This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. Why reliability?
Davis AI contextually aligns all relevant data points—such as logs, traces, and metrics—enabling teams to act quickly and accurately while still providing power users with the flexibility and depth they desire and need. Learn how Dynatrace can address your specific needs with a custom live demo.
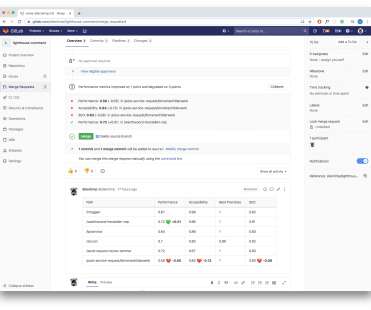
Ensure expected production behavior One Dynatrace team is responsible for the demo applications we use to demonstrate Dynatrace capabilities. We use monitored demo applications to deliver constant load and a defined set of business transactions. The queries are depicted below (sensitive data has been removed).
Monitoring focuses on watching specific metrics. Observability is the ability to understand a system’s internal state by analyzing the data it generates, such as logs, metrics, and traces. For example, we can actively watch a single metric for changes that indicate a problem — this is monitoring.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Observability can identify the baseline user experience and allow teams to improve it by optimizing page load times or reducing latency. See observability in action!
Today we are excited to announce latency heatmaps and improved container support for our on-host monitoring solution?—?Vector?—?to Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? to the broader community. Vector is open source and in use by multiple companies.
Real user monitoring collects data on a variety of metrics. For example, data collected on load actions can include navigation start, request start, and speed index metrics. Real user monitoring works by injecting code into an application to capture metrics while the application is in use. How real user monitoring works.
Observability is made up of three key pillars: metrics, logs, and traces. Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. Observability tools, such as metrics monitoring, log viewers, and tracing applications, are relatively small in scope.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. Expanding on the traditional observability pillars of metrics, logs, and traces, DEM collects user experience data to complete the end-to-end picture.
When an application is triggered, it can cause latency as the application starts. This creates latency when they need to restart. Your team should incorporate performance metrics, errors, and access logs into your monitoring platform. The platform builds the trigger to initiate the app. Monitoring serverless applications.
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
This is because file-size is only one aspect of web performance, and whatever the file-size is, the resource is still sat on top of a lot of other factors and constants—latency, packet loss, etc. FCP feels like a real-world and universal enough metric to apply to any site, because that’s what people are there for—content.
However, having a performance budget as a standalone metric might not be of much help. Anyone with a web presence would appreciate the relationship between the effect of various performance measures on business metrics. CDNs can alleviate last-mile latency, shorten a video’s start time, and potentially reduce buffering issues.
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity. For this demo on an old MacBook (2.7
SLIs are the actual performance metrics of your services. For example, if your SLO states that your uptime must be 99.9%, the actual SLI must meet or exceed that performance metric in order meet that specific SLO. An agreement within the SLA that states specific metric, like uptime, response time, security, issue resolution, etc.
This also includes latency, or the time it takes for data or a request to get through a network. The metrics measured could be monitoring HTTP (Hypertext Transfer Protocol) requests, response codes, user metrics, etc. On the flip-side, black-box monitoring is focused on server metrics like disk space, CPU, memory, load, etc.,
Time Theft: Using Flow Metrics to Expose Crimes from Conflicting Priorities and Unplanned Work. In this talk, Dominica reveals what you ought to know about Flow Metrics and how they can help you expose time theft so you can make better business decisions. Wednesday, June 26 at 2:10pm – Cutty Sark.
Modern Methods For Improving Drupal’s Largest Contentful Paint Core Web Vital Modern Methods For Improving Drupal’s Largest Contentful Paint Core Web Vital Mike Herchel 2023-08-15T10:00:00+00:00 2023-08-15T13:35:08+00:00 Let’s start with a fairly common example of a hero component on the homepage of Drupal’s demo installation of the Umami theme.
For each test, I captured the following metrics: First Paint (FP): To what extent is the critical path affected? I’m happy to say, for the metrics that matter the most, we are 700–1,200ms faster. Visually complete was 200ms faster , but any first- metrics were untouched. On a high-latency connection, this spells bad news.
Which metrics should I use?” Which values of these metrics are acceptable?”. The metrics selection is outside of the scope of this article and depends highly on the project context, but I recommend that you start by reading User-centric Performance Metrics by Philip Walton. Adding 20% to them and set as your next goals.
LogRocket tracks key metrics, incl. Getting Ready: Planning And Metrics Performance culture, Core Web Vitals, performance profiles, CrUX, Lighthouse, FID, TTI, CLS, devices. Getting Ready: Planning And Metrics. DOM complete, time to first byte, first input delay, client CPU and memory usage. Get a free trial of LogRocket today.
Getting Ready: Planning And Metrics. Getting Ready: Planning And Metrics. You need a business stakeholder buy-in, and to get it, you need to establish a case study, or a proof of concept using the Performance API on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Table Of Contents. Quick Wins.
Getting Ready: Planning And Metrics. Getting Ready: Planning And Metrics. You need a business stakeholder buy-in, and to get it, you need to establish a case study on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Table Of Contents. Setting Realistic Goals. Defining The Environment.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content