This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In fact, observability is essential for shaping how we design smarter, more resilient systems for the future. As an open-source project, OpenTelemetry sets standards for telemetry data sets and works with a wide range of systems and platforms to collect and export telemetry data to backend systems. OpenTelemetry Collector 1.0
Understanding the structures within a Relational Database Management System (RDBMS) is critical to optimizing performance and managing data effectively. Here's a breakdown of the concepts with examples. RDBMS Structures 1.
Wondering which databases are trending in 2019? We asked hundreds of developers, engineers, software architects, dev teams, and IT leaders at DeveloperWeek to discover the current NoSQL vs. SQL usage, most popular databases, important metrics to track, and their most time-consuming database management tasks. SQL Databases.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
Understanding Teradata Data Distribution and Performance Optimization Teradata performance optimization and databasetuning are crucial for modern enterprise data warehouses.
All the errors seem to be caused by requests for a specific product ID or a faulty entry in the product database. So, stay tuned for more enhancements and features. This query confirms the suspicion that a particular product might be wrong. You can even walk through the same example above. This is just the beginning.
Oracle Database is a commercial, proprietary multi-model database management system produced by Oracle Corporation, and the largest relational database management system (RDBMS) in the world. While Oracle remains the #1 database on the market, its popularity has steadily declined by over 18% since 2013.
It provides an easy way to select, integrate, and customize foundation models with enterprise data using techniques like retrieval-augmented generation (RAG), fine-tuning, or continued pre-training. Full-stack tracing: Track each user request across multiple FMs, vector databases, orchestrators (LangChain), and custom business logic.
MySQL is a free open source relational database management system that is leveraged across a majority of WordPress sites, and allows you to query your data such as posts, pages, images, user profiles, and more. We help you configure your MySQL deployment to optimize your performance based on the size of your databases.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It has default settings for all of the database parameters. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. wal_buffers.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. According to 2023 statistics, 49% of web applications use an SQL-based database , with SQL having a 75% adoption rate in the IT industry.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
During this time, you are also likely to experience a degraded performance of queries as your system resources are busy in index-creation work as well. There will be a short duration (tens of seconds) during which you will lose connectivity to your database due to the failover, but this can be overcome by having application-level retries.
When it comes to enterprise-level databases, there are several options available in the market, but PostgreSQL stands out as one of the most popular and reliable choices. PostgreSQL is a free and open source object-relational database management system (ORDBMS) that has existed since the mid-1990s.
Tuning thousands of parameters has become an impossible task to achieve via a manual and time-consuming approach. JVM, databases, middleware, operating system, cloud instances, etc) by also taking advantage of Dynatrace full-stack observability. SREcon21 – Automating Performance Tuning with Machine Learning.
Interestingly, our partner RedHat reported in 2021 that around 80% of deployed workloads are databases or data caches, storing data in persistent volume claims (PVCs). You also decide to run your database for storing user uploads – such as images or videos – directly in Kubernetes. Stay tuned.
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. In addition, Davis provides automatic alerting of service-to-service communication problems using queues and other event systems.
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. Store these chunks in a vector database, indexed by their embedding vectors. The various flavors of RAG borrow from recommender systems practices, such as the use of vector databases and embeddings.
In that environment, the first PostgreSQL developers decided forking a process for each connection to the database is the safest choice. It would be a shame if your database crashed, after all. On modern Linux systems, the difference in overhead between forking a process and creating a thread is much lesser than it used to be.
Business, finance, and administrative applications written in the common business-oriented language (COBOL) have run tirelessly on IBM Z systems since the early 1960s. The selected service flow traverses the CICS Transaction Gateway followed by interactions with different CICS regions, finally triggering a database service in DB2.
I wanted to understand how I could tune Dynatrace’s problem detection, but to do that I needed to understand the situation first. This is what I wanted to optimize and avoid and many traditional (or homegrown) systems aren’t doing this. For example, invoking a webhook that creates a ticket in an ITSM system.
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics.
Stefano started his presentation by showing how much cost and performance optimization is possible when knowing how to properly configure your application runtimes, databases, or cloud environments: Correct configuration of JVM parameters can save up to 75% resource utilization while delivering same or better performance!
You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Our streaming teams need a monitoring system that enables them to quickly diagnose and remediate problems; seconds count! Our Node team needs a system that empowers a small group to operate a large fleet. By Andrei U.,
An ideal RASP technology does not need training or fine-tuning to learn what bad application behavior looks like. These limitations include the following: High tuning and monitoring overhead. With RASP technology, you can distinguish between genuine information requests and malicious attacks. More time for vulnerability management.
Below, we outline some proactive steps for achieving cost efficiency and maintaining performant database environments amid a turbulent economy: 1. Here are a few ways you can scale down and save: Audit your systems: Auditing your system for unused servers and eliminating those servers can reduce your cloud spend.
This article gives an overview of the system. As the system evolves to solve more and more use cases, we have expanded its scope to handle not only the CDC use cases but also more general data movement and processing use cases such that: Events can be sourced from more generic applications (not only databases).
Think about items such as general system metrics (for example, CPU utilization, free memory, number of services), the connectivity status, details of our web server, or even more granular in-application tasks like database queries. Database monitoring Once more, under Applications & Microservices, we’ll also find Databases.
For optimum performance, a PostgreSQL database depends on the operating system parameters being defined correctly. Poorly configured OS kernel parameters can cause degradation in database server performance. Therefore, it is imperative that these parameters are configured according to the database server and its workload.
If you need to dynamically trace Linux process system calls, you might first consider strace. So are there any tools that excel at tracing system calls in a production environment? This blog post introduces perf and traceloop, two commonly used command-line tools, to help you trace system calls in a production environment.
Migrating a proprietary database to open source is a major decision that can significantly affect your organization. Today, we’ll be taking a deep dive into the intricacies of database migration, along with specific solutions to help make the process easier.
Among these, you can find essential elements of application and infrastructure stacks, from app gateways (like HAProxy), through app fabric (like RabbitMQ), to databases (like MongoDB) and storage systems (like NetApp, Consul, Memcached, and InfluxDB, just to name a few). It’s easy—no intermediaries and no redundant moving parts.
This is where large-scale system migrations come into play. By tracking metrics only at the level of service being updated, we might miss capturing deviations in broader end-to-end system functionality. Canaries and sticky canaries are valuable tools in the system migration process.
Sure, database migration is complex, particularly when you’re looking to migrate from a proprietary database to an open source one. Database migration is almost always time-consuming, tedious, and full of potential pitfalls. Database migration is complex Let’s start here. Have you tuned your environment?
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. To set the stage, let’s have a quick recap of what Prometheus is and what it does. What is Prometheus?
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. REST APIs, authentication, databases, email, and video processing all have a home on serverless platforms. The provider is essentially your system administrator.
Today’s highly dynamic, heterogeneous, and complex software systems require organizations to establish observability for all provided cloud-native services. Gathering performance metrics like memory usage from systems where an agent can’t be installed. Dynatrace news. What’s next.
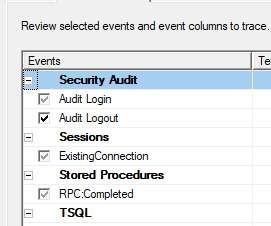
SQL Server has always provided the ability to capture actual queries in an easily-consumable rowset format – first with legacy SQL Server Profiler, later via Extended Events, and now with a combination of those two concepts in Azure SQL Database. Unfortunately, my excitement was short lived for a couple of reasons.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Designed with High Availability in mind.
Manual tasks like shutting down virtual machines in bulk or creating database backups can be error prone. Azure Automation accounts allow you to simplify cloud operations by automating the creation and deployment as well as the maintenance of resources in the Azure Cloud and across external systems. What’s next?
Indexes are generally considered to be the panacea when it comes to SQL performance tuning, and PostgreSQL supports different types of indexes catering to different use cases. I keep seeing many articles and talks on “tuning” discussing how creating new indexes speeds up SQL but rarely ones discussing removing them.
Many database administrators find themselves having to support instances of SQL Server Reporting Services (SSRS), or at least the backend databases that are required for SSRS. In each of the deployment models, the role of the database administrator is to make sure that SSRS is stable, dependable, and recoverable.
To close the gap between disparate systems, organizations need context for observability. Gerlach describes how his team uses the Dynatrace OpenTelemetry Collector and the Dynatrace Exporter with SAP HANA , a hosted, in-memory database that exposes metrics using SQL. A new view. A single platform also provides consistent views of data.
Compared to intrusion detection systems (IDS/IPS), WAFs are focused on the application traffic. For most enterprises, using a RASP solution would mean running multiple agents on their production systems, potentially creating risk due to incompatibilities. WAFs protect the network perimeter and monitor, filter, or block HTTP traffic.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content