This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To get a better idea of OpenTelemetry trends in 2025 and how to get the most out of it in your observability strategy, some of our Dynatrace open-source engineers and advocates picked out the innovations they find most interesting. In 2025, we expect to see the first releases, so youll be able to test out this innovative technology.
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
Grail combines the big-data storage of a data warehouse with the analytical flexibility of a data lake. This unified approach enables Grail to vault past the limitations of traditional databases. And without the encumbrances of traditional databases, Grail performs fast. “In
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Our object storage service splits objects into many parts and stores them in S3.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
As Ibrar Ahmed noted in his blog post on Transparent Database Encryption (TDE). PostgreSQL is a surprising outlier when it comes to offering Transparent Database Encryption. If database files are copied or otherwise exposed in their raw form, exposure does not happen. Does PostgreSQL Need TDE (Transparent Data Encryption)?
Database monitoring. This ensures the database queries are performant, while also identifying host problems. For example, uptime detection can identify database instability and help to improve mean time to restoration. Cloud storage monitoring. Website monitoring. Virtual machine (VM) monitoring.
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. For example, you can choose the public cloud storage type – gp3, io2, etc, or set file system.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
Retention-based deletion is governed by a policy outlining the duration for which data is stored in the database before it’s deleted automatically. For instance, if data is mistakenly ingested into the database, it may need to be deleted to prevent inaccuracies or sensitive data from being stored.
Customer Conversations - How Intuit and Edmodo Innovate using Amazon RDS. From tax preparation to safe social networks, Amazon RDS brings new and innovative applications to the cloud. Empowering innovation is at the heart of everything we do at Amazon Web Services (AWS). Whats unique and innovative about your service?
Relational databases have been around for a long time. The core technologies underpinning the major relational database management systems of today were developed in the 1980–1990s. Those fundamentals helped make relational databases immensely popular with users everywhere.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more.
Relational databases have been around for a long time. The core technologies underpinning the major relational database management systems of today were developed in the 1980–1990s. Those fundamentals helped make relational databases immensely popular with users everywhere.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. With Dynatrace, teams can seamlessly monitor the entire system, including network switches, databasestorage, and third-party dependencies. Why reliability?
New databases used to be announced seemingly every week. While database neogenesis has slowed down considerably, it has not gone necrotic. Each storage server collects statistics about the requests it serves, the data it stores, etc. Our monitoring engine automatically moves data between tiers based on access patterns.
As a result, organizations need software to work perfectly to create customer experiences, deliver innovation, and generate operational efficiency. Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs.
Today, we are releasing a plugin that allows customers to use the Titan graph engine with Amazon DynamoDB as the backend storage layer. It opens up the possibility to enjoy the value that graph databases bring to relationship-centric use cases, without worrying about managing the underlying storage. Enter graph databases.
The use of open source databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “open source database” really is and what it offers. What is an open source database?
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
Dynatrace unifies capture, storage, analytics, and visualization into a single platform that ensures consistent and gapless access to information. To achieve my goal with Dynatrace, we had to rethink observability from the ground up. Follow the new “Dynatrace for Executives” blog series.
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements.
There is no need to think about schema and indexes, re-hydration, or hot/cold storage. OpenPipeline’s high-performance filtering and preprocessing provide full ingest and storage control for the Dynatrace platform. Keep in mind that Dynatrace Grail is schema-on-read and indexless, built with scaling in mind.
In this blog post, we will see how running databases on Kubernetes with Percona Operators can reduce your cloud bill when compared to using AWS RDS. year For ten instances, it will be $168,192 per year Default gp2 storage is $0.115 per GB-month, for 200 GB, it is $22.50/month EBS gp2 storage is $0.10 db.r5.4xlarge – $1.92/hour
As a result, not only can you understand, for example, that someone accessed a database, but also from where they came, exactly what they accessed, and to where they exported the data–to the level that we know the exact database query statement.
This upgrade has vastly improved the management and storage of metadata, resulting in better reliability and scalability for various database objects. The primary goal of the Transaction Data Dictionary (TDD) is to enhance the overall performance, stability, and scalability of MySQL databases. In MySQL 5.7,
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. The process involves monitoring various components of the software delivery pipeline, including applications, infrastructure, networks, and databases.
Migrating a proprietary database to open source is a major decision that can significantly affect your organization. Today, we’ll be taking a deep dive into the intricacies of database migration, along with specific solutions to help make the process easier.
Seamlessly report and be alerted on non-topology-related custom metrics, using Dynatrace as a metric database. Our latest innovation for detecting anomalies in metrics, topology-aware Davis-AI auto-adaptive baselining, is unique in that it adapts to changing metric behavior over time, thereby helping you to avoid false-positive alerts.
Our recent updates span several versions, introducing key improvements and bug fixes to ensure our clients’ databases run smoother, faster, and more securely. Updates Across the Board Improved Database Resilience and Security Our most recent updates have focused on improving database resilience and security across various platforms.
Amazon Redshift uses a variety of innovations to enable customers to rapidly analyze datasets ranging in size from several hundred gigabytes to a petabyte and more. Unlike traditional row-based relational databases, which store data for each row sequentially on disk, Amazon Redshift stores each column sequentially. Amazon Redshiftâ??s
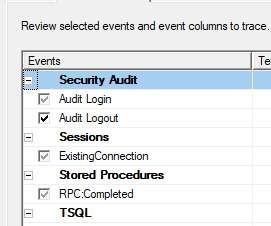
SQL Server has always provided the ability to capture actual queries in an easily-consumable rowset format – first with legacy SQL Server Profiler, later via Extended Events, and now with a combination of those two concepts in Azure SQL Database. ALTER EVENT SESSION [ ADS_Standard_Azure ] ON DATABASE. DROP EVENT sqlserver.
If you’re considering a database management system, understanding these benefits is crucial. DBMS enhances data security with encryption, implements various access controls, and enables improved data sharing and concurrent access, thus facilitating quick response to changes and maintaining consistent database accuracy.
Expanding the Cloud - Amazon S3 Reduced Redundancy Storage. Today a new storage option for Amazon S3 has been launched: Amazon S3 Reduced Redundancy Storage (RRS). This new storage option enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of redundancy. Comments ().
The service pairs ideally with single-use functions that tie into other services and is intended to simplify application development and accelerate innovation. These functions can connect with supported cloud databases, such as Cloud SQL and Bigtable. GCF is part of the Google Cloud Platform. GCF use cases. Image courtesy of Google.
AI-driven cloud solutions like ScaleGrid offer a diverse range of database hosting options, robust infrastructure optimized for scalability and security, and enable significant cost reductions, supporting businesses in efficient growth and improved ROI. These services are tailored to meet various business requirements.
Many of our customers have, with the click of a button, created DynamoDB deployments in a matter of minutes that are able to serve trillions of database requests per year. We have also reduced our underlying costs through significant technical innovations from our engineering team. s prices by 70%. For example, in our US East (N.
million” – Gartner Data observability is a practice that helps organizations understand the full lifecycle of data, from ingestion to storage and usage, to ensure data health and reliability. Data is the foundation upon which strategies are built, directions are chosen, and innovations are pursued.
On October 24th, the Percona Kubernetes Squad held the first Ask-me-Anything (AMA) session to address inquiries regarding the utilization of Kubernetes for database deployment. Q1: When is it appropriate to use Kubernetes for databases, and when is it not recommended? ” This talk covers this topic exactly.
As VMAF evolves and is integrated with more encoding and streaming workflows within Netflix, we need scalable ways of fostering video quality innovations. This article explains how we designed microservices and workflows on top of the Cosmos platform to bolster such video quality innovations. via bug fixes).
What used to be only available in physical formats now often has digital equivalents and this digitalization is driving great new innovations. I am excited about this because it is already making my digital music experience simpler and I am looking forward to the innovation that these services will drive on behalf of our customers.
To do so, weve leaned heavily on the core principles from the distributed systems and database research communities and invented from there. The storage systems weve pioneered demonstrate extreme scalability while maintaining tight control over performance, availability, and cost. Driving Storage Costs Down for AWS Customers.
PostgreSQL is open source relational database management software. Most recently, in StackOverflow’s 2022 Stack Developer Survey , PostgreSQL took a slight lead over MySQL (46.48% to 45.68%) as the most popular database platform among professional developers. What is PostgreSQL used for? Is PostgreSQL enterprise-ready?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content