This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
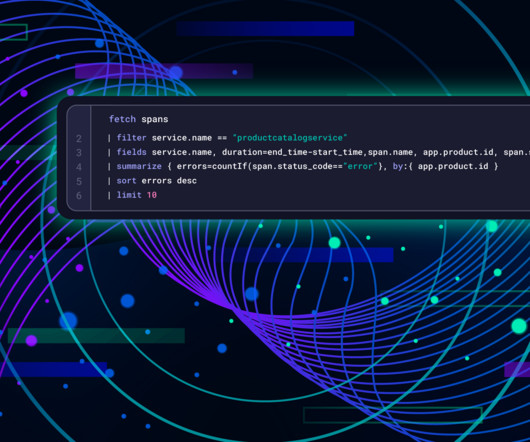
In this blog post, we’ll walk you through a hands-on demo that showcases how the Distributed Tracing app transforms raw OpenTelemetry data into actionable insights Set up the Demo To run this demo yourself, you’ll need the following: A Dynatrace tenant. If you don’t have one, you can use a trial account.
The OpenTelemetry community created its demo application, Astronomy Shop, to help developers test the value of OpenTelemetry and the backends they send their data to. Overview of the OpenTelemetry demo app dashboard Set up the demo To run this demo yourself, youll need the following: A Dynatrace tenant.
OpenTelemetry Astronomy Shop is a demo application created by the OpenTelemetry community to showcase the features and capabilities of the popular open-source OpenTelemetry observability standard. OTel Demo telescope image] The OpenTelemetry demo application is a cloud-native e-commerce application made up of multiple microservices.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. You’re gathering a lot of data, but you can’t make sense of it. What are histograms, and why use them?
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
The demo has been in active development since the summer of 2022 with Dynatrace as one of its leading contributors. The demo application is a cloud-native e-commerce application made up of multiple microservices. OpenTelemetry demo application architecture diagram. By default, the demo comes with?Jaeger OpenTelemetry?community
Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. You can see the actual command and args that were sub-processed in the Metaboost Execution section below. cluster=sandbox, workflow.id=demo.branch_demox.EXP_01.training
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
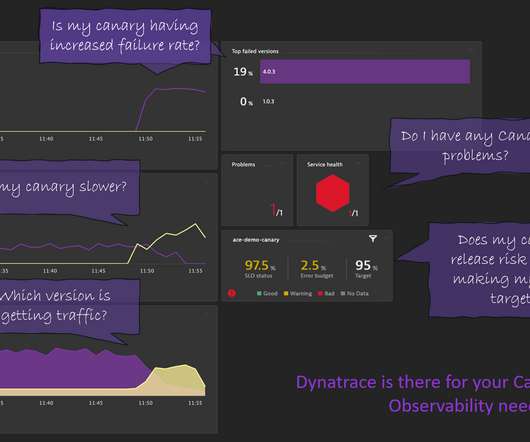
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. Dynatrace Davis , our deterministic AI, recently notified our teams about a problem in one of our Keptn instances we just recently spun up to demo our automated performance analysis capabilities orchestrated by Keptn. Dynatrace news.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
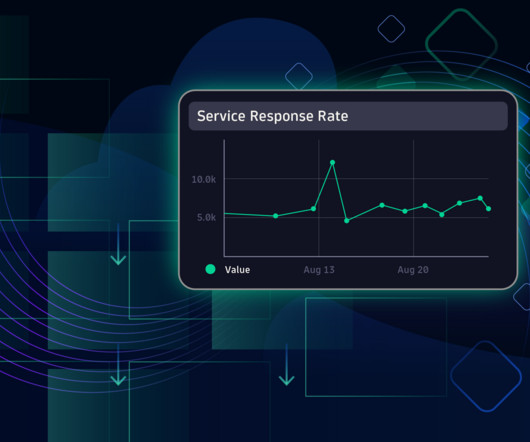
Dynatrace Dashboards provide a clear view of the health of the OpenTelemetry Demo application by utilizing data from the OpenTelemetry collector. Set up the Demo To run this demo yourself, you’ll need the following: A Dynatrace tenant. To install the OpenTelemetry Demo application dashboard, upload the JSON file.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
Keptn is currently leveraging Knative and installs Knative as well as other depending components such as Prometheus during the default keptn installation process. As I highlight the keptn integration with Dynatrace during my demos, I have rolled out a Dynatrace OneAgent using the OneAgent Operator into my GKE cluster.
Davis AI contextually aligns all relevant data points—such as logs, traces, and metrics—enabling teams to act quickly and accurately while still providing power users with the flexibility and depth they desire and need. How logs are ingested Dynatrace offers OpenPipeline to ingest, process, and persist any data from any source at any scale.
The ops team understood the concept of business metrics like NPS, conversions rates, even call center volume—but believed these KPIs were meant for other teams. Similarly, IT’s solid SLOs and Apdex scores—important metrics agreed upon by the app owner and IT—were met with a lack of enthusiasm by the business team.
Validation stage overview The validation stage is a crucial step in the CI/CD (Continuous Integration/Continuous Deployment) process. These prolonged processes not only strain resources but also introduce delays within the CI/CD pipeline, hampering the timely release of new features to end-users.
Monitoring , by textbook definition, is the process of collecting, analyzing, and using information to track a program’s progress toward reaching its objectives and to guide management decisions. Monitoring focuses on watching specific metrics. Here’s a closer look at logs, metrics, and distributed traces.
With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes. Ability to create custom metrics and events from log data, extending Dynatrace observability to any application, script or process.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. Why reliability?
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. Ensure expected production behavior One Dynatrace team is responsible for the demo applications we use to demonstrate Dynatrace capabilities.
Like general observability , AWS observability is the capacity to measure the current state of your AWS environment based on the data it generates, including its logs, metrics, and traces. These frameworks can include break-points/debuggers and logging instrumentation, or processes, such as manually reading log files. Watch demo now!
What about correlated trace data, host metrics, real-time vulnerability scanning results, or log messages captured just before an incident occurs? See for yourself Watch a demo of logs in context within various Dynatrace Apps in this Dynatrace University course. In the past, more work was needed to understand the context of log data.
Metrics, logs , and traces make up three vital prongs of modern observability. Together with metrics, three sources of data help IT pros identify the presence and causes of performance problems, user experience issues, and potential security threats. These two processes feed into one another.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Check out the on-demand Power Demo, Dynatrace and Business Observability: Tying IT Metrics to Business Outcomes. See observability in action! Watch webinar now!
The Local self-monitoring environment collects and aggregates all the self-monitoring metrics that are captured from the other environments on the cluster. For example, a cluster utilization of 50% should allow you to roughly double the currently processed load before the cluster reaches its maximum capacity. trace processing?provides
Getting the information and processes in place to ensure alerts like this example can be organizationally difficult. While you’re waiting for the information to come back from the teams, Davis on-demand exploratory analysis can proactively find, gather, and automatically analyze any related metrics, helping get you closer to an answer.
A full list of metrics can be found here and include dimensions such as the following: Packets. When it comes to logs and metrics, the Dynatrace platform provides direct access to the log content of all mission-critical processes. Log Metrics. Check out our Power Demo: Log Analytics with Dynatrace. Resource type.
Organizations that have transitioned to agile software development strategies (including the adoption of a DevOps culture and continuous delivery automation) enforce automated solutions for such decision making—or at the very least, use automation in the gathering of a release-quality metrics. Each entry represents a process group instance.
The second major concern I want to discuss is around the data processing chain. metrics) but it’s just adding another dataset and not solving the problem of cause-and-effect certainty. The four stages of data processing. Four stages of data processing with a costly tool switch.
To make it easier let me walk you through the things I have learned in this video so you can bring Dynatrace Cloud Automation to your progressive delivery process. Whether your processes run in a container on k8s, on a VM, or even in the mainframe you can follow the guideline in your doc on Version Detection. Step 3: SLOs.
Additional benefits from this new Amazon feature include the following: Customers can reduce operational overhead and easily process VPC Flow Logs by achieving the following: The offering eliminates dependencies on custom integrations. Check out our Power Demo: Log Analytics with Dynatrace. Learn more about VPC Flow Logs.
Observability is made up of three key pillars: metrics, logs, and traces. Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. Observability tools, such as metrics monitoring, log viewers, and tracing applications, are relatively small in scope.
During the booking process, I attempted to use some of my travel vouchers – but the button to apply these credits didn’t work. The hotel’s rental subsidiary limits their IT monitoring to internal system metrics, with no visibility into user journeys or business transactions. The unresponsive button problem has now been fixed.).
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Dynatrace users typically use extensions to pull technical monitoring data, such as device metrics, into Dynatrace.
Open source logs and metrics take precedence in the monitoring process. In addition, Dynatrace effortlessly collects crucial DORA metrics, SLOs, and business analytics data via its robust unified data platform, Dynatrace Grail™. Monitoring-as-code can also be configured in GitOps fashion. Say goodbye to high watermark pricing.
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
The platform automatically manages all the computing resources required in those processes, freeing up DevOps teams to focus on developing and delivering features and functions. Cloud Functions are ideal for creating backends, making integrations, completing processing tasks, and performing analysis. Image courtesy of Google.
In the past, setting up all the hosts, clusters, and demo applications was a manual process that was very time consuming and error-prone. You can see a similar automation process on this GitHub repo. Real-time charting for registrations, AWS infrastructure utilization, and network availability fed by AWS CloudWatch metrics.
During the booking process, I attempted to use some of my travel vouchers – but the button to apply these credits didn’t work. The hotel’s rental subsidiary limits their IT monitoring to internal system metrics, with no visibility into user journeys or business transactions. The unresponsive button problem has now been fixed.).
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. Expanding on the traditional observability pillars of metrics, logs, and traces, DEM collects user experience data to complete the end-to-end picture.
Logs can include data about user inputs, system processes, and hardware states. Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded. Log analytics is the process of evaluating and interpreting log data so teams can quickly detect and resolve issues.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content