This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Summary Ensuring fault tolerance in data-intensive, event-driven applications is crucial for successful industry deployments.
Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. Data scientists at Netflix relish our culture that empowers them to work autonomously and use their judgment to solve problems independently. How could we improve the quality of life for data scientists?
For softwareengineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is a shortlist to get you started.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. Why: Data Makes It Different. All ML projects are software projects. The new category is often called MLOps.
Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. Data scientists at Netflix relish our culture that empowers them to work autonomously and use their judgment to solve problems independently. How could we improve the quality of life for data scientists?
From chaos architecture to event streaming to leading teams, the O'Reilly SoftwareArchitecture Conference offers a unique depth and breadth of content. We received more than 200 abstracts for talks for the 2018 O'Reilly SoftwareArchitecture Conference in London—on both expected and surprising topics.
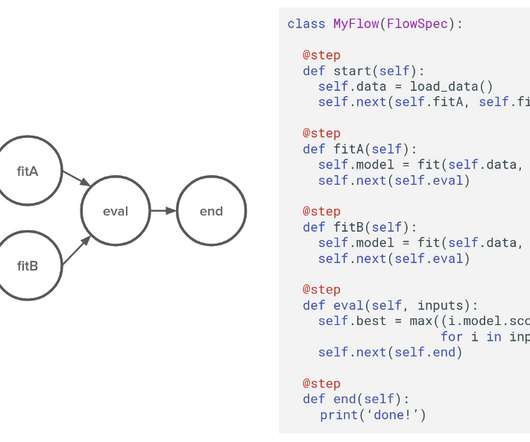
First, the behavior of an AI application depends on a model , which is built from source code and training data. A model isn’t source code, and it isn’t data; it’s an artifact built from the two. You need a repository for models and for the training data. Models almost certainly react to incoming data; that’s their point.
Gatekeeper accomplishes its prescribed task by aggregating data from multiple upstream systems, applying some business logic, then producing an output detailing the status of each video in each country. And obviously, if you get a 100% hit rate, you eliminate all I/O required to access your data?—?and
More than a fifth of the respondents work in the software industry—skewing results toward the concerns of software companies, and helping explain the preponderance of those with softwareengineering roles. The chart packs in a lot of data. As noted earlier, the majority of survey respondents are softwareengineers.
A lot happened between January and the first week of March, when we got around to analyzing our survey data. More than one-third have adopted site reliability engineering (SRE); slightly less have developed production AI services. Softwareengineers represent the largest cohort, comprising almost 20% of all respondents (see Figure 1 ).
An erroneous trajectory was computed using this incorrect data. million on this mission and have the probe crash into the Martian atmosphere because two teams of softwareengineers, who both wrote great code, did not communicate together and did not follow specifications.
The engineering organisation described may not work for you because of a team of 8-10 people is still a very big overhead. In this model, softwarearchitecture and code ownership is a reflection of the organisational model. Is it possible to draw inspiration from outside of softwareengineering? Probably yes.
The second transaction will fail because the database can see that changes were made to the aggregate inside first transaction and it might not be safe to commit to the second transaction without overwriting data from the first transaction. This is known as optimistic concurrency. It seems like the problem is solved. Hope to see you there.
Entirely new paradigms rise quickly: cloud computing, dataengineering, machine learning engineering, mobile development, and large language models. To further complicate things, topics like cloud computing, software operations, and even AI don’t fit nicely within a university IT department.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content