This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
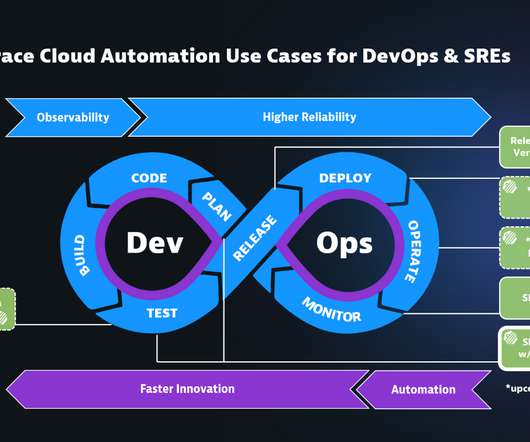
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Check out the on-demand Power Demo, Dynatrace and Business Observability: Tying IT Metrics to Business Outcomes. See observability in action! Watch webinar now!
Provide self-service platform services with dedicated UI for development teams to improve developer experience and increase speed of delivery. Open source logs and metrics take precedence in the monitoring process. The ability to effectively manage multi-cluster infrastructure is critical to consistent and scalable service delivery.
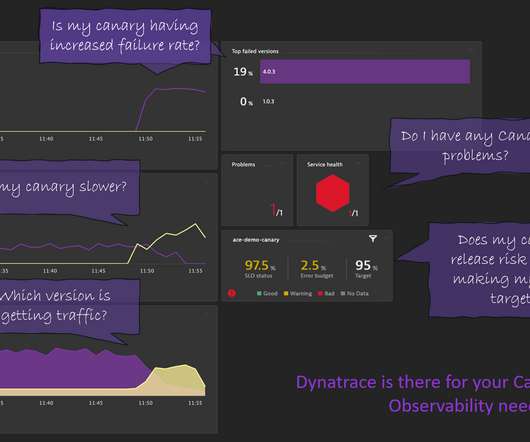
Progressive Delivery enables speeding up while managing the risk of software deployments and configuration changes. Having metrics with version information, e.g, Dynatrace news. One of the aspects of progressive delivery is using new zero-downtime deployment strategies such as Canary, Blue-Green, or Feature Flags. Step 3: SLOs.
Reducing downtime, improving user experience, speed, reliability, and flexibility, and ensuring IT investments are delivering on promised ROI across local IT stacks and in the cloud. ” Here, collecting metrics and monitoring performance help evaluate the efficacy of services rather than simply identifying their state.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. Read on below to explore all the benefits of Dynatrace monitoring by examining our demo Azure Functions application. Dynatrace news. See how everything works together—automatically.
These sets of tools are acquiring one or more different types of raw data (metrics, logs, traces, events, code-level details…) at various granularity, process them and create alerts (a threshold or learned baseline was breached, a certain log pattern occurred and so forth). Another huge advantage of that approach is speed.
Real user monitoring collects data on a variety of metrics. For example, data collected on load actions can include navigation start, request start, and speed index metrics. Real user monitoring works by injecting code into an application to capture metrics while the application is in use. How real user monitoring works.
Kubernetes was architected to allow for additional technologies and services to assist in speed, scalability and reducing the overall complexity which can arise from a Microservices environment. Today, most thought-leaders break down Observability into three pillars; metrics, distributed traces and logs.
With clear insight into crucial system metrics, teams can automate more processes and responses with greater precision. Logs are an essential part of the three fundamental pillars of observability : metrics, logs, and traces. More automation. Optimized system performance. How Dynatrace unlocks the value of log monitoring and analytics.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. Read on below to explore all the benefits of Dynatrace monitoring by examining our demo Azure Functions application. Dynatrace news. See how everything works together—automatically.
We have seen users who joined our preview program “speed up their release validation by 90%”. As the video alone shows you every step in detail, including live demos, I will just give you a high-level overview and the outcomes of the individual sections: Pre-requisite: Cloud Automation SaaS Tenant. 03:24 – Pre-Requisites.
Put another way, file-size savings help you to cram data into lower bandwidth, but if you’re latency-bound, the speed at which those admittedly fewer chunks of data arrive will not change. FCP feels like a real-world and universal enough metric to apply to any site, because that’s what people are there for—content.
Dynomite is a high-speed in-memory database, providing highly available cross datacenter replication while preserving Redis-like semantics. See our integration with Metrics later in this article.) We get it, and to help you with that initial setup, we have included a dockerized demo environment.
The Jenkins to Keptn integration was explained and demoed in one of our Performance Clinic videos; “. Environment interfaces include queries for topology, metrics, problems, and user sessions to name a few. These interfaces also allow toolchains to push problem comments, events, and metrics into Dynatrace for monitored entities.
Without such rules, configuring your environments can result in chaos, with losses in flexibility, speed, and stability. On the left are the set of specific metrics to be collected, known as Service level indicators (SLIs). To understand the setup for Quality Gates, refer to the picture below. SLIs can come from any data provider.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Get visibility into your production issues without juggling multiple tabs and different services -- all of your logs, server metrics and alerts are in your browser and at your fingertips.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Get visibility into your production issues without juggling multiple tabs and different services -- all of your logs, server metrics and alerts are in your browser and at your fingertips.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Get visibility into your production issues without juggling multiple tabs and different services -- all of your logs, server metrics and alerts are in your browser and at your fingertips.
