This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
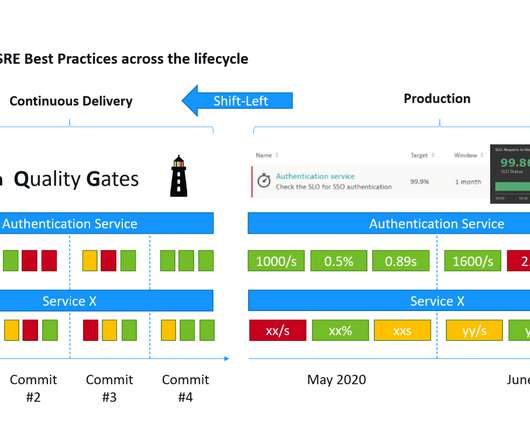
This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates. Dynatrace news.
The demo has been in active development since the summer of 2022 with Dynatrace as one of its leading contributors. The demo application is a cloud-native e-commerce application made up of multiple microservices. OpenTelemetry demo application architecture diagram. By default, the demo comes with?Jaeger OpenTelemetry?community
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. But there is a lack of time for DevOps , SRE , and developers to analyze all this data to identify whether there’s a user impacting problem and if so – what the root cause is to fix it fast. Dynatrace news.
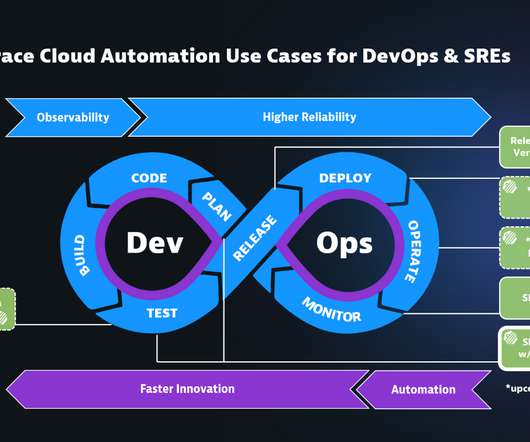
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. DevOps teams can also benefit from full-stack observability. With improved diagnostic and analytic capabilities, DevOps teams can spend less time troubleshooting.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
Dynatrace enables various teams, such as developers, threat hunters, business analysts, and DevOps, to effortlessly consume advanced log insights within a single platform. DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Ensure that you get the most out of your product.
These examples can help you define your starting point for establishing DevOps and SRE best practices in your organization. Ensure expected production behavior One Dynatrace team is responsible for the demo applications we use to demonstrate Dynatrace capabilities. The queries are depicted below (sensitive data has been removed).
This view seamlessly correlates crucial events across all affected components, eliminating the manual effort of sifting through various monitoring tools for infrastructure, process, or service metrics. By using JavaScript and DQL, these dashboards can help generate reports on the current DORA metrics. What’s next?
Metrics, logs , and traces make up three vital prongs of modern observability. Together with metrics, three sources of data help IT pros identify the presence and causes of performance problems, user experience issues, and potential security threats. For context, teams collect metrics for further analysis and indexing.
Monitoring focuses on watching specific metrics. Observability is the ability to understand a system’s internal state by analyzing the data it generates, such as logs, metrics, and traces. For example, we can actively watch a single metric for changes that indicate a problem — this is monitoring.
A common challenge of DevOps teams is they get overwhelmed with too many alerts from their observability tools. DevOps teams don’t need just more noise—they need smarter alerting that is automatic, accurate, and actionable with precise root cause analysis. Demo: Add the human factor using the Dynatrace events API.
DevOps teams often use a log monitoring solution to ingest application, service, and system logs so they can detect issues at any phase of the software delivery life cycle (SDLC). With clear insight into crucial system metrics, teams can automate more processes and responses with greater precision. More automation.
Observability is made up of three key pillars: metrics, logs, and traces. Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. Observability tools, such as metrics monitoring, log viewers, and tracing applications, are relatively small in scope.
