This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the promises of container orchestration platforms is to make i t easier for the developers to accelerate the deployment of their app lication s without having to worry about scalability and infrastructure dependencies. Monitoring in the Kubernetes world . L et’s look at some of the Day 2 operations use case s. .
Infrastructuremonitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructuremonitoring tools, which in many cases, just adds to the noise.
In this OpenTelemetry demo series, we’ll take an in-depth look at how to use OpenTelemetry to add observability to a distributed web application that originally didn’t know anything about tracing, telemetry, or observability. Observability may seem a fancy term, and it certainly does come with a fair share of complexity.
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. With public clouds, multiple organizations share resources.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. What is AWS observability? And why it matters. Amazon EC2.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
We also introduced our demo app and explained how to define the metrics and traces it uses. The second part, The road to observability with OpenTelemetry part 2: Setting up OpenTelemetry and instrumenting applications , covers the details of how to set up OpenTelemetry in our demo application and how to instrument the services.
Real user monitoring can help you catch these issues before they impact the bottom line. What is real user monitoring? Real user monitoring (RUM) is a performance monitoring process that collects detailed data about a user’s interaction with an application. Real user monitoring collects data on a variety of metrics.
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. First and foremost, it’s a data problem.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. Dynatrace combines Synthetic Monitoring with automatic release validation for continuous quality assurance across the SDLC.
Digital experience monitoring (DEM) allows an organization to optimize customer experiences by taking into account the context surrounding digital experience metrics. What is digital experience monitoring? Primary digital experience monitoring tools.
Many of our customers—the world’s largest enterprises—have embraced the Dynatrace SaaS approach to monitoring, which provides critical business insights powered by AI and automation for globally-distributed, heterogeneous IT landscapes. New self-monitoring environment provides out-of-the-box insights and custom alerting.
Gartner’s Top Emerging Trends in Cloud Native Infrastructure Report states, “Containers and Kubernetes are becoming the foundation for building cloud-native infrastructure to improve software velocity and developer productivity”. Don’t underestimate complexity. Kubernetes is not monolithic. Stand-alone observability won’t cut it.
Logs provide answers, but monitoring is a challenge Manual tagging is error-prone Making sure your required logs are monitored is a task distributed between the data owner and the monitoring administrator. Often, it comes down to provisioning YAML configuration files and listing the files or log sources required for monitoring.
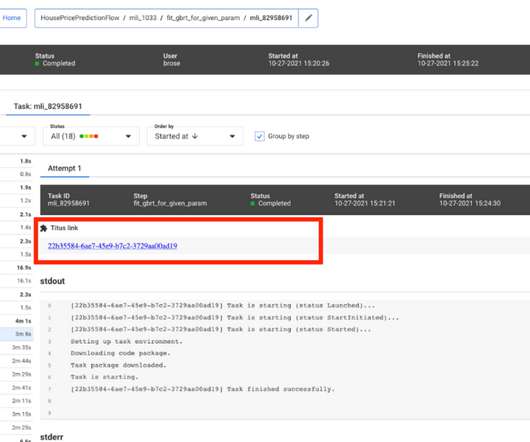
Open-Sourcing a Monitoring GUI for Metaflow, Netflix’s ML Platform tl;dr Today, we are open-sourcing a long-awaited GUI for Metaflow. The Metaflow GUI allows data scientists to monitor their workflows in real-time, track experiments, and see detailed logs and results for every executed task.
Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. Observability across the full technology stack gives teams comprehensive, real-time insight into the behavior, performance, and health of applications and their underlying infrastructure.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. The ability to effectively manage multi-cluster infrastructure is critical to consistent and scalable service delivery.
Hybrid, multi-cloud application and infrastructure environments can’t be siloed – visibility is needed for critical interdependencies. That’s why monitoring plays such a critical role in Azure environments. That’s why monitoring plays such a critical role in Azure environments. The post What is Azure?
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for all AWS services that publish metrics to Amazon CloudWatch, providing advanced observability for dynamic hybrid clouds. Dynatrace now monitors your AWS Outposts environment just like any AWS cloud Region. What is AWS Outposts? Next steps.
Next-gen InfrastructureMonitoring. Next up, Steve introduced enhancements to our infrastructuremonitoring module. Davis now automatically provides thresholds and baselining algorithms for all infrastructure performance and reliability metrics to easily scale infrastructuremonitoring without manual configuration.
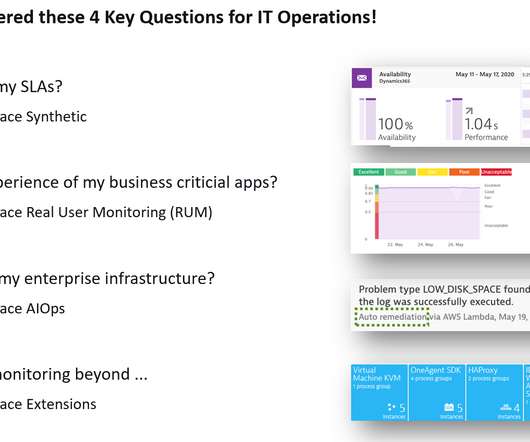
We came up with list of four key questions, then answered and demoed in our recent webinar. Stephan demoed how avodaq internally leverages Dynatrace Synthetic. In the demo, Stephan showed the waterfall view highlighting issues in connectivity, bad HTTP requests or even JavaScript errors.
Digital workers are now demanding IT support to be more proactive,” is a quote from last year’s Gartner Survey Understandably, a higher number of log sources and exponentially more log lines would overwhelm any DevOps, SRE, or Software Developer working with traditional log monitoring solutions.
Using environment automation from both AWS and Dynatrace, supported by the AWS Infrastructure Event Management program , Dynatrace University successfully delivered the required environments – these were three times more than the conference the year before. Perform 2020 Infrastructure Setup. Monitoring. Quite impressive!
No infrastructure to maintain. Because cloud providers own and manage back-end infrastructure, local IT teams aren’t responsible for ongoing maintenance and upgrades. Using off-site servers to deliver back-end infrastructure introduces security concerns. Difficult to monitor. Architectural complexity.
Likewise, operation specialists can prioritize their efforts on monitoring the highest-risk tactics, and executives can better communicate the business risk. In the following sections, we demo the following: Introduce Unguard, our insecure cloud-native microservices demo application.
Real-time monitoring with out-of-the-box features Real-time data and monitoring are crucial for maintaining situational awareness of IT environment stability and performance, especially during a crisis. They also enable companies to measure the effectiveness of their remediation activities to ensure that recoveries proceed as expected.
Dynatrace broadens its Digital Experience Monitoring capabilities by adding Flutter support. With the release of Flutter support in Dynatrace, we’re filling a gap that no other solution in the market has addressed, enabling you to leverage the full power of Dynatrace Digital Experience Monitoring for Flutter apps.
Most infrastructure and applications generate logs. While logging is the act of recording logs, organizations extract actionable insights from these logs with log monitoring, log analytics, and log management. Comparing log monitoring, log analytics, and log management. These two processes feed into one another.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for a wide range of AWS services. After discovering your AWS infrastructure, Dynatrace starts to monitor and analyze RDS database performance. All-in-one, AI-powered monitoring of AWS applications and infrastructure.
With Dynatrace, teams can seamlessly monitor the entire system, including network switches, database storage, and third-party dependencies. With this comprehensive monitoring, SREs can utilize holistic monitoring, where situational awareness and Davis® AI-based alerting transition from correlation to causation-based analysis.
For instance, in a Kubernetes environment, if an application fails, logs in context not only highlight the error alongside corresponding log entries but also provide correlated logs from surrounding services and infrastructure components. Learn how Dynatrace can address your specific needs with a custom live demo.
Cloud-hosted managed services eliminate the minute day-to-day tasks associated with hosting IT infrastructure on-premises. Monitoring serverless applications. Because serverless applications typically run in specialized environments, administrators worry about having adequate monitoring and observability capabilities.
To address this need, Dynatrace now provides automation for DevSecOps collaboration that associates ownership information with monitored services to further minimize mean-time-to-restore (MTTR). Associating ownership-team details with monitored services is flexible. team structure, or links to external resources such as a wiki.
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
The headlining feature of GCP is Google’s Compute Engine , a service for creating and running virtual machines in the Google infrastructure—a direct analog to AWS’ EC2 instances and Azure’s VMs. Observability and monitoring challenges with Google Cloud Functions. Curious to learn more? Watch webinar now!
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. At Dynatrace we’re lucky to have Dynatrace monitor our workloads running on K8s. Engineering Blogs from Thomas Schütz on Infrastructure and App deployment automation and Redesigning Microservice deployment strategies.
Infrastructure as code (IaC) configuration management tool. Monitor the project to gain valuable insights on user interactions, user response, and overall success of the project. Issue tracking system to manage issues, trigger workflows, and track code changes. Open source automated browser and testing tool. Amazon Web Services (AWS).
Dynatrace log monitoring also allows you to automate your cloud-related log tasks so you can accomplish the following: Automatically see precise root cause in real time to simplify cloud complexity. The newly introduced VPC Flow Logs for Transit Gateway service brings a new network dimension to application monitoring. Conclusion.
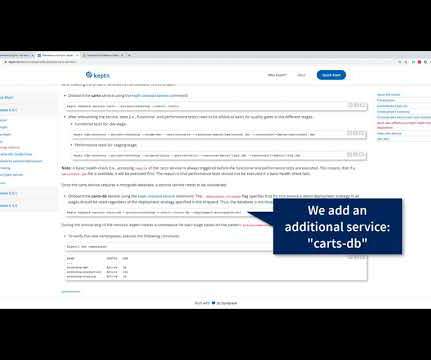
Some problems occur due to change in load patterns in production, an issue of the infrastructure or because of problems with individual features that are enabled through feature flagging frameworks. To add auto-remediation to your Keptn project simply follow the use case instructions for Self-Healing with Keptn or watch the following video.
Monitoring digital experiences has become increasingly critical for organizations to maintain their competitive edge. One advantage of digital experience over physical interaction is the tooling and technologies that are available to monitor and potentially improve the experience for your users. What is digital experience monitoring?
Today, Dynatrace is recognized as a Leader in the 2022 Gartner Magic Quadrant for Application Performance Monitoring and Observability.¹ This means customers can monitor and visualize with context how those new services affect their ecosystem and deliver the value they expect. Check out our Power Demo: Log Analytics with Dynatrace.
You need to go deeper into the stack — into the infrastructure itself. Also, via management zones , users can view security and performance data based on monitored entities, like a certain cluster, or even specific workloads. For more information visit our web page and watch the demo or read my Application Security blog.
This view seamlessly correlates crucial events across all affected components, eliminating the manual effort of sifting through various monitoring tools for infrastructure, process, or service metrics. It incorporates the automatic discovery of newly generated compute resources and any static resources that are in play. What’s next?
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Mobile apps, websites, and business applications are typical use cases for monitoring. APM can be referred to as: Application performance monitoring.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content