Watch a demo and learn Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Get visibility into your production issues without juggling multiple tabs and different services -- all of your logs, server metrics and alerts are in your browser and at your fingertips.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Get visibility into your production issues without juggling multiple tabs and different services -- all of your logs, server metrics and alerts are in your browser and at your fingertips.
After this I spent almost 4 years working at Neotys, demos, proofs of concept, training people, the usual turf of a pre-sales engineer. Typically, in a 20 min OctoPerf demo we can record/replay/analyze a basic script. A lesson I always try to remember even today. Why did you decide to create OctoPerf? Neotys, Gatling, OctoPerf, Ubik….
Largest Contentful Paint (or LCP) is one of three metrics of the Core Web Vitals. These metrics are used by Google to evaluate the quality of user experience. The images used in the article’s Codepen demonstrations will be integrated with TwicPics to save time in their creation and speed up the optimization of the LCP metric.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Get visibility into your production issues without juggling multiple tabs and different services -- all of your logs, server metrics and alerts are in your browser and at your fingertips.
Web performance refers to the speed at which a website loads, how fast it’s downloaded, and how an app is displayed on the user’s browser. Key user-centric metrics often depend on the size, number, layout, and loading priority of images on the page. Fixes To Common Problems. The Benefits Of Using An Image Service CDN. Conclusion.
That's why we're very excited to introduce Hero Rendering Times, a set of new metrics for measuring the user experience. These metrics are available right now to SpeedCurve users. A brief history of UX metrics. Then Speed Index came along. Speed Index is based on measuring when visual content (e.g.,
Because the average page is now 3MB in size, and this seems like a good time to pause, check our assumptions, and ask ourselves: Is there any reason to care about page size as a performance metric? And if we don't consider page size a meaningful metric, then what should we care about? seconds) for pages in the 20MB cohort. seconds.
Kubernetes was architected to allow for additional technologies and services to assist in speed, scalability and reducing the overall complexity which can arise from a Microservices environment. Today, most thought-leaders break down Observability into three pillars; metrics, distributed traces and logs.
In this example, I'll be making changes to our demo site: Linking a site to a repository After you've installed the app, you'll need to link a site to your repository. This site is already monitoring the demo Home page. Scanning the metrics table, I see that Last Painted Hero is 7.3s, aligning with what I see in the filmstrip.
The benefits you are looking for are speed and sustainability. and business innovation speed plummets. Instead, you should adopt the DORA (DevOps Research and Assessment) metrics. These metrics show the reliability of your software systems. there is no compromise in quality when delivering at speed.
Request a highly-personalized demo to identify the scenarios that are causing the most immediate pain and enable the associated integration pattern. Once all tools are connected from end-to-end, you have a traceable and visible workflow that enables you to begin reporting and measuring performance through powerful Flow Metrics. .
The story was about a fast food chain that determined customer service was an important metric that they needed to track in some way. The AMP Project is reporting some rather significant improvements for publishers using the AMP pages: anywhere from 15-85% improvement in Speed Index scores when compared to the original article.
One of the huge benefits of tracking web performance over time is the ability to see trends and compare metrics. Understand which metrics got better or worse. Now let's walk through how to run a comparison and analysis using a real-world example from our "Top Sites" demo account. Test case: CNN. Time to dig deeper.
Delivering a fast, consistent online experience has been proven to measurably increase every metric retailers care about – from conversions and revenue to retention and brand perception. (In What you can do: Monitor the speed of your third parties. Live demo account > SpeedCurve Third Party Dashboard. Stylesheets.
This lets you see at a glance the relationship between page speed and user engagement. >> Demo: Interact with engagement charts in our live LUX demo account. We’ve created overlays that let you see the correlation between blocking JavaScript and CSS with your other metrics. Why you need them.
That’s why we built the Portfolio Insights Dashboard in Planview Tasktop Viz®: to give these leaders a way to drive systemic improvements and ensure problems aren’t disguised by local optimizations or proxy metrics. This card shows leaders the speed—or the Flow Time—of every product value stream in the portfolio so they can see two things:
We've been tracking these as individual metrics – Largest Contentful Paint, First Input Delay, and Cumulative Layout Shift – since before Google branded them as a set. Watch a demo video showing how to create custom charts and performance budgets for Web Vitals.). Industry speed benchmarks for Japan. Time period.
Modern Methods For Improving Drupal’s Largest Contentful Paint Core Web Vital Modern Methods For Improving Drupal’s Largest Contentful Paint Core Web Vital Mike Herchel 2023-08-15T10:00:00+00:00 2023-08-15T13:35:08+00:00 Let’s start with a fairly common example of a hero component on the homepage of Drupal’s demo installation of the Umami theme.
By integrating Atlassian Jira and Micro Focus ALM, you can automate the flow of defects between the two tools to eradicate manual overhead and accelerate the speed and accuracy of the defect reporting and resolution process. Long gone are the days when defect management was solely the concern of IT teams. Enhance product quality.
To do that, we focus on metrics that do a better job of revealing what the user's experience is really like. LUX's RUM metrics help you figure out which design and development improvements will make your users happier and your business more successful. You can see SpeedCurve RUM in action by viewing the LUX demo account.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content