This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. You can even walk through the same example above.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Similar to the tutorial extension, we created an extension that performs queries against databases.
This combination allows a malicious actor with local administrative privileges on a virtual machine to execute code as the virtual machine’s VMX process running on the host. It allows a malicious actor with privileges within the VMX process to trigger an arbitrary kernel write, which can lead to an escape from the sandbox.
As cloud applications have become the norm, the databases that power these applications are now typically run as managed services by cloud providers. Optimize database performance. Small changes in a database can have an enormous impact on overall application performance. Log monitoring beyond cloud platform databases.
NoSQL databases are often compared by various non-functional criteria, such as scalability, performance, and consistency. At the same time, NoSQL data modeling is not so well studied and lacks the systematic theory found in relational databases. Documentdatabases advance the BigTable model offering two significant improvements.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Start your free trial today!
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Using a low-code visual workflow approach, organizations can orchestrate key services, automate critical processes, and create new serverless applications. Improving data processing.
ScyllaDB is an open-source distributed NoSQL data store, reimplemented from the popular Apache Cassandra database. We’ve heard a lot about this rising database from the DBA community and our users, and decided to become a sponsor for this years Scylla Summit to learn more about the deployment trends from its users.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. Store these chunks in a vector database, indexed by their embedding vectors. While the overall process may be more complicated in practice, this is the gist. at Facebook—both from 2020.
A common question that I get is why do we offer so many database products? To do this, they need to be able to use multiple databases and data models within the same application. Seldom can one database fit the needs of multiple distinct use cases. Seldom can one database fit the needs of multiple distinct use cases.
Your companys AI assistant confidently tells a customer its processed their urgent withdrawal requestexcept it hasnt, because it misinterpreted the API documentation. These are systems that engage in conversations and integrate with APIs but dont create stand-alone content like emails, presentations, or documents.
Dynatrace Grail™ is a data lakehouse optimized for high performance, automated data collection and processing, and queries of petabytes of data in real time. Retention-based deletion is governed by a policy outlining the duration for which data is stored in the database before it’s deleted automatically.
Real-world context: Determine if vulnerabilities are linked to internet-facing systems or databases to help you prioritize the vulnerabilities that pose the greatest risk. For example, you might create a segment that tracks vulnerabilities in your payment processing system separately from general infrastructure assets.
You can find additional deployment options in the OpenTelemetry demo documentation. For details, see Dynatrace API – Tokens and authentication in theDynatrace documentation. To set up the demo using Docker , follow the steps below. If you don’t have one, you can use a trial account.
MySQL is a free open source relational database management system that is leveraged across a majority of WordPress sites, and allows you to query your data such as posts, pages, images, user profiles, and more. Managing a database is hard, as it needs continuous updating, tuning, and monitoring to ensure the performance of your website.
The latest batch of services cover databases, networks, machine learning and computing. Amazon Database Migration Service. Amazon Quantum Ledger Database (QLDB). Ensure high application performance by easily troubleshooting Amazon Neptune graph database. Achieve full observability of all AWS services. Available Now.
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Java, Go, and Node.js
The risk of impact from an existing known vulnerability also depends on whether certain processes are using the vulnerable parts of a software component. Process group 1 doesn’t use the function that contains the vulnerability. The vulnerable function in the software package is highlighted in red. an RCE vulnerability.
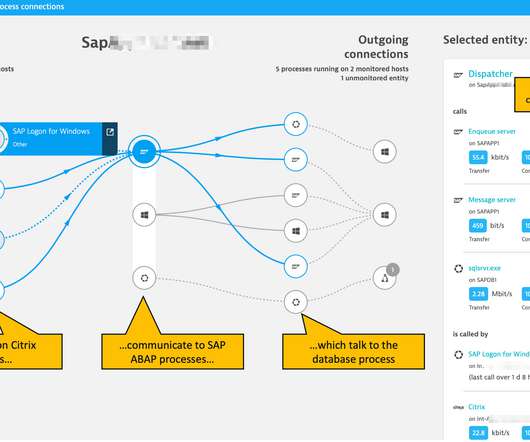
Collected metrics are analyzed in Dynatrace, using the SAP expert community’s established best-practice advice on ABAP platform health indicators, including response time breakdowns of the response times between ABAP-specific application server activities, tasks, and database interaction. SAP technology and process awareness.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. According to 2023 statistics, 49% of web applications use an SQL-based database , with SQL having a 75% adoption rate in the IT industry.
JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. Why should a relational database even care about unstructured data? Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSON database in 9.2
In that environment, the first PostgreSQL developers decided forking a process for each connection to the database is the safest choice. It would be a shame if your database crashed, after all. On modern Linux systems, the difference in overhead between forking a process and creating a thread is much lesser than it used to be.
The definition of Percona Advisors by ChatGPT is the following: Percona Advisors can help organizations implement robust security measures to protect their databases and sensitive data. Percona Advisors is an open source framework, meaning you can create your own checks by following our documentation. It is partially true.
By transacting with a database which is monitored by a CDC connector that creates events, or b. A GraphQL processor executes the user provided GraphQL query to fetch documents from the federated gateway. Writing an Avro schema for such a document is time consuming and error prone to do by hand.
For example, each deliverable in the project, like the requirements, design, code, documents, user interface, etc., Testing can also be divided based on the sub-stages or activities in testing, for instance, test case generation and design, test case execution and verification building of the testing database, etc. should be tested.
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. Let’s explore each of these elements and what organizations can do to avoid them.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
Deploying software in Kubernetes is often viewed as a straightforward process—just use kubectl or a GitOps solution like ArgoCD to deploy a YAML file, and you’re all set, right? External dependencies Many applications rely on external services, such as databases, APIs, or third-party services.
Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) data processing purposes, e.g. Machine Learning model building and scoring. For more information on this and other examples please visit the Dataflow documentation page."
Specifically, how our team uses the relationships and schemas defined within GraphQL to automatically build and maintain a search database. Each service could potentially implement its own search database, but then we would still need an aggregator. The data needs to be stored in a search database for quick retrieval.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA automates repetitive cloud operations tasks and streamlines the flow of analytics into decision-making processes.
Heck, typing “database migration plan” into Google and reading this blog could constitute planning. In brief, a proper database migration plan includes: Establishing clear objectives: Define what you want to achieve and how open source will get there. Use ETL (Extract, Transform, Load) tools to assist with this process.
Collected metrics are analyzed in Dynatrace, using the SAP expert community’s established best-practice advice on ABAP platform health indicators, including response time breakdowns of the response times between ABAP-specific application server activities, tasks, and database interaction. SAP technology and process awareness.
I believe that self-documenting architecture would dramatically reduce one of the big costs in software development. Everybody talks about self-documenting code, but that only applies in the small. Why not self-documenting architecture? It is a database of domain, business, and architectural information.
Secondly, knowing who is responsible is essential but not sufficient, especially if you want to automate your triage process. As teams and their structure and metadata are often maintained in a dedicated database, such as Microsoft Entra ID (formerly Azure Active Directory) or ServiceNow.
Logs include critical information that can’t be found elsewhere, like details on transactions, processes, users, and environment changes. Starting with user interactions, PurePath technology automatically collects all code execution details, executed database statements, critical transaction-based metrics, and topology information end-to-end.
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes. To understand what this means, let’s first look at two of the core concepts: observability and telemetry.
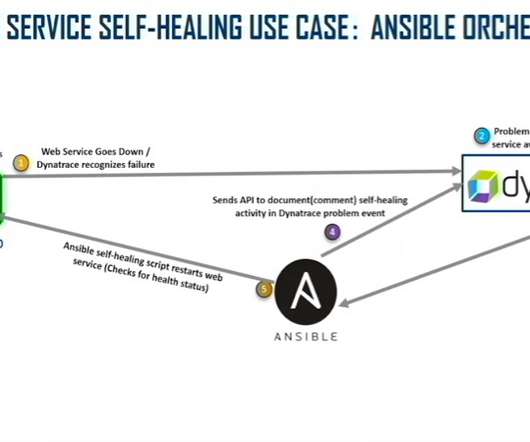
An AIOps stack featuring Dynatrace, ServiceNow, and Ansible automates and shortens that process for Lockheed Martin, Walker and Swofford explain. Each piece of the AIOps triumvirate plays a crucial role in the automation process to speed innovation. Ansible sends an API to document self-healing IT activity in Dynatrace.
Migrating a proprietary database to open source is a major decision that can significantly affect your organization. It’s a complex process involving various factors and meticulous planning. Flexibility and scalability Open source databases provide much greater flexibility regarding customization and configuration.
Organizations are shifting towards cloud-native stacks where existing application security approaches can’t keep up with the speed and variability of modern development processes. When Dynatrace automatically detects a vulnerable library, it also identifies all processes affected by this vulnerability to assess the risk.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Triggering repairs at any time.
The use of open source databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “open source database” really is and what it offers. What is an open source database?
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
I played a bit with ChatGPT in February to see how it would respond to random database-related inquiries, and I found it pretty impressive and annoying at the same time. This streamlined process reduces the risk of errors and simplifies the downgrade procedure. implemented improved data integrity checks during the downgrade process.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content