This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To understand whats happening in todays complex software ecosystems, you need comprehensive telemetry data to make it all observable. With so many types of technologies in software stacks around the globe, OpenTelemetry has emerged as the de facto standard for gathering telemetry data. But, generating telemetry data is the easy part.
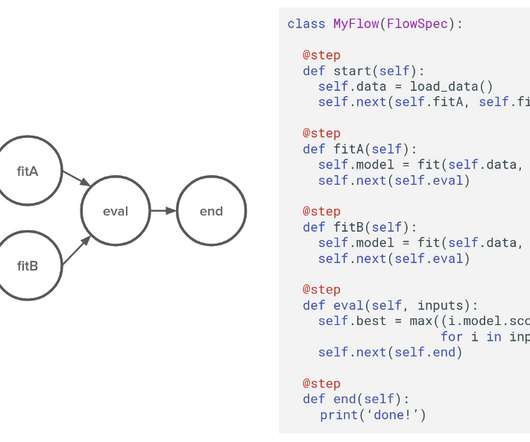
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. How could we improve the quality of life for data scientists?
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
These are just a few of the open-source technologies you may encounter as you research observability solutions for managing complex multicloud IT environments and the services that run on them. Of these open-source observability tools, one stands out. Source: OpenTelemetry Documentation. What is telemetry data?
For example, a supported syslog component must support the masking of sensitive data at capture to avoid transmitting personally identifiable information or other confidential data over the network. Log batching, enrichment, transformation, log source distinction, and application offloading are also regular requirements.
In today's data-driven world, efficient data processing plays a pivotal role in the success of any project. Apache Spark , a robust open-sourcedata processing framework, has emerged as a game-changer in this domain.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. DJ stands out as an opensource solution that is actively developed and stress-tested at Netflix.
It is an open standard format which organizes data into key/value pairs and arrays detailed in RFC 7159. JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. You can also check out our Working with JSON Data in PostgreSQL vs. JSONB Patterns & Antipatterns.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Thus, Grail was born.
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. How could we improve the quality of life for data scientists?
Netflix has open-sourced Escrow Buddy, which helps Security and IT teams ensure they have valid FileVault recovery keys for all their Macs in MDM. The agent also enables rotation of recovery keys after use, local storage and validation of recovery keys, and other features.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. However, there are many obstacles and limitations along the way to becoming a data-driven organization. Understanding the context.
With our latest enhancements, were transforming the way you work with trace data. For deeper exploration, our Distributed Tracing app empowers you to analyze raw trace data and uncover insights, whether troubleshooting errors, optimizing performance, or discovering the unknown unknowns. But why stop there?
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes. What is RabbitMQ? What is Apache Kafka?
Software and data are a company’s competitive advantage. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. The only way to address these challenges is through observability data — logs, metrics, and traces. Teams interact with myriad data types.
Store the data in an optimized, highly distributed datastore. Additionally, some collectors will instead poll our kafka queue for impressions data. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. Track real-time title impressions from the NetflixUI.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Open-source software drives a vibrant Kubernetes ecosystem. Java, Go, and Node.js
BindPlane OP is a powerful open-source tool that makes it easy to build and manage telemetry pipelines to ship data from IT environments of any kind and size to any analysis tool or storage destination. The vendor-agnostic toolset is excellent for reducing data costs and getting the most out of your data.
The use of opensource databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “opensource database” really is and what it offers. What is an opensource database?
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer on the Product Data Science and Engineering team.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Migrating a proprietary database to opensource is a major decision that can significantly affect your organization. Advantages of migrating to opensource For many reasons mentioned earlier, organizations are increasingly shifting towards opensource databases for their data management needs.
PostgreSQL graphical user interface (GUI) tools help these opensource database users to manage, manipulate, and visualize their data. Offers great visualization to help you interpret your data. The window-based interface makes it much easier to manage your PostgreSQL data. pgAdmin Cost: Free (opensource).
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
Kubernetes has become the leading container orchestration platform for organizations adopting opensource solutions to manage, scale, and automate application deployment. Kubernetes is an opensource container orchestration platform for managing, automating, and scaling containerized applications. What is Kubernetes?
This blog post explores the benefits of combining both open-source frameworks, shows unique differentiators of Flink versus Kafka, and discusses when to use a Kafka-native streaming engine like Kafka Streams instead of Flink.
Fluentd is an open-sourcedata collector that unifies log collection, processing, and consumption. Output plugins deliver logs to storage solutions, analytics tools, and observability platforms like Dynatrace. All metrics, traces, and real user data are also surfaced in the context of specific events.
The unstoppable rise of opensource databases. One database in particular is causing a huge dent in Oracle’s market share – opensource PostgreSQL. See how opensource PostgreSQL Community version costs compare to Oracle Standard Edition and Oracle Enterprise Edition. What’s causing this massive shift?
Troubleshooting a session in Edgar When we started building Edgar four years ago, there were very few open-source distributed tracing systems that satisfied our needs. Our tactical approach was to use Netflix-specific libraries for collecting traces from Java-based streaming services until opensource tracer libraries matured.
Historically artists had these machines built for them at their desks and only had access to the data and applications when they were in the office. Machine Configuration: Spinnaker Starting at the left of the chart, Spinnaker is an open-source platform that controls the creation of workstation pools.
Security analytics combines data collection, aggregation, and analysis to search for and identify potential threats. Using a combination of historical data and information collected in real time, security teams can detect threats earlier in the SDLC. Here’s how. What is security analytics? Why is security analytics important?
Managing storage and performance efficiently in your MySQL database is crucial, and general tablespaces offer flexibility in achieving this. In contrast to the single system tablespace that holds system tables by default, general tablespaces are user-defined storage containers for multiple InnoDB tables.
Here we present a list of 10 open-source Kubernetes tools to make your SRE and Ops teams more effective to achieve their service level objectives. The backup files are stored in an object storage service (e.g. Ark server performs the actual backup, validates it and loads backup files in cloud object storage. Telepresence.
The complexity of such deployments has accelerated with the adoption of emerging, open-source technologies that generate telemetry data, which is exploding in terms of volume, speed, and cardinality. Entity tagging requires an enormous amount of manual effort and is always open to interpretation.
Kubernetes is an opensource container orchestration platform that enables organizations to automatically scale, manage, and deploy containerized applications in distributed environments. Like Kubernetes, OpenShift is an opensource Kubernetes-based container platform. What is Kubernetes? What is OpenShift?
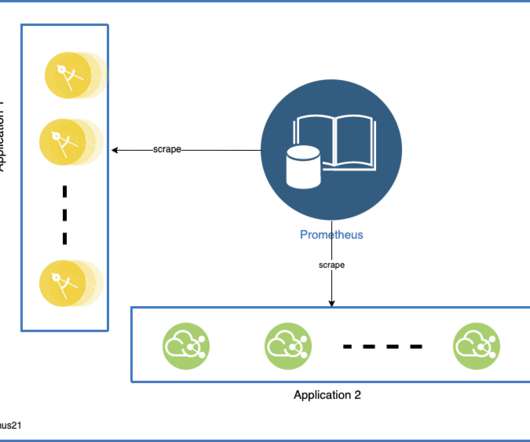
Prometheus is an open-source system monitoring and alerting toolkit. Data related to monitoring is stored in RAM and LevelDB nevertheless data can be stored to other storage systems such as ElasticSearch, InfluxDb, and others, [link]. Watch out for your self-destructing apps!
Prometheus is an open-source monitoring and alerting toolkit for services and applications that run in containers. It offers a flexible multidimensional data model that’s based on key-value pairs and a potent query language (PromQL). Dynatrace news. What is Prometheus and how does it work?
Since database hosting is more dependent on memory (RAM) than storage, we are going to compare various instance sizes ranging from just 1GB of RAM up to 64GB of RAM so you can see how costs vary across different application workloads. ScaleGrid provides an Import wizard to migrate data from one cluster to another. EC2 instances.
One option is to install OneAgent on that syslog server, which automatically discovers, instruments and sends the log data to the Dynatrace platform. Yet observability into syslog data on Dynatrace would help you monitor and troubleshoot infrastructure. In Cribl’s configuration, open “Data/Destinations” and find “Webhook.”
By Gim Mahasintunan on behalf of Data Platform Engineering. Supporting a rapidly growing base of engineers of varied backgrounds using different data stores can be challenging in any organization. In this blog post, we are thrilled to share that we are open-sourcing one such tool: the Netflix Data Explorer.
Problems include provisioning and deployment; load balancing; securing interactions between containers; configuration and allocation of resources such as networking and storage; and deprovisioning containers that are no longer needed. Originally created by Google, Kubernetes was donated to the CNCF as an opensource project.
With these release candidate APIs available, instrumentation for web frameworks, storage clients, and much more can be built. We at Dynatrace understand the importance of contributing our expertise in enterprise-grade intelligent observability to the opensource community. Dynatrace fully embraces OpenTelemetry.
They've posted about Anna's new superpowers in Going Fast and Cheap: How We Made Anna Autoscale : Using Anna v0 as an in-memory storage engine, we set out to address the cloud storage problems described above. Each storage server collects statistics about the requests it serves, the data it stores, etc.
Many AWS services and third party solutions use AWS S3 for log storage. Centralized log management for scalable ingestion into Grail As AWS S3 proves to be the preferred way of storing cloud logs, enterprise customers face mounting challenges in putting S3 log data to use.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content