This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we’ll walk you through a hands-on demo that showcases how the Distributed Tracing app transforms raw OpenTelemetry data into actionable insights Set up the Demo To run this demo yourself, you’ll need the following: A Dynatrace tenant. If you don’t have one, you can use a trial account.
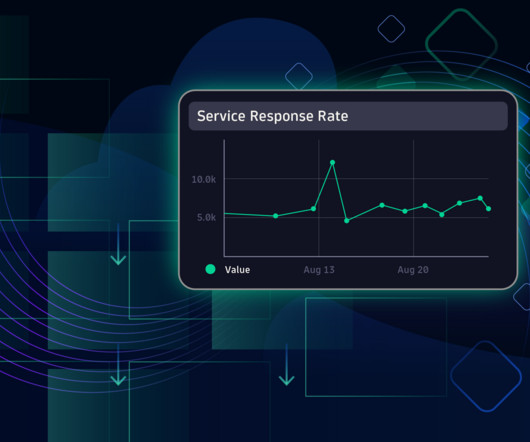
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. You’re gathering a lot of data, but you can’t make sense of it. What are histograms, and why use them?
Data Explorer “test your Metric Expression” for info result coming from the above metric. Following the previous metric (above) used for the SLO, the threshold employed is an average of 100 ms for the Key Performance Indicator (KPI) of DOM Interactive. Contact us for a free demo. Interested in learning more?
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. In a serverless architecture, applications are distributed to meet demand and scale requirements efficiently.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
This view seamlessly correlates crucial events across all affected components, eliminating the manual effort of sifting through various monitoring tools for infrastructure, process, or service metrics. By using JavaScript and DQL, these dashboards can help generate reports on the current DORA metrics. What’s next?
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Automation, automation, automation. See for yourself.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Metrics, logs , and traces make up three vital prongs of modern observability. Together with metrics, three sources of data help IT pros identify the presence and causes of performance problems, user experience issues, and potential security threats. This enables IT teams to quickly and efficiently find the answers they need.
With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes. Ability to create custom metrics and events from log data, extending Dynatrace observability to any application, script or process.
Receive alerts for any metric event in your Azure Automation account. This approach reduces errors, boosts efficiency, and ultimately lowers your operational costs. Receive alerts for any metric event in your Azure Automation account. Get full visibility into your Azure Automation accounts with one click.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Check out the on-demand Power Demo, Dynatrace and Business Observability: Tying IT Metrics to Business Outcomes. See observability in action! Watch webinar now!
A full list of metrics can be found here and include dimensions such as the following: Packets. When it comes to logs and metrics, the Dynatrace platform provides direct access to the log content of all mission-critical processes. Automate cloud operations and trigger remediation workflow to enhance efficiency. Log Metrics.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Dynatrace users typically use extensions to pull technical monitoring data, such as device metrics, into Dynatrace.
Dynatrace’s ingestion of logs also enables organizations to automate cloud-related log tasks by doing the following: automatically identifying the precise root cause of a problem in real time to simplify cloud complexity; automating cloud operations and triggering remediation workflow to enhance efficiency; and.
While you’re waiting for the information to come back from the teams, Davis on-demand exploratory analysis can proactively find, gather, and automatically analyze any related metrics, helping get you closer to an answer. Dynatrace can efficiently rote the problem to the teams that can solve it without disturbing anyone else.
Kubernetes is an open-source orchestration engine for containerized applications that help to automate processes such as scaling, deployments, and management with greater efficiency. . This service is a step forward to give users and adopters the tools they need to gain efficiency with automation. What is Amazon EKS?
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. Expanding on the traditional observability pillars of metrics, logs, and traces, DEM collects user experience data to complete the end-to-end picture.
Log analytics also help identify ways to make infrastructure environments more predictable, efficient, and resilient. With clear insight into crucial system metrics, teams can automate more processes and responses with greater precision. Together, they provide continuous value to the business. More automation. Accelerated innovation.
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
Some use cases might benefit from isolated step metrics, but these are rare. Learn more about how Dynatrace helps track, analyze, and optimize business processes to increase efficiency, reduce process errors, and improve customer satisfaction.
Dynatrace offers various out-of-the-box features and applications to provide a high-density overview of system health for all hosts and related metrics in a single view. Foundation and Discovery provide essential metrics and topology discovery, making it useful to quickly identify and recover affected hosts.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. ” Here, collecting metrics and monitoring performance help evaluate the efficacy of services rather than simply identifying their state. Dynatrace news.
Inevitably, this leads to one very important question addressing the efficiency of ML: can such an AI ever keep up with frequent changes and deployments? metrics) but it’s just adding another dataset and not solving the problem of cause-and-effect certainty. Lost and rebuilt context. This is now the starting node in our tree.
Because of everything that can go wrong, it’s imperative for organizations to constantly track metrics that indicate user satisfaction and have a robust complaint resolution model in place. Without agreeing on the single source of truth, you’ll end up in meetings arguing about metrics instead of helping your users.
