efficient security posture management. Processes are time-intensive. Reactivity.
This year’s AWS re:Invent will showcase a suite of new AWS and Dynatrace integrations designed to enhance cloud performance, security, and automation. These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services.
Business processes support virtually all aspects of an organizations operations. Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance.
In fact, observability is essential for shaping how we design smarter, more resilient systems for the future. Second, it enables efficient and effective correlation and comparison of data between various sources. At the same time, having aligned telemetry data is crucial for adopting OpenTelemetry at scale. OpenTelemetry Collector 1.0
In the landscape of computer architecture, two prominent paradigms shape the realm of parallel processing: SIMD (Single Instruction, Multiple Data) and MIMD (Multiple Instruction, Multiple Data) architectures. This approach enables efficientprocessing of large datasets by applying the same operation to multiple elements concurrently.
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source.
A production bug is the worst; besides impacting customer experience, you need special access privileges, making the process far more time-consuming. It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This cumbersome process should not be the norm.
This certification is specifically designed for Cloud Service Providers (CSPs) and builds upon the more generic approaches of ISO 27001 and SOC 2 Type II. Risk reduction : The certification process ensures that we have strong controls in place to mitigate security risks significantly, reducing the likelihood of breaches.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. This process can also be used to track the provenance of increments.
At financial services company, Soldo, efficiency and security by design are paramount goals. Since 2015, the Soldo business spend management platform has provided companies with a simple and efficient way to better spend and control company money. What is security by design?
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. The Business Flow app Business Flow, built with AppEngine, simplifies the configuration, monitoring, and analysis of business processes.
Protect data in multi-tenant architectures To bring you the most value by unifying observability and security in one analytics and automation platform powered by AI, Dynatrace SaaS leverages a multitenancy architecture, enabling efficient and scalable data ingestion, querying, and processing on shared infrastructure.
In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
This shift is driving increased adoption of the Dynatrace platform, as our customers leverage our unified observability solutionpowered by Grail, our hyperscale data lakehouse, designed to store, process, and query massive volumes of observability, security, and business data with high efficiency and speed.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers.
They offer a comprehensive end-to-end solution to these challenges, providing functionalities designed to enhance compliance and resilience in IT environments. Smartscape topology visualizes the relationships between applications, services, processes, hosts, and data centers, highlighting problems and vulnerabilities.
By integrating Dynatrace with GitHub Actions, you can proactively monitor for potential issues or slowdowns in the deployment processes. This awareness allows teams to allocate and scale resources more effectively, reducing costs while ensuring CI/CD pipelines operate smoothly and efficiently.
Energy efficiency has become a paramount concern in the design and operation of distributed systems due to the increasing demand for sustainable and environmentally friendly computing solutions.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
When we process a request it is often beneficial to know which fields the caller is interested in and which ones they ignore. How can we achieve a similar functionality when designing our gRPC APIs? This (alongside some other techniques like ZigZag encoding for signed types) makes protobuf messages space-efficient.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
It is designed for simplicity and cost-efficiency. Logs can also be transformed appropriately for presentation, for example, or further pipeline processing. Grafana Loki is a horizontally scalable, highly available log aggregation system. Loki can provide a comprehensive log journey.
API performance optimization is the process of improving the speed, scalability, and reliability of APIs. It involves a combination of techniques and best practices aimed at reducing latency, improving user experience, and increasing the overall efficiency of the system. What Is API Performance Optimization?
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Actions resulting from the evaluation The certification process surfaced a few recommendations for improving the app.
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. The request schema for the observability endpoint.
How can we design systems that recognize these nuances and empower every title to shine and bring joy to ourmembers? As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable. Yet, these pages couldnt be more different.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Such transformations can reduce storage costs by 99%.
To better guide the design and budgeting of future campaigns, we are developing an Incremental Return on Investment model. Ideally, we would have causal estimates from an A/B test to use for validation, but since that is not available, we use another causal inference design as one of our ensemble of validation approaches.
When building ETL data pipelines using Azure Data Factory (ADF) to process huge amounts of data from different sources, you may often run into performance and design-related challenges. This article will serve as a guide in building high-performance ETL pipelines that are both efficient and scalable.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers. At a glance – TLDR.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. For example, reporting jobs can process monthly data without running exactly at the end of the month. However, this trend is now reversing.
Ready-made dashboards and notebooks address this concern by offering pre-configured data visualizations and filters designed for common scenarios like troubleshooting and optimization. Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards.
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit was designed to help you adjust your data and add the proper context, which can be helpful in the observability backend. Ask yourself, how much data should Fluent Bit process?
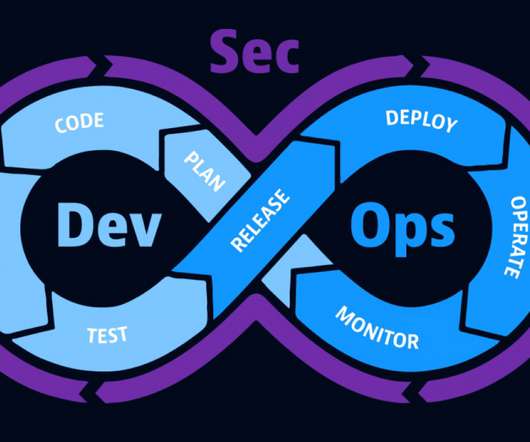
DevSecOps is a cross-team collaboration framework that integrates security into DevOps processes from the start rather than waiting to address security in a separate silo. DevOps has gained ground in recent years as a way to combine key operational principles with development cycles, recognizing that these two processes must coexist.
EdgeConnect facilitates seamless interaction, ensuring data security and operational efficiency. In this hybrid world, IT and business processes often span across a blend of on-premises and SaaS systems, making standardization and automation necessary for efficiency.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
A DevSecOps approach advances the maturity of DevOps practices by incorporating security considerations into every stage of the process, from development to deployment. DevSecOps best practices provide guidelines to help organizations achieve efficient and secure application design, development, implementation, and management.
In today’s rapidly evolving landscape, incorporating AI innovation into business strategies is vital, enabling organizations to optimize operations, enhance decision-making processes, and stay competitive. AI innovation elevates efficiency and performance of Google Cloud AI adoption is increasingly critical for any organization.
Across the globe, privacy laws grant individuals data subject rights, such as the right to access and delete personal data processed about them. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Using a low-code visual workflow approach, organizations can orchestrate key services, automate critical processes, and create new serverless applications.
Your companys AI assistant confidently tells a customer its processed their urgent withdrawal requestexcept it hasnt, because it misinterpreted the API documentation. When we talk about conversational AI, were referring to systems designed to have a conversation, orchestrate workflows, and make decisions in real time.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























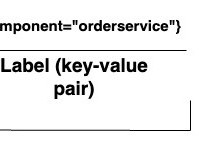

























Let's personalize your content