This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you’re running SAP, you’re likely already familiar with the HANA relational database management system. However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Avoid false positives with auto-adaptive baselining.
Almost daily, teams have requests for new toolsfor database management, CI/CD, security, and collaborationto address specific needs. Worsened by separate tools to track metrics, logs, traces, and user behaviorcrucial, interconnected details are separated into different storage.
Ready to transition from a commercial database to open source, and want to know which databases are most popular in 2019? Wondering whether an on-premise vs. public cloud vs. hybrid cloud infrastructure is best for your database strategy? Cloud Infrastructure Analysis : Public Cloud vs. On-Premise vs. Hybrid Cloud.
Running Databases efficiently is crucial for business success Monitoring databases is essential in large IT environments to prevent potential issues from becoming major problems that result in data loss or downtime. However, horizontal scaling of these databases can take time and effort.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Infrastructure and operations teams must maintain infrastructure health for IT environments. Any problem, such as a simple software update overburdening a critical database, can cause a ripple effect that degrades the performance of dependent services or applications.
Maintaining optimal application performance is crucial for businesses, and fast databases are vital in achieving this goal. For an effective approach to database performance, it’s crucial to have a comprehensive overview of all databases, including server-side DBs.
While many companies now enlist public cloud services such as Amazon Web Services, Google Public Cloud, or Microsoft Azure to achieve their business goals, a majority also use hybrid cloud infrastructure to accommodate traditional applications that can’t be easily migrated to public clouds. How to modernize for hybrid cloud.
While applications are built using a variety of technologies and frameworks, there is one thing they usually have in common: the data they work with must be stored in databases. Now, Dynatrace has gone a step further and expanded its coverage and intelligent observability into the next layer: databaseinfrastructure.
If you’re doing it right, cloud represents a fundamental change in how you build, deliver and operate your applications and infrastructure. And that includes infrastructure monitoring. This also implies a fundamental change to the role of infrastructure and operations teams. Able to provide answers, not just data.
DataJunction: Unifying Experimentation and Analytics Yian Shang , AnhLe At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. DJ acts as a central store where metric definitions can live and evolve. As an example, imagine an analyst wanting to create a Total Streaming Hours metric.
AlloyDB is a fully managed, PostgreSQL-compatible database service for highly demanding enterprise database workloads. With this Google Cloud Ready integration, Dynatrace ensures that AlloyDB for PostgreSQL users can now ingest metrics along with existing Google Cloud data.
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. With public clouds, multiple organizations share resources.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. We’ve seen the IT infrastructure landscape evolve rapidly over the past few years. What is infrastructure monitoring? . Dynatrace news.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. This insight led us to build Edgar: a distributed tracing infrastructure and user experience. Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage.
In those cases, what should you do if you want to be proactive and ensure that your infrastructure is always up and running? Are you looking to monitor your infrastructure using one of our ready-made extensions, or would you like to draw on our experience and create your own synthetic monitors? Third-party synthetic monitors.
The importance of critical infrastructure and services While digital government is necessary, protecting critical infrastructure and services is equally important. Critical infrastructure and services refer to the systems, facilities, and assets vital for the functioning of society and the economy.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012. What is Prometheus?
One of my favorite things about QuestDB is the ability to write queries in SQL against a high-performance time series database. In my life as a cloud engineer, I deal with time series metrics all the time. Unfortunately, many of today’s popular metricsdatabases don’t support the SQL query language.
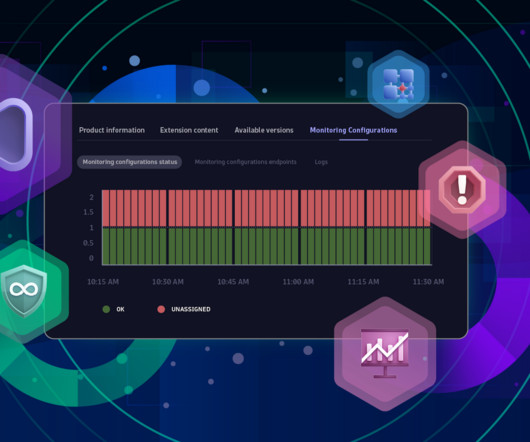
Its easy to adapt to changes that are common in cloud environments with just a few clicks: Has the OneAgent found an unsupervised database? Video 2: Expanding database monitoring according to discovery findings The condition of the databases is one of the most significant factors indicating the health of the whole application.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Capturing data is critical to understanding how your applications and infrastructure are performing at any given time. Span ingestion.
OpenTelemetry provides a common set of tools, APIs, and SDKs to help collect observability signals from applications and infrastructure endpoints. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. metrics from span data.
A single instance of OneAgent can handle the monitoring of many types of entities , including servers, applications, services, databases, and more. But what if a particular metric is crucial for your monitoring needs and it isn’t there? Let the Davis AI causation engine analyze additional metrics. What’s next.
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. The strongest Kubernetes growth areas are security, databases, and CI/CD technologies.
What about correlated trace data, host metrics, real-time vulnerability scanning results, or log messages captured just before an incident occurs? Depending on which app is in use, one glance at a histogram provides invaluable insight into managing clouds, databases, Kubernetes environments, and infrastructure.
Apache Cassandra is an open-source, distributed, NoSQL database. Microsoft Azure offers multiple ways to manage Apache Cassandra databases. It also removes the need for developers and database administrators to manage infrastructure or update database versions. Seeing the value.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data.
According to the Dynatrace “2022 Global CIO Report,” 79% of large organizations use multicloud infrastructure. Moreover, organizations have to balance maintaining security, retaining cloud management expertise, and managing infrastructure performance. Rural lifestyle retail giant Tractor Supply Co.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Estimates show that NVIDIA, a semiconductor manufacturer, could release 1.5
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
It also includes various built-in software components for database management, security, and application development. It then collects performance data using existing database services running on your system. Gaining knowledge about IBM i performance can be a challenging and pricey task. Nothing is installed on your IBM i systems.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Many technologies expose their metrics in the Prometheus data format. Our monitoring coverage already includes ?
Missing operational insights, lack of context, and limited understanding of cloud service dependencies making it almost impossible to find the root cause of customer-facing application issues or underlying infrastructure problems. Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. This unified approach enables Grail to vault past the limitations of traditional databases. And without the encumbrances of traditional databases, Grail performs fast. “In
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues. where an error occurred at the code level.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. Why reliability? The problems that take maximum time to resolve – lowest MTTR.
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. Dynatrace Extension: database performance as experienced by the SAP ABAP server.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. metrics, traces, and logs) to gain a better understanding of the behavior of their code during runtime.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. They enable IT teams to identify and address the precise cause of application and infrastructure issues.
Cloud migration enables IT teams to enlist public cloud infrastructure so an organization can innovate without getting bogged down in managing all aspects of IT infrastructure as it scales. They need ways to monitor infrastructure, even if it’s no longer on premises. Right-sizing infrastructure. Repurchase.
Advanced observability can eliminate blind spots surrounding application performance, health, and behavior for these critical applications and the infrastructure that supports them. Infrastructure monitoring automatically analyzes key health metrics and discovers performance problems caused by infrastructure bottlenecks or changes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content