Real user monitoring collects data on a variety of metrics. For example, data collected on load actions can include navigation start, request start, and speed index metrics. Real user monitoring works by injecting code into an application to capture metrics while the application is in use. How real user monitoring works.
It also provides tools to view the storage layout on disk; browse the supported sample queries (to help design efficient point queries); guide you through the process of choosing a compaction strategy, and many other advanced settings. See our integration with Metrics later in this article.)
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Because the scope of these solutions is limited by their nature, they also tend to create silos in which teams can disagree on service-level objectives (SLOs) and metrics.
Flow : How efficient are you at delivering value to customers? SAFe’s adoption of Flow Metrics —from Dr. Mik Kersten’s Flow Framework® —helps leadership focus on establishing clear goals and removing obstacles for teams, equipped with the feedback that Flow Metrics provides. What are the delays and wait times slowing us down?
Images are crucial elements for performance and UX, and data extracted from Core Web Vitals metrics such as Largest Contentful Paint , which attempts to identify the most important piece of the above-the-fold content on a given page, proves this. Serve In Next-generation (Next-gen) Formats, Encode Efficiently. demo-image.jpeg.
Making sense of your data: With so much variability in the way teams capture, organize and manage their work in multiple systems of record, it can be exceedingly hard to create meaningful metrics without a lot of manual data manipulation.
You will worry that they are wasting time or not working efficiently. Instead, you should adopt the DORA (DevOps Research and Assessment) metrics. Equally importantly, more frequent software deployments indicate that software development teams have an efficient process and a high quality codebase that can easily be changed?—?a
SLIs are the actual performance metrics of your services. For example, if your SLO states that your uptime must be 99.9%, the actual SLI must meet or exceed that performance metric in order meet that specific SLO. An agreement within the SLA that states specific metric, like uptime, response time, security, issue resolution, etc.
That was a technical demo of another rempl tool made by Roman Dvornov. It might not be completely efficient if we use modules in raw form, as they are in the file system: there might be some doubles, some modules could be combined, and others are only partially used. We can import information from our metric storage into data.
The interconnections between nodes and the rest of the system makes it possible to communicate and share data efficiently. The metrics measured could be monitoring HTTP (Hypertext Transfer Protocol) requests, response codes, user metrics, etc. Reliability. Another key benefit of distributed systems is reliability.
Watch this demo of an Asana, LeanKit, and Jira integration to see how Product Managers, Project Managers, and Developers can all stay in their preferred tools but still maintain a global view of all departments’ progress. We want to tell you about three UI improvements in Hub that will make you more efficient and save you some time.
I asked around and heard that they are still working on it, but the AWS hiring freeze means that they don’t have the headcount they expected and are making slow progress on an API, more detailed metrics, and scope 3, which everyone is waiting for. Portfolio is currently reducing Amazons carbon footprint by 19 Million Metric Tons of CO2e.
SUS101: Sustainability innovation in AWS Global Infrastructure AWS is determined to make the cloud the cleanest and most energy-efficient way to run customers’ infrastructure and business. This includes providing the efficient, resilient services AWS customers expect, while minimizing their environmental footprint.
By assessing whether users are able to successfully complete the task (along with additional metrics, such as number of clicks, time on task, and more), we are able to identify which areas of the feature are most in need of focus and UX improvements.
A custom date range was added to Integration Metrics, in addition to the quick-select options of 30, 60 and 90 days. . Request a highly personalized demo and/or have your value stream architecture mapped by one of our Value Stream Architects to see how Tasktop can help you generate more business value from your software products.
was released today to make enterprise-grade integration as easy, efficient and impactful as possible, with some exciting new features including: Read-only role for troubleshooting. Tasktop Integration Hub version 19.4 A visual cue to highlight what environment you’re viewing. More enhancements to artifact filtering.
These excellent tools are built for purpose, such as planning, design, development, testing, service desk and so on, and enable specialists teams to do their jobs more efficiently and collaboratively. In doing so, you will also enable all teams to work in their tool of choice, allowing a best-of-breed approach to flourish. . Learn more.
Check out the demo version of PHPDocumentor 2 to see the selection of new and improved PHP templates. Retrace Retrace is a performance monitoring tool with an excellent error tracking feature to help you identify exceptions and address bugs quickly and efficiently. Best PHP Performance Monitoring Tools 1.
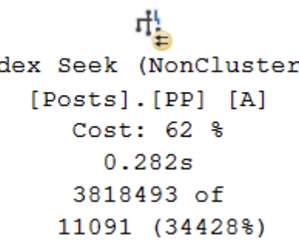
Batch operators are implemented so that multiple threads can work efficiently on a single shared structure (e.g. How row mode metrics are collected. The second part of the puzzle relates to the way row count and timing metrics are collected in row mode plans. hash table).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content