This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. What is an MPP Database?
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Java, Go, and Node.js
Log analytics can determine whether the same service or function is consistently causing an application to not meet SLOs during peak season — for example, when a retailer offers an end-of-season sale, or a financial application is critical for closing out the year. Traditional databases help users and machines find data with a quick search.
Log analytics can determine whether the same service or function is consistently causing an application to not meet SLOs during peak season — for example, when a retailer offers an end-of-season sale, or a financial application is critical for closing out the year. Traditional databases help users and machines find data with a quick search.
“Logs magnify these issues by far due to their volatile structure, the massive storage needed to process them, and due to potential gold hidden in their content,” Pawlowski said, highlighting the importance of log analysis. ” In many cases, indexed databases only provide access to a sample of statistical data summaries.
Today, we are releasing a plugin that allows customers to use the Titan graph engine with Amazon DynamoDB as the backend storage layer. It opens up the possibility to enjoy the value that graph databases bring to relationship-centric use cases, without worrying about managing the underlying storage. Enter graph databases.
There is no need to think about schema and indexes, re-hydration, or hot/cold storage. OpenPipeline’s high-performance filtering and preprocessing provide full ingest and storage control for the Dynatrace platform. Keep in mind that Dynatrace Grail is schema-on-read and indexless, built with scaling in mind.
Seamlessly report and be alerted on non-topology-related custom metrics, using Dynatrace as a metric database. Because you can now seamlessly report non-topological metrics, you can now use Dynatrace as a metric database. This allows you to: Use auto-adaptive baselines for all your custom metrics.
For Amazon retail, some of those dimensions are low pricing, large catalog, fast shipping, and convenience. For example, when our retail customers contributed to create larger economies of scale for Amazon.com, we used the savings to lower pricing such that our customers could also benefit. Driving Storage Costs Down for AWS Customers.
Today marks the 10 year anniversary of Amazon's Dynamo whitepaper , a milestone that made me reflect on how much innovation has occurred in the area of databases over the last decade and a good reminder on why taking a customer obsessed approach to solving hard problems can have lasting impact beyond your original expectations.
Some time ago I participated in design of a backend for one large online retailer company. From the technical perspective, the following properties should be highlighted: All data is initially stored in the relational database, but this database is heavily loaded because it is a master record for many applications.
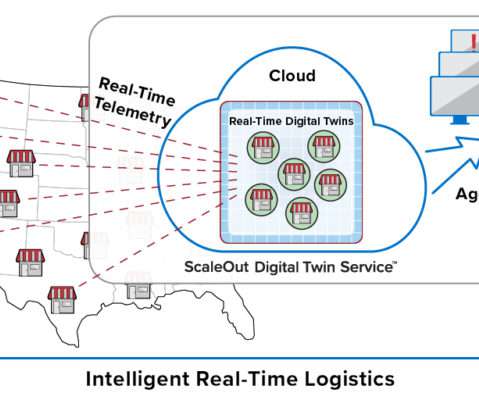
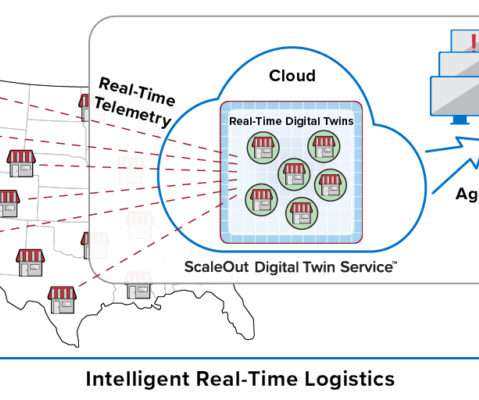
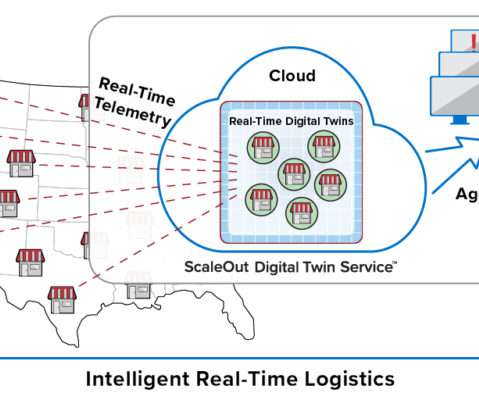
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough to just pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
For example, someone might web scrape all the product pages of a competitor’s retail site to harvest information about products being offered and current pricing to try to gain a competitive edge. These are page views loaded from a previously-viewed web page that was saved to device local storage. Turning The Data Into Information.
Cheap storage and on-demand compute in the cloud coupled with the emergence of new big data frameworks and tools are forcing us to rethink the whole ETL and data warehousing architecture. In classic Extract, transform, and load (ETL) model, we store entities in their corresponding application databases i.e. as rows in the relational tables.
Some of the names include Amazon’s Luna, TikTok, Tinder, among many online retailers. On the contrary, a native application of an e-commerce store can come at 30, 50, or even 100 MB and up, consuming internal device storage. These multiple “heads” are attached to the backend and database. Image credit: Apivita. Large preview ).
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. The Need to Keep It Simple. Likewise, it must be easy to remove IMDG servers when the workload decreases and creates excess capacity.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. The Need to Keep It Simple. Likewise, it must be easy to remove IMDG servers when the workload decreases and creates excess capacity.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content