The Dynatrace Software Intelligence Platform already comes with release analysis, version awareness , and Service Level Objective (SLO) support as part of the Dynatrace Cloud Automation solution , helping DevOps and SRE teams automate the delivery and operational decisions. 01:19 – Introducing Shift-Left SLO Quality Gates.
Although GCF adds needed flexibility to serverless application development, it can also pose observability challenges for DevOps teams. The platform automatically manages all the computing resources required in those processes, freeing up DevOps teams to focus on developing and delivering features and functions. Curious to learn more?
Gone are the days for Christian manually looking at dashboards and metrics after a new build got deployed into a testing or acceptance environment: Integrating Keptn into your existing DevOps tools such as GitLab is just a matter of an API call.
The 2021 State of DevOps report found successful organizations enable application teams to set up and configure monitoring and alerting through self-service capabilities, removing the need for manual work from teams responsible for monitoring. For orientation on the use cases in this blog series, refer to the picture below. Try it yourself.
Organizations that have transitioned to agile software development strategies (including the adoption of a DevOps culture and continuous delivery automation) enforce automated solutions for such decision making—or at the very least, use automation in the gathering of a release-quality metrics. ” Get started.
In the past, setting up all the hosts, clusters, and demo applications was a manual process that was very time consuming and error-prone. True DevOps culture in action! Real-time charting for registrations, AWS infrastructure utilization, and network availability fed by AWS CloudWatch metrics. Automation. The results.
Accordingly, these platforms provide a unified, consistent DevOps and IT experience. Hybrid capabilities extend beyond what a private data center—and in-house IT and DevOps teams—can provide. The solution starts with observability, enabling organizations to measure the system states based on their logs, metrics, and traces.
The Jenkins to Keptn integration was explained and demoed in one of our Performance Clinic videos; “. Environment interfaces include queries for topology, metrics, problems, and user sessions to name a few. These interfaces also allow toolchains to push problem comments, events, and metrics into Dynatrace for monitored entities.
Used by organizations for everything from assigning support tickets to managing failover regimes, feature flags enable DevOps teams to release software faster and more reliably. Were SRE metrics impacted, such as response time, availability and throughput? Experience an OpenTelemetry-based in-browser demo of OpenFeature.
If you want to see a more hands-on approach, I encourage you to watch the recording as Stefano did a live demo of Akamas’s integration with Dynatrace, showing how to minimize the footprint of a Java application with automated JVM tuning. Akamas also enables you to automate the analysis of the experiment metrics in powerful ways.
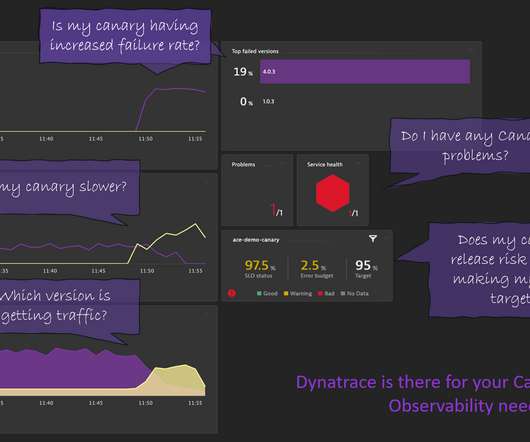
You can analyze hotspots for a particular transaction from a specific canary, you can create calculated metrics split by release version and use those metrics for dashboards or alerting: Version metadata is automatically available on each PurePath – enabling version-specific diagnostics, analytics, and alerting use cases. Step 3: SLOs.
Data Explorer “test your Metric Expression” for info result coming from the above metric. Following the previous metric (above) used for the SLO, the threshold employed is an average of 100 ms for the Key Performance Indicator (KPI) of DOM Interactive. Contact us for a free demo. Interested in learning more?
Using the EKS Blueprints framework offers many benefits, such as the following: Simplifies tool integration – EKS Blueprints simplifies running services that are a precursor for containerizing tools like CI/CD pipelines, log and metrics processing and security enforcement. . How Dynatrace covers Kubernetes check out our blog.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Stream is currently also hiring Devops and Python/Go developers in Amsterdam. View and analyze all your logs and system metrics from multiple sources in one place.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Stream is currently also hiring Devops and Python/Go developers in Amsterdam. View and analyze all your logs and system metrics from multiple sources in one place.
In one week’s time, thousands of IT and business professionals will descend on London for the latest iteration of DevOps Enterprise Summit London 2019 (June 25-27 – InterContinental O2, London, UK). designed to help attendees take their DevOps initiatives to the next level. . Tuesday, June 25 at 2:40pm – Arora 6&7.
Your team should incorporate performance metrics, errors, and access logs into your monitoring platform. It captures their metrics, logs, traces, and user experience data, and analyzes them in the context of their dependencies among other services and infrastructure. Bugs, security, and throttling related slowdowns are concerns.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Stream is currently also hiring Devops and Python/Go developers in Amsterdam. View and analyze all your logs and system metrics from multiple sources in one place.
Watch a demo and learn Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Stream is currently also hiring Devops and Python/Go developers in Amsterdam. View and analyze all your logs and system metrics from multiple sources in one place.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Stream is currently also hiring Devops and Python/Go developers in Amsterdam. View and analyze all your logs and system metrics from multiple sources in one place.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Those in the boardroom have just as much to gain from adopting APM solutions as those on the front lines of DevOps efforts. Dynatrace news. Application performance management.
Instead of presenting you with a handful of random screenshots from our demo environment I reached out to Robert, a close friend of mine, who leads a development team with the current task to re-architect and re-platform their multi-tenant SaaS-based eCommerce platform. MaaSS for Business: Data per SaaS-Tenant.
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Stream is currently also hiring Devops and Python/Go developers in Amsterdam. View and analyze all your logs and system metrics from multiple sources in one place.
Oh, and it just so happens that one of our favourite events of the year takes place too, providing the perfect opportunity for the DevOps community to come together: The virtual DevOps Enterprise Summit, Europe (18-20 May 2021). . OKRs & DevOps: From Micromanagement Misery to Finding Flow. Daily Coffee Break Live Demos.
However, October also brings one of our favorite events of the year: The DevOps Enterprise Summit , Las Vegas (13-15 October). Events have gone virtual, and sadly meeting the DevOps community face-to-face is on hold for now. Live Demos. Tasktop has three live demos scheduled during the event. Conference Sessions.
For us, it’s all about participating in one of our favorite events of the year — DevOps Enterprise Summit 2019. Mik Kersten launched his Amazon best-selling book Project to Product and the pioneering the Flow Framework —we come bearing gifts (and the latest empirical knowledge) to help attendees with their DevOps transformation.
Tasktop integrated the organization’s ITSM tool— ServiceNow —to its Agile development tools— Atlassian Jira and Microsoft Azure DevOps —to optimize its ability to resolve users’ problems faster across all systems. Some teams use Jira, and others use Azure DevOps depending on the product value stream.
Like DevOps, these SRE principles serve as a guide to drive alignment as it relates to aligning, meeting, and supporting the goals of the organization. SLIs are the actual performance metrics of your services. An agreement within the SLA that states specific metric, like uptime, response time, security, issue resolution, etc.
I watched David Intersimone give an amazing demo of JBuilder at Borland’s booth. Months, sometimes years, of failure to create meaningful end-to-end metrics have been remedied almost immediately. My first exposure to how profound this combination can be was as a computer science undergrad attending my first conference, OOPSLA ’98.
Instead, you should adopt the DORA (DevOps Research and Assessment) metrics. These metrics show the reliability of your software systems. It’s important to note that the DORA research finds that high performing teams excel in all 4 metrics?—?there there is no compromise in quality when delivering at speed.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content