This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Heres more about the VMware security advisory and how you can quickly find affected systems using Dynatrace so you canautomate remediation efforts. With a TOCTOU vulnerability, an attacker can manipulate a system between the time a resource’s state is checked and when it’s used, also known as a race condition. Figure 5.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Dynatrace news. This is great!
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems. DJ acts as a central store where metric definitions can live and evolve.
In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. In this context, were focused on developing systems that ensure successful title launches, build trust between content creators and our brand, and reduce engineering operational overhead.
Stranger Things imagery showcasing the inspiration for the Hawkins Design System by Hawkins team member Joshua Godi ; with art contributions by Wiki Chaves Hawkins may be the name of a fictional town in Indiana, most widely known as the backdrop for one of Netflix’s most popular TV series “Stranger Things,” but the name is so much more.
As a PSM system administrator, you’ve relied on AppMon as a preconfigured APM tool for detecting, diagnosing, and repairing problems that impact the operational health of your Windchill application suite. The post It’s time to upgrade the PTC System Monitor (PSM)! Dynatrace news. appeared first on Dynatrace blog.
It doesn’t matter if you need typically used failure-rate or response-time metrics to ensure your system’s availability and performance or if you need to rely on abnormal log drops to gain insights into raising problems—SLOs leveraged with Grail provide all the information you need.
Scalability is a fundamental concept in both technology and business that refers to the ability of a system, network, or organization to handle a growing amount of requests or ability to grow. In this article, we will explore the definition of scalability, its importance, types, methods to achieve it, and real-world examples.
Journald provides unified structured logging for systems, services, and applications, eliminating the need for custom parsing for severity or details. System health, performance troubleshooting, and debugging situations no longer require manual correlation of logs across multiple disconnected tools or servers.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent. cluster=sandbox, workflow.id=demo.branch_demox.EXP_01.training
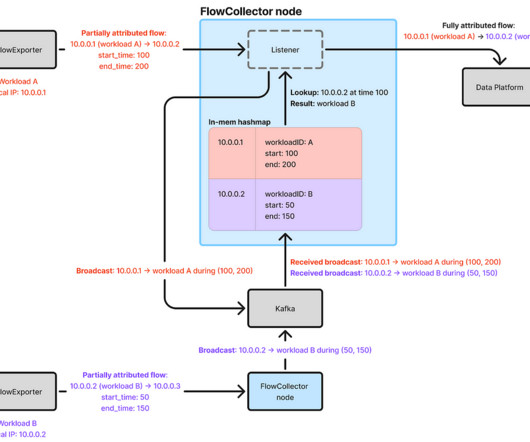
Delays and failures are inevitable in distributed systems, which may delay IP address change events from reaching FlowCollector. FlowCollector consumes a stream of IP address change events from Sonar and uses this information to attribute flow IP addresses in real-time.
The quality can be subjective, so different teams may use different definitions based on the context. Keeping good code quality is also crucial for developing safety-critical systems. Code can be considered good quality if it is clear, simple, well tested, bug-free, refactored, documented, and performant.
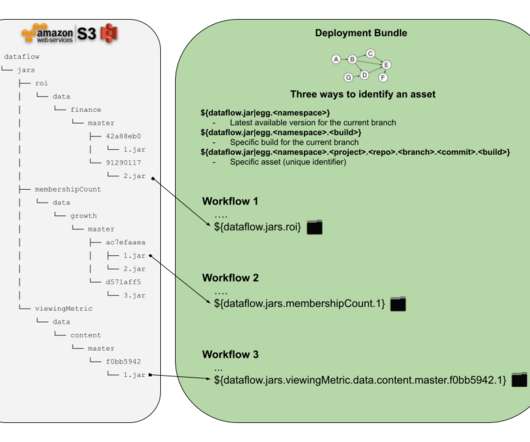
Thanks to the Netflix internal lineage system (built by Girish Lingappa ) Dataflow migration can then help you identify downstream usage of the table in question. Workflow Definitions Below you can see a typical file structure of a sample workflow package written in SparkSQL. ??? backfill.sch.yaml ??? daily.sch.yaml ???
Everyone has their own definition of true leadership. In some instances, these individuals stood their ground and continued forward in the face of violence, war, political and economic systems, beliefs, and stereotypes never before challenged. Yet, often we don't understand the importance or impact of simply being present.
First of all, a quick definition of Remote Configuration: It is a way to customize the behaviour of a desired system based on certain parameters that are stored on a remote location.
As a basis for that discussion, first some definitions: Dependability The degree to which a product or service can be relied upon. This means a system that is not merely available but is also engineered with extensive redundant measures to continue to work as its users expect. Availability and Reliability are forms of dependability.
By Chris Wolfe , Joey Schorr , and Victor Roldán Betancort Introduction The authorization team at Netflix recently sponsored work to add Attribute Based Access Control (ABAC) support to AuthZed’s open source Google Zanzibar inspired authorization system, SpiceDB. This would be a significant departure from its existing policy based system.
To help determine how customers can comply with DORA requirements, DORA’s articles can be classified in the following three categories: Definition : Describes terms and the scope of the act. Technical : Specifies technical requirements for ICT systems within an organization.
In a recent FedScoop panel Brett Vaughn, Navy Chief AI Officer, and Willie Hicks, Federal CTO for Dynatrace discuss this up-and-coming technology including: Their definition of AI. With massive technological environments, such as Navy ships and submarines, system complexity is continually growing. How AI is used in the Navy.
Feature flag solutions currently use proprietary SDKs with frameworks, definitions, and data/event types that are unique to their platforms. The specification focuses primarily on feature flag evaluation in application code, leaving the definition and management of feature flags up to the feature flag management system.
Due to its popularity, the number of workflows managed by the system has grown exponentially. The scheduler on-call has to closely monitor the system during non-business hours. As the usage increased, we had to vertically scale the system to keep up and were approaching AWS instance type limits.
We recently extended the pre-shipped code-level API definitions to group logical parts of our code so they’re consistently highlighted in all code-level views. Another benefit of defining custom APIs is that the memory allocation and surviving object metrics are split by each custom API definition.
First, I’d like to elaborate on “It may be less need for simple load testing due to increased scale and sophistication of systems” I meant that the traditional way – testing the system before deploying in production using production-type workload – is not the only way anymore.
see “data pipeline” Intro The problem of managing scheduled workflows and their assets is as old as the use of cron daemon in early Unix operating systems. The design of a cron job is simple, you take some system command, you pick the schedule to run it on and you are done. Manually constructed continuous delivery system.
Adoption As of writing this blog, Conductor orchestrates 600+ workflow definitions owned by 50+ teams across Netflix. External Payload Storage External payload storage was implemented to prevent the usage of Conductor as a data persistence system and to reduce the pressure on its backend datastore.
Here is the definition of this model: ?. PayPal, a popular online payment systems organization, implemented a full performance as a self-service model for developers to get their code performance tests. A good way to look at how this works can be seen through a few examples from Dynatrace customers that have set up this model. #1
Everyone has their own definition of true leadership. In some instances, these individuals stood their ground and continued forward in the face of violence, war, political and economic systems, beliefs, and stereotypes never before challenged. Yet, often we don't understand the importance or impact of simply being present.
Kubernetes can be a confounding platform for system architects. Extensible admission lets us change the definition of a pod after the pod is authorized but before it’s scheduled to run. If your custom resource-definition targets the pod’s namespace, OneAgent will be injected before it starts. Dynatrace news.
This article gives an overview of the system. Data Mesh Overview A New Definition Of Data Mesh Previously, we defined Data Mesh as a fully managed, streaming data pipeline product used for enabling Change Data Capture (CDC) use cases. As of now, we still have several specialized internal systems serving their own use cases.
The system facilitates large volumes of camera and sound media and is built for speed. We knew we were going to shoot in different places, said Post Supervisor Gabriel Queiroz, to have all this material cloud-based, its definitely one of the most important things for us. It will take us a lot of time.
These are all interesting metrics from marketing point of view, and also highly interesting to you as they allow you to engage with the teams that are driving the traffic against your IT-system. In the next step change, the UTM campaign parameter to also be a user action property by editing the definition as shown on the screenshot below.
API Test is crucial for the software systems to function at high quality. They allow data exchange and communication from one to another software system. Every app you build nowadays completely relies on Application Programming Interfaces. What is API Test?
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. For example, the gaming app has to present definite actions to bring the right experience. Confirming scalability, dependability, stability, and speed of the app is crucial.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
Complex IT systems make it possible to buy your favorite pair of jeans online, pay your bills, or help you navigate. These systems produce an unimaginably huge amount of data. you can now ingest data more easily at scale and derive the topological context along with the topology definition. Dynatrace news.
However, Kim underlined there is no single definition of DevOps, referring to one of his earlier works, The DevOps Handbook , where the practice was described as “architectural practices, technical practices, and cultural norms that allow us to increase our ability to deliver applications and services quickly and safely.”. Barriers to DevOps.
And we definitely couldn’t replay test non-functional requirements like caching and logging user interaction. The AB experiment results hinted that GraphQL’s correctness was not up to par with the legacy system. We knew we could test the same query with the same inputs and consistently expect the same results.
With the acceleration of complexity, scale, and dynamic systems architectures, under-resourced IT teams are under increasing pressure to understand when there is abnormal behavior, identify the precise reason why this occurred, quickly remediate the issue, and prevent this behavior in the future. How do you make a system ‘observable’?
Migrating a message-based system from on-premises to the cloud is a colossal undertaking. If you search for “how to migrate to the cloud”, there are reams of articles that encourage you to understand your system, evaluate cloud providers, choose the right messaging service, and manage security and compliance.
In this post, I'd like to talk a little about scalability from a system design perspective. In the following paragraphs, I'll cover multiple concepts related to scalability from defining what it is, to the tools and approaches that help make the system more scalable, and finally, to the signs that show whether a system is scaling well or not.
Monitoring , by textbook definition, is the process of collecting, analyzing, and using information to track a program’s progress toward reaching its objectives and to guide management decisions. Logging provides additional data but is typically viewed in isolation of a broader system context.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. Genesis Data Source and Input definition example Genesis is a stateless CLI written in Node.js
Integration with Red Hat Event-Driven-Ansible will also leverage Red Hat’s flexible rulebook system to map event data, such as problem categories or vulnerability identification, to the correct job template. Context-rich tickets can be created in systems like Jira or ServiceNow for traceability and compliance. Got any more questions?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content