This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
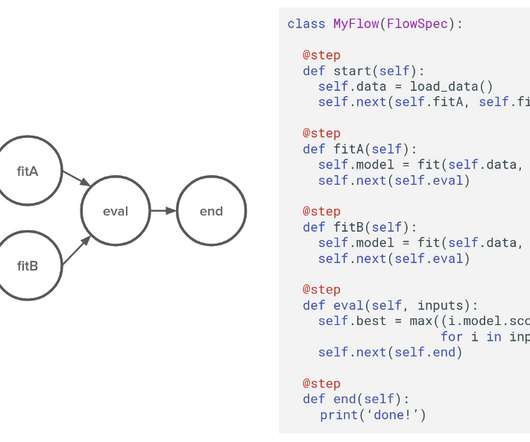
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. How could we improve the quality of life for data scientists?
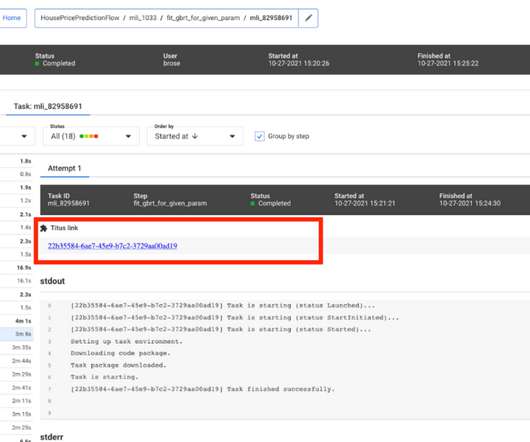
Open-Sourcing a Monitoring GUI for Metaflow, Netflix’s ML Platform tl;dr Today, we are open-sourcing a long-awaited GUI for Metaflow. The Metaflow GUI allows data scientists to monitor their workflows in real-time, track experiments, and see detailed logs and results for every executed task.
Today’s organizations are constantly enhancing their systems and services as new opportunities arise, inspiring new forms of collaboration while relying on open ecosystems and opensource software. To realize the benefits of open ecosystems, organizations must plan for ecosystem-level observability.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
OpenTelemetry standardizes how organizations instrument, generate, and collect telemetry data for analysis and provides community-based support. Because of its flexibility, this opensource approach to instrumenting and collecting telemetry data is becoming increasingly important in large-size organizations.
The newly introduced step-by-step guidance streamlines the process, while quick data flow validation accelerates the onboarding experience even for power users. After successfully installing OneAgent, the log ingestion wizard provides a host selector drop-down to validate the data flow. The API-based approach is the most flexible.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. DJ stands out as an opensource solution that is actively developed and stress-tested at Netflix.
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. How could we improve the quality of life for data scientists?
Structured Query Language (SQL) is a simple declarative programming language utilized by various technology and business professionals to extract and transform data. Visualization & Reporting: Can the tool generate reports or visual representations like ER diagrams, data charts, or query execution plans?
Redis , short for Remote Dictionary Server, is a BSD-licensed, open-source in-memory key-value data structure store written in C language by Salvatore Sanfillipo and was first released on May 10, 2009. Instead, Redis stores data in data structures which makes it very flexible to use. Data Structures in Redis.
Ready to transition from a commercial database to opensource, and want to know which databases are most popular in 2019? Wondering whether an on-premise vs. public cloud vs. hybrid cloud infrastructure is best for your database strategy?
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Failures are injected using Chaos Mesh , an opensource chaos engineering platform integrated with Kubernetes deployment.
We are a company of opensource proponents. We’re also dedicated and active participants in the global opensource community. Both opensource and proprietary options have advantages. With opensource database software , anyone in the general public can access the source code, read it, and modify it.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes. What is RabbitMQ? What is Apache Kafka?
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Thus, Grail was born.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. However, there are many obstacles and limitations along the way to becoming a data-driven organization. Understanding the context.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Open-source software drives a vibrant Kubernetes ecosystem. Java, Go, and Node.js
The use of opensource databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “opensource database” really is and what it offers. What is an opensource database?
In this article, I’m going to demonstrate how you can migrate a comprehensive web application from MySQL to YugabyteDB using the open-sourcedata migration engine YugabyteDB Voyager. This helps improve availability, scalability, and performance.
Store the data in an optimized, highly distributed datastore. Additionally, some collectors will instead poll our kafka queue for impressions data. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. Track real-time title impressions from the NetflixUI.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. In the Reliability space, our data teams focus on two main approaches.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. Organizations usually implement observability using a combination of instrumentation methods including open-source instrumentation tools, such as OpenTelemetry.
The unstoppable rise of opensource databases. One database in particular is causing a huge dent in Oracle’s market share – opensource PostgreSQL. See how opensource PostgreSQL Community version costs compare to Oracle Standard Edition and Oracle Enterprise Edition. What’s causing this massive shift?
Migrating a proprietary database to opensource is a major decision that can significantly affect your organization. Advantages of migrating to opensource For many reasons mentioned earlier, organizations are increasingly shifting towards opensource databases for their data management needs.
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Docker Engine is built on top containerd , the leading open-source container runtime, a project of the Cloud Native Computing Foundation (DNCF). What is Docker? What is Kubernetes?
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Many organizations are turning to opensource solutions to streamline their operations and reduce costs. Opensource migration can be a game-changer, offering flexibility, scalability, and cost-effectiveness. Common pitfalls when migrating to opensource Lack of proper planning Proper is the operative word here.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
With our latest enhancements, were transforming the way you work with trace data. For deeper exploration, our Distributed Tracing app empowers you to analyze raw trace data and uncover insights, whether troubleshooting errors, optimizing performance, or discovering the unknown unknowns. But why stop there?
can be an advantage when you’re looking for data science jobs, but unless you really want to 1) do research or 2) be a professor there’s no really no benefit to getting a Ph.D. Consume Explain the Cloud Like I'm 10 (35 nearly 5 star reviews). I think that having a Ph.D. Strong technologies adapt the world to themselves.
Apache Spark is a powerful open-source distributed computing framework that provides a variety of APIs to support big data processing. In addition, pySpark applications can be tuned to optimize performance and achieve better execution time, scalability, and resource utilization.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several datasources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Elasticsearch is an open-source search engine and analytics store used by a variety of applications from search in e-commerce stores, to internal log management tools using the ELK stack (short for “Elasticsearch, Logstash, Kibana”).
Opensource has also become a fundamental building block of the entire cloud-native stack. While leveraging cloud-native platforms, open-source and third-party libraries accelerate time to value significantly, it also creates new challenges for application security.
According to the 2019 Verizon Data Breach Investigations Report, web application attacks were the number one type of attack. Data from Forrester Research provides more detail, finding that 39% of all attacks were designed to exploit vulnerabilities in web applications. And open-source software is rife with vulnerabilities.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. Therefore, dumps are needed to capture the full state of a source. Designed with High Availability in mind.
At the same time, you can now simply flip a switch to begin ingesting observability data from these tools into the Dynatrace platform, all while retaining your investment and increasing the value you get from Dynatrace. Open-source metric sources automatically map to our Smartscape model for AI analytics.
While not the first opensource content management system (CMS), WordPress caught on like nothing before and helped spread opensource to millions. It was simple, easy to deploy, and easy to use, and WordPress had the added benefit of being opensource. MySQL was founded in 1995 and went opensource in 2000.
2 billion : Pokémon GO revenