This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Similar to the tutorial extension, we created an extension that performs queries against databases.
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Improved JSON Handling & Security: Improved logical replication and the new MAINTAIN privilege give database administrators more control and flexibility. Start your free trial today!
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
NoSQL databases are often compared by various non-functional criteria, such as scalability, performance, and consistency. At the same time, NoSQL data modeling is not so well studied and lacks the systematic theory found in relational databases. Documentdatabases advance the BigTable model offering two significant improvements.
JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. Why should a relational database even care about unstructured data? Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSON database in 9.2
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. Choosing the appropriate storage engine can have a significant impact on application performance.
Cosmos DB is a multimodal database in Azure that supports schema-less storage. By default, Cosmos DB containers tend to index all the fields of a document uploaded. For key object storage, RU tends to be less, but it still depends on the payload size. Cosmos DB can be a good candidate for a key-value store.
Retention-based deletion is governed by a policy outlining the duration for which data is stored in the database before it’s deleted automatically. For instance, if data is mistakenly ingested into the database, it may need to be deleted to prevent inaccuracies or sensitive data from being stored.
MySQL is a free open source relational database management system that is leveraged across a majority of WordPress sites, and allows you to query your data such as posts, pages, images, user profiles, and more. Managing a database is hard, as it needs continuous updating, tuning, and monitoring to ensure the performance of your website.
We are introducing native support for document model like JSON into DynamoDB, the ability to add / remove global secondary indexes, adding more flexible scaling options, and increasing the item size limit to 400KB. The original Dynamo paper inspired many database solutions, which are now popularly referred to as NoSQL databases.
A common question that I get is why do we offer so many database products? To do this, they need to be able to use multiple databases and data models within the same application. Seldom can one database fit the needs of multiple distinct use cases. Seldom can one database fit the needs of multiple distinct use cases.
There are several limitations to store and fetch such data (all restrictions could be found in official documentation ). To resolve the problem it was suggested to find more suitable data storage. It's still not possible to continue using light-weighted databases such as HSQL or H2 to implement tests.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Java, Go, and Node.js
Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures. “Logs magnify these issues by far due to their volatile structure, the massive storage needed to process them, and due to potential gold hidden in their content,” Pawlowski said, highlighting the importance of log analysis.
Choosing the right database often comes down to MongoDB vs MySQL. Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. Data modeling is a critical skill for developers to manage and analyze data within these database systems effectively.
The use of open source databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “open source database” really is and what it offers. What is an open source database?
Among these, you can find essential elements of application and infrastructure stacks, from app gateways (like HAProxy), through app fabric (like RabbitMQ), to databases (like MongoDB) and storage systems (like NetApp, Consul, Memcached, and InfluxDB, just to name a few). documentation. Prometheus Data Source documentation.
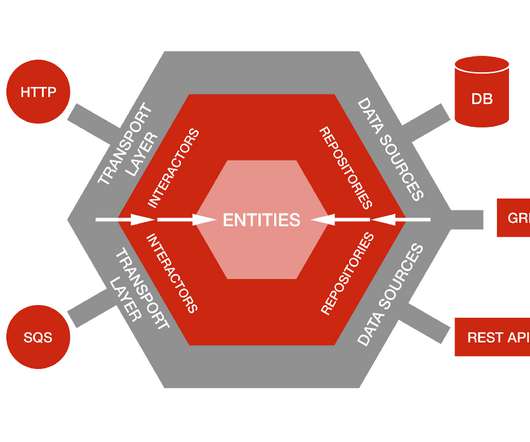
At one point, more than 30 developers were working on it, and it had well over 300 database tables. a database, a microservice API exposed via gRPC or REST, or just a simple CSV file. Outside of the business logic are the Data Sources and the Transport Layer: Data Sources are adapters to different storage implementations.
Migrating a proprietary database to open source is a major decision that can significantly affect your organization. Today, we’ll be taking a deep dive into the intricacies of database migration, along with specific solutions to help make the process easier.
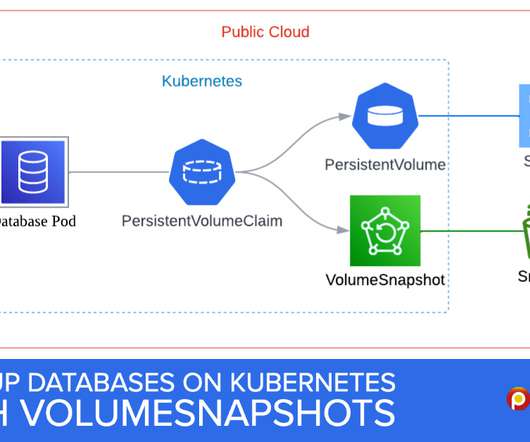
Databases on Kubernetes continue their rising trend. Our Operators provide built-in backup and restore capabilities, but some users are still looking for old-fashioned ways, like storage-level snapshots (i.e., Both your storage and Container Storage Interface (CSI) must support snapshots. AWS EBS Snapshots).
TDE is a database encryption technique that encrypts data at the column or table level, as opposed to full-disk encryption (FDE), which encrypts the entire database. To enable the encryption of the storage in Kubernetes, you need to modify the StorageClass resource. apiVersion: storage.k8s.io/v1 apiVersion: storage.k8s.io/v1
There are many naive solutions possible for this problem for example: Write different runs in different databases. Instead our challenge was to implement this feature on top of Cassandra and ElasticSearch databases because that’s what Marken uses. This is obviously very expensive. Write algo runs into files.
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
There is no need to think about schema and indexes, re-hydration, or hot/cold storage. OpenPipeline’s high-performance filtering and preprocessing provide full ingest and storage control for the Dynatrace platform. Keep in mind that Dynatrace Grail is schema-on-read and indexless, built with scaling in mind.
Data powers everything, and unlike coal and coal combustion, data and databases aren’t going away. In this blog, we’ll focus on the elements of database backup and disaster recovery, and we’ll introduce proven solutions for maintaining business continuity, even amid otherwise dire circumstances.
MongoDB is the #3 open source database and the #1 NoSQL database in the world. It’s a cross-platform document-oriented database that uses JSON-like documents with schema, and is leveraged broadly across startup apps up to enterprise-level businesses developing modern apps. minutes of downtime in one year.
Database & functional migration. Step 4: Smart Database Migration. Database migration would deserve a blog post on its own as there are so many questions we can answer with Dynatrace data to ensure a successful migration. Which applications and services are depending on a database that might be impacted by a migration?
Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. Improved error handling for unexpected storage issues. (APM-360014).
If you ever had to make a quick ad-hoc backup of your MongoDB databases, but there was not enough disk space on the local disk to do so, this blog post may provide some handy tips to save you from headaches. Fortunately, there are ways to skip the local storage entirely and stream MongoDB backups directly to the destination.
With MySQL point-in-time recovery , you can restore your database to the moment before the problem occurs. Preparation for PITR is crucial and involves enabling binary logging and creating a full database backup. STATEMENT level – at which only SQL statements causing changes in data are documented succinctly.
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. By default, MongoDB provides a snappy block compression method for storage and network communication.
Millions of tiny databases , Brooker et al., It takes you through the thinking processes and engineering practices behind the design of a key part of the control plane for AWS Elastic Block Storage (EBS): the Physalia database that stores configuration information. NSDI’20. This paper is a real joy to read.
The goal is to simplify the provisioning and management of database capacity. One approach is to separate compute and storage to allow for independent scaling. By separating storage and compute, Neon replaces the PostgreSQL storage layer with data nodes, and compute nodes are distributed across a cluster of nodes.
Since a few days ago this weblog serves 100% of its content directly out of the Amazon Simple Storage Service (S3) without the need for a web server to be involved. This enables Amazon S3 to know what document to serve if one isnt explicitly requested: for example [link]. Driving Storage Costs Down for AWS Customers.
In the Home Dashboard of PMM, a low CPU utilization on any of the database services that are being monitored could mean that the server is inactive or over-provisioned. From AWS documentation , Amazon EBS is an easy-to-use, scalable, high-performance block-storage service designed for Amazon EC2.
pgBackrest on the Main site streams backups and Write Ahead Logs (WALs) to the object storage. Configure main site Use your favorite method to deploy the Operator from our documentation. Once installed, configure the Custom Resource manifest so that pgBackrest starts using the Object Storage of your choice.
Once you finally find useful identifiers, you may begin writing SQL queries against your production database to find out what went wrong. Prodicle Distribution Prodicle Distribution allows a production office coordinator to send secure, watermarked documents, such as scripts, to crew members as attachments or links, and track delivery.
These functions can connect with supported cloud databases, such as Cloud SQL and Bigtable. Functions integrate with APIs (such as the Video Intelligence API ) to make this possible, forming a processing chain that eventually commits data to cloud storage. GCF use cases. Using GCF within a video analysis workflow.
Managing vast datasets effectively is an essential requirement for modern applications, and MongoDB , a leading NoSQL database, offers robust solutions for this requirement. Offset-based involves utilizing functions such as skip , limit and a query which indicates how many documents should be skipped or returned at maximum.
Our system doesn’t require strict consistency guarantees and does not use database transactions. Evaluation of migration completeness: To verify the completeness of the records, cold storage services are used to take periodic data dumps from the two data stores and compared for completeness.
Here, we will discuss a notable new feature in Amazon RDS, the Dedicated Log Volume (DLV), that has been introduced to boost database performance. A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content