This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we’ll walk you through a hands-on demo that showcases how the Distributed Tracing app transforms raw OpenTelemetry data into actionable insights Set up the Demo To run this demo yourself, you’ll need the following: A Dynatrace tenant. If you don’t have one, you can use a trial account.
The OpenTelemetry community created its demo application, Astronomy Shop, to help developers test the value of OpenTelemetry and the backends they send their data to. Overview of the OpenTelemetry demo app dashboard Set up the demo To run this demo yourself, youll need the following: A Dynatrace tenant.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. Histograms are commonly used to define and monitor service-level objectives (SLOs).
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
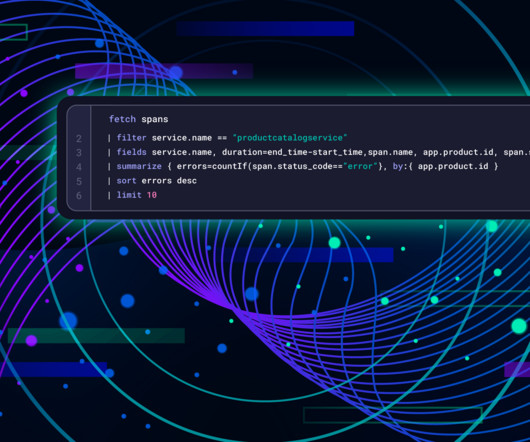
In the first part of this three-part series, The road to observability with OpenTelemetry demo part 1: Identifying metrics and traces with OpenTelemetry , we talked about observability and how OpenTelemetry works to instrument applications across different languages and platforms. api/v2/otlp/v1/traces'; $metricsURL = $baseURL. '/api/v2/otlp/v1/metrics';
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
Dynatrace Dashboards provide a clear view of the health of the OpenTelemetry Demo application by utilizing data from the OpenTelemetry collector. With these dashboards, you can monitor your application’s usage and performance and identify potential issues like increasing failure rates. The file can be downloaded here.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. Automate monitoring tasks.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. At Dynatrace we’re lucky to have Dynatrace monitor our workloads running on K8s. The post Kubernetes workload troubleshooting with metrics, logs, and traces appeared first on Dynatrace blog.
Real user monitoring can help you catch these issues before they impact the bottom line. What is real user monitoring? Real user monitoring (RUM) is a performance monitoring process that collects detailed data about a user’s interaction with an application. Real user monitoring collects data on a variety of metrics.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Production performance monitoring: Service uptime, service health, CPU, GPU, memory, token usage, and real-time cost and performance metrics.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. What is digital experience monitoring? Primary digital experience monitoring tools.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
Many of our customers—the world’s largest enterprises—have embraced the Dynatrace SaaS approach to monitoring, which provides critical business insights powered by AI and automation for globally-distributed, heterogeneous IT landscapes. New self-monitoring environment provides out-of-the-box insights and custom alerting.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Stage 2: Service monitoring.
As I highlight the keptn integration with Dynatrace during my demos, I have rolled out a Dynatrace OneAgent using the OneAgent Operator into my GKE cluster. Automated Metric Anomaly Detection. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. That’s another example where monitoring is of tremendous help as it provides the current resource consumption picture and help to continuously fine tune those settings. . Monitoring in the Kubernetes world .
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. Some use cases might benefit from isolated step metrics, but these are rare.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
Wouldn’t it be great if I had an industry-leading software intelligence platform to monitor these apps, pinpoint root causes of slow performance or errors, and gain insights about my users’ experience? At Dynatrace we live and breathe the concept of “Drink Your Own Champagne” (DYOC), so of course, I want to use Dynatrace to monitor my apps.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
As Dynatrace is a leader in Cloud monitoring, we have architected our Software Intelligence Platform specifically to complement Kubernetes by providing extensive functionality to tame the complexities and prevent performance issues that can occur across the development and deployment cycles. Don’t underestimate complexity.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell. So stay tuned!
The ops team understood the concept of business metrics like NPS, conversions rates, even call center volume—but believed these KPIs were meant for other teams. Similarly, IT’s solid SLOs and Apdex scores—important metrics agreed upon by the app owner and IT—were met with a lack of enthusiasm by the business team.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for all AWS services that publish metrics to Amazon CloudWatch, providing advanced observability for dynamic hybrid clouds. Dynatrace now monitors your AWS Outposts environment just like any AWS cloud Region. Next steps.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell. So stay tuned!
With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes. Next-gen Infrastructure Monitoring. Next up, Steve introduced enhancements to our infrastructure monitoring module.
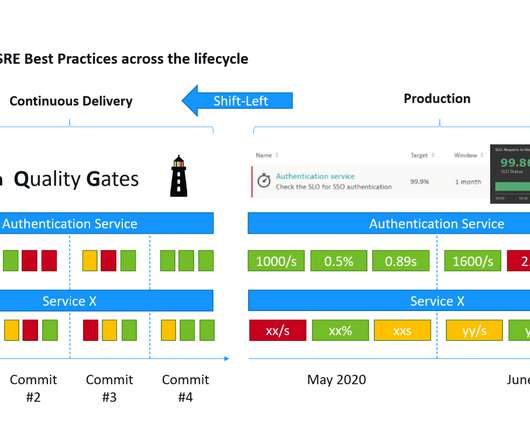
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. Why reliability? Your org’s challenge is to get ROI on those events.”
Logs provide answers, but monitoring is a challenge Manual tagging is error-prone Making sure your required logs are monitored is a task distributed between the data owner and the monitoring administrator. Often, it comes down to provisioning YAML configuration files and listing the files or log sources required for monitoring.
While an SLI is just a metric, an SLO just a threshold you expect your SLI to be in and SLA is just the business contract on top of an SLO. Thanks to its event-driven architecture, Keptn can pull SLIs (=metrics) from different data sources and validate them against the SLOs. class SRE implements DevOps) !
Unlike other monitoring tools on the market, which don’t provide AI-driven anomaly detection and alerting, Dynatrace delivers real-time data to track the status of all your runbooks and alerts you of any performance issues related to the jobs running in your Azure Automation service. Dynatrace news. Easily track the status of runbooks.
Metrics, logs , and traces make up three vital prongs of modern observability. Together with metrics, three sources of data help IT pros identify the presence and causes of performance problems, user experience issues, and potential security threats. Comparing log monitoring, log analytics, and log management.
Davis AI contextually aligns all relevant data points—such as logs, traces, and metrics—enabling teams to act quickly and accurately while still providing power users with the flexibility and depth they desire and need. Learn how Dynatrace can address your specific needs with a custom live demo.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Comprehensive observability is also essential for digital experience monitoring (DEM). Why full-stack observability matters. See observability in action!
How well do the IT departments for each of these companies monitor critical user journeys and business transactions? Based on my experience, here are my guesses: The airline IT team does not monitor user journeys. The rental car company monitors user journeys. BizOps maturity. Contact your account team to get started today.
Furthermore, a centralized Kubernetes management view offers extended centralized monitoring and alerting capabilities, particularly for node failure incidents. Additionally, users benefit from the Dynatrace Davis ® AI engine, which offers proactive monitoring capabilities like real-time tracking and alerting for critical health signals.
In 2015, the Spring folks already regarded Dynatrace as the gold standard for performance monitoring. Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Dynatrace users typically use extensions to pull technical monitoring data, such as device metrics, into Dynatrace.
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
A full list of metrics can be found here and include dimensions such as the following: Packets. When it comes to logs and metrics, the Dynatrace platform provides direct access to the log content of all mission-critical processes. Log Metrics. Check out our Power Demo: Log Analytics with Dynatrace. Resource type.
How well do the IT departments for each of these companies monitor critical user journeys and business transactions? Based on my experience, here are my guesses: The airline IT team does not monitor user journeys. The rental car company monitors user journeys. BizOps maturity. Contact your account team to get started today.
This view seamlessly correlates crucial events across all affected components, eliminating the manual effort of sifting through various monitoring tools for infrastructure, process, or service metrics. By using JavaScript and DQL, these dashboards can help generate reports on the current DORA metrics. What’s next?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content