This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the most significant challenges faced by middleware applications is optimizing database interactions. This is crucial because middleware often serves as the bridge between client applications and backend databases, handling a high volume of requests and data processing tasks.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. What is an MPP Database?
Ready to transition from a commercial database to open source, and want to know which databases are most popular in 2019? Wondering whether an on-premise vs. public cloud vs. hybrid cloud infrastructure is best for your database strategy? Polyglot Persistence Trends : Number of Databases Used & Top Combinations.
Apache Kafka is a battle-tested distributed stream-processing platform popular in the financial industry to handle mission-critical transactional workloads. A common data pipeline to ingest and store financial data involves publishing real-time data to Kafka and utilizing Kafka Connect to stream that to databases.
In this article, we’ll dive deep into the concept of database sharding, a critical technique for scaling databases to handle large volumes of data and high levels of traffic. We’ll start by defining what sharding is and why it’s essential for modern, high-performance databases.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. Yet, the impact of choosing the right NoSQL database goes beyond these parameters; it affects your business outcomes.
Maintaining optimal application performance is crucial for businesses, and fast databases are vital in achieving this goal. For an effective approach to database performance, it’s crucial to have a comprehensive overview of all databases, including server-side DBs.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
Top takeaways: Key OpenTelemetry trends in 2025 Semantic Conventions ensure alignment: Semantic Conventions provide consistent telemetry data interpretation, correlation, and automation, with HTTP spans now stable and other domains like databases and messaging nearing stabilization.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Similar to the tutorial extension, we created an extension that performs queries against databases.
It's challenging to troubleshoot issues in a distributed database because the information about the system is scattered in different machines. TiDB is an open-source, distributed SQL database that supports Hybrid Transactional/Analytical Processing (HTAP) workloads. Before version 4.0, Before version 4.0,
In the era of the Internet of Things ( IoT) , the continuous influx of spatial and temporal data from interconnected devices has given rise to a vast and intricate landscape, demanding a sophisticated approach to database management.
But existing business intelligence (BI) tools often lack the broad context, ease of data access, and real-time insights needed to understand and improve customer experience and complex business processes. There are also many cases where business data—transactional, inventory, or financial—is at rest or in use , stored in a database.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
However, unless it is processed and stored effectively, it holds little value. Some databases prioritize organizing data based on its time of generation, while others focus on different functionalities. Data is being generated from various sources, including electronic devices, machines, and social media, across all industries.
As cloud applications have become the norm, the databases that power these applications are now typically run as managed services by cloud providers. Optimize database performance. Small changes in a database can have an enormous impact on overall application performance. Log monitoring beyond cloud platform databases.
This combination allows a malicious actor with local administrative privileges on a virtual machine to execute code as the virtual machine’s VMX process running on the host. It allows a malicious actor with privileges within the VMX process to trigger an arbitrary kernel write, which can lead to an escape from the sandbox.
This case study explores WeBank’s successful use of PingCAP’s TiDB , an advanced, open-source, distributed SQL database, to clear its technical hurdles and accommodate business growth. So far, WeBank has served over 250 million individual customers, 20 million individual business customers, and 1.5 million corporate customers.
Understanding Teradata Data Distribution and Performance Optimization Teradata performance optimization and database tuning are crucial for modern enterprise data warehouses.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Start your free trial today!
As these systems become more complex handling sensitive data, supporting real-time queries, and interfacing with multiple services being able to trace and measure each step of the data flow and inference process becomes critical.
The conversational interface provides step-by-step guidance, making the onboarding process smoother and more efficient. Davis CoPilot explains problems in clear language Optimize database performance: Understand query execution plans Query execution plans provide detailed information on how a database will execute an SQL query.
The vulnerability, identified as CVE-2024-6632, allows the abuse of a form submission during the setup process to make unauthorized modifications of the database. So far, the vulnerability only appears to be exploitable by an authenticated user during the setup process. This allows for unauthorized modifications on the database.
In addition to service-level monitoring, certain services within the OpenTelemetry demo application expose process-level metrics, such as CPU and memory consumption, number of threads, or heap size for services written in different languages. This query confirms the suspicion that a particular product might be wrong.
PostgreSQL is one of the most popular SQL databases. It’s a go-to database for many projects dealing with Online Transaction Processing systems. How It All Started Historically, we focused on two distinct database workflows: Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP).
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. According to 2023 statistics, 49% of web applications use an SQL-based database , with SQL having a 75% adoption rate in the IT industry.
if you wanted to schedule a job, you could use the Cron binding component to implement recurring jobs on a regular defined schedule; for example, automating database backups, sending out recurring email notifications, running routine maintenance tasks, data processing, and ETL, running system updates and batch processing.
We will use a graph database such as Neo4j to store the information. Additionally, we can use columnar databases like Cassandra to store information like user feeds, activities, and counters. There are two major processes which gets executed when a user posts a photo on Instagram. System Components. Component Design. API Design.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. It handles every transaction, ensuring that data modifications are correctly processed.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Using a low-code visual workflow approach, organizations can orchestrate key services, automate critical processes, and create new serverless applications. Improving data processing.
Relational Databases are the bedrock of any FinTech application, especially for OLTP (Online transaction Processing). So, it is imperative that all database activities are monitored closely in the production environment and issues like long-running queries are tracked and resolved.
For more: Read the Report We live in an era of rapid data generation from countless sources, including sensors, databases, cloud, devices, and more. To keep up, we require real-time analytics (RTA), which provides the immediacy that every user of data today expects and is based on stream processing.
Auditing in information technology (IT) is a process of examining an organization’s IT infrastructure to ensure compliance with the requirements imposed by recognized standards or established policies.
In most financial firms, online transaction processing (OLTP) often relies on static or infrequently updated data, also called reference data. NoSQL databases emerge as ideal candidates to meet these requirements, and cloud platforms such as AWS offer managed and highly resilient data ecosystems.
The National Vulnerability Database describes the vulnerability here. As organizations work to find the usage of this library in their applications, they should focus on three criteria to prioritize the fix in their environment: Public Internet Exposure – Are the Java processes using these libraries directly accessible from the internet?
This process involves: Identifying Stakeholders: Determine who is impacted by the issue and whose input is crucial for a successful resolution. Understanding the BiggerPicture Lets take a comprehensive look at all the elements involved and how they interconnect. We should aim to address questions such as: What is vital to the business?
You can easily pivot between a hot Kubernetes cluster and the log file related to the issue in 2-3 clicks in these Dynatrace® Apps: Infrastructure & Observability (I&O), Databases, Clouds, and Kubernetes. Is there a sudden spike in errors? A sudden drop in received log data?
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Java, Go, and Node.js
The National Vulnerability Database describes the exploit here. As organizations work to find the usage of this library in their applications, they should focus on three criteria to prioritize the fix in their environment: Public Internet Exposure – Are the Java processes using these libraries directly accessible from the internet?
The latest batch of services cover databases, networks, machine learning and computing. Amazon Database Migration Service. Amazon Quantum Ledger Database (QLDB). Ensure high application performance by easily troubleshooting Amazon Neptune graph database. Achieve full observability of all AWS services. Available Now.
Financial data engineering in SAS involves the management, processing, and analysis of financial data using the various tools and techniques provided by the SAS software suite. Data Import and Export Use PROC IMPORT and PROC EXPORT procedures to read and write financial data from and to various file formats such as CSV, Excel, and databases.
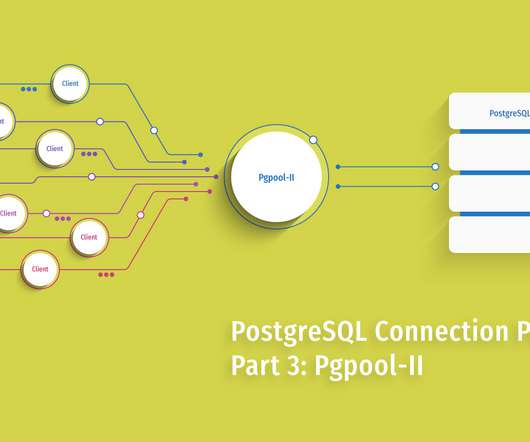
The Pgpool-II parent process forks 32 child processes by default – these are available for connection. The architecture is similar to PostgreSQL server: one process = one connection. It also forks the ‘pcp process’ which is used for administrative tasks, and beyond the scope of this post. Expert Tip.
Store these chunks in a vector database, indexed by their embedding vectors. While the overall process may be more complicated in practice, this is the gist. While the overall process may be more complicated in practice, this is the gist. Run each chunk of text through an embedding model to compute a vector for it.
This article compares QuestDB with one of the most popular databases on the market, MongoDB. We look at the two databases in terms of benchmark performance and user experience. Time series data is often processed with dedicated tooling. Time-series data has gained popularity in recent years.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content