This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. What is an MPP Database?
Retail is one of the most important business domains for data science and data mining applications because of its prolific data and numerous optimization problems such as optimal prices, discounts, recommendations, and stock levels that can be solved using data analysis methods. However, many of these models are highly parametric (i.e.
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Through effortless provisioning, a larger number of small hosts provide a cost-effective and scalable platform. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Java, Go, and Node.js
Possible scenarios A retail website crashes during a major sale event due to a surge in traffic. To manage high demand, companies should invest in scalable infrastructure , load-balancing, and load-scaling technologies. Possible scenarios An IT technician accidentally deletes a critical database, causing a service outage.
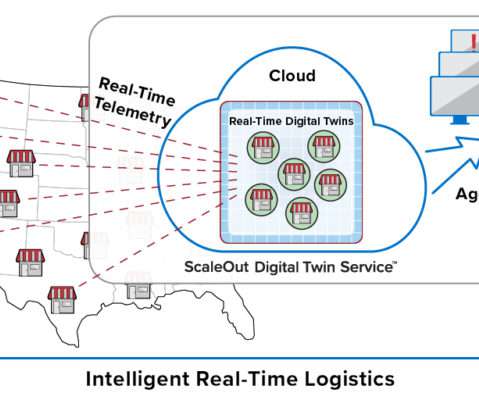
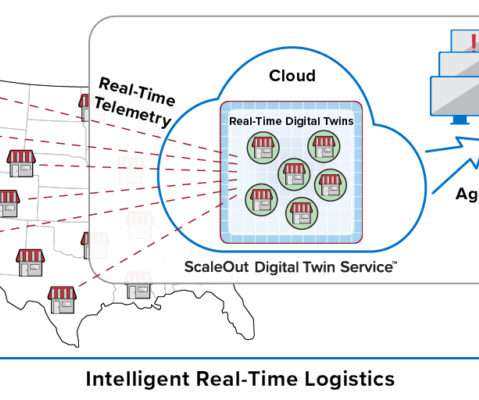
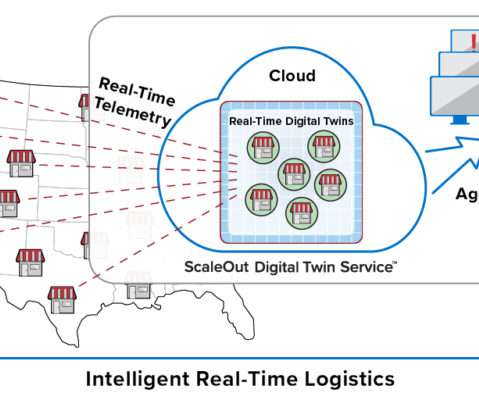
It opens up the possibility to enjoy the value that graph databases bring to relationship-centric use cases, without worrying about managing the underlying storage. In supply chain management, connections between airports, warehouses, and retail aisles are critical for cost and time optimization. Enter graph databases.
With the extent of observability data going beyond human capacity to manage, Grail is the first purpose-built causational data lakehouse that allows for immediate answers with cost-efficient, scalable storage. ” In many cases, indexed databases only provide access to a sample of statistical data summaries.
David Rosenthal : The margins on AWS, averaging 24.75% over the last twelve quarters, are what enables Amazon to run the US retail business averaging under 3% margin and the international business averaging -3.7% Alok Pathak : While both (Multi-AZ and Read replica) maintain a copy of database but they are different in nature.
Today, we added two important choices for customers running high performance apps in the cloud: support for Redis in Amazon ElastiCache and a new high memory database instance (db.cr1.8xlarge) for Amazon RDS. No single database architecture or solution can meet all of Amazon.com’s or our customers’ needs.
Today marks the 10 year anniversary of Amazon's Dynamo whitepaper , a milestone that made me reflect on how much innovation has occurred in the area of databases over the last decade and a good reminder on why taking a customer obsessed approach to solving hard problems can have lasting impact beyond your original expectations.
We launched DynamoDB last year to address the need for a cloud database that provides seamless scalability, irrespective of whether you are doing ten transactions or ten million transactions, while providing rock solid durability and availability. Going beyond Key-Value. Both these options are less than ideal. DynamoDB Refresher.
Werner Vogels weblog on building scalable and robust distributed systems. For Amazon retail, some of those dimensions are low pricing, large catalog, fast shipping, and convenience. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. All Things Distributed. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. The Amazon Simple Queue Service (SQS) is a highly scalable, reliable and elastic queuing service that just works. Simple Queue Service (SQS) is very useful, easy to use, scalable and reliable. Amazon SQS provides highly scalable â??eventual
Amazon ElastiCache embodies much of what makes fast data a reality for customers looking to process high volume data at incredible rates, faster than traditional databases can manage. Since then, we have added support for Redis clusters, enabling customers to run faster and more scalable workloads.
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough to just pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Some time ago I participated in design of a backend for one large online retailer company. From the technical perspective, the following properties should be highlighted: All data is initially stored in the relational database, but this database is heavily loaded because it is a master record for many applications.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. The Need to Keep It Simple. ScaleOut StateServer uses different techniques on EC2 and Azure to make use of available metadata support.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. The Need to Keep It Simple. ScaleOut StateServer uses different techniques on EC2 and Azure to make use of available metadata support.
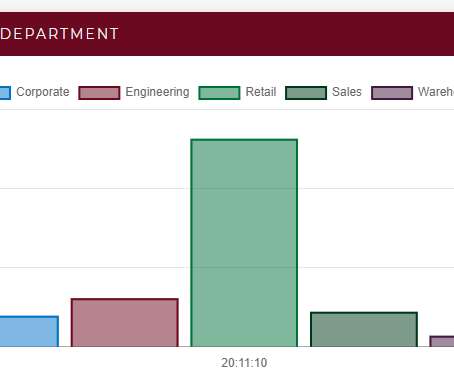
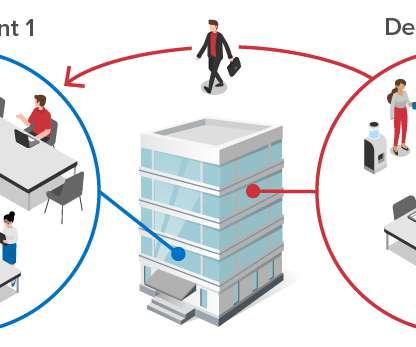
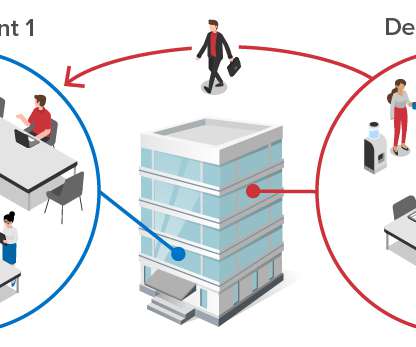
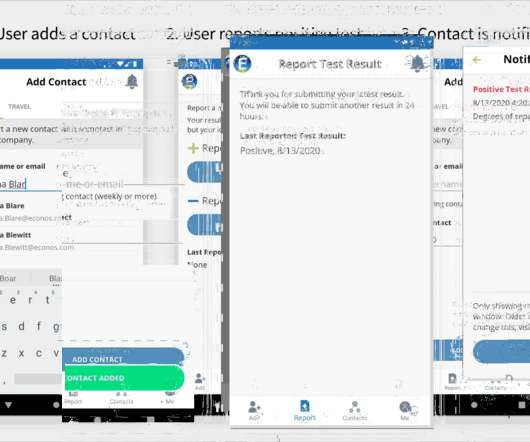
These interactions also need to be tracked to contain exposure within the organization, as illustrated in the following diagram: Voluntary contact self-tracing can handle the most common scenarios by using the company’s employee database to automatically connect colleagues who work in the same department and interact daily.
These interactions also need to be tracked to contain exposure within the organization, as illustrated in the following diagram: Voluntary contact self-tracing can handle the most common scenarios by using the company’s employee database to automatically connect colleagues who work in the same department and interact daily.
These interactions also need to be tracked to contain exposure within the organization, as illustrated in the following diagram: Voluntary contact self-tracing can handle the most common scenarios by using the company’s employee database to automatically connect colleagues who work in the same department and interact daily.
It is likely that entire companies will be in the business of identifying these nuances and selling them as “fingerprint databases” for identifying fake news articles. The valuation of crypto today is consequential to financial markets and the net worth of retail and institutional investors.
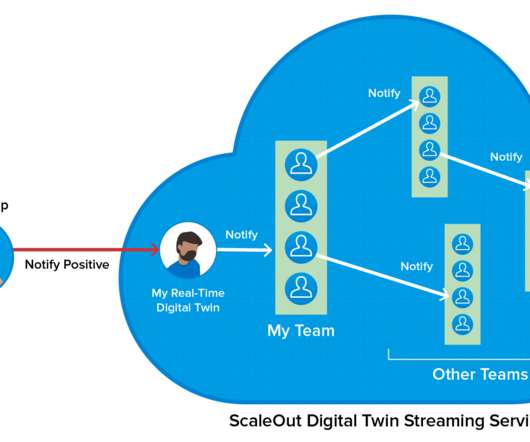
Using information from the company’s organizational database, it populates each twin with the employee’s ID, team ID, department type, and location. The demo application creates a memory-based real-time digital twin for each employee. The Benefits of an Integrated Streaming Service.
Using information from the company’s organizational database, it populates each twin with the employee’s ID, team ID, department type, and location. The demo application creates a memory-based real-time digital twin for each employee. The Benefits of an Integrated Streaming Service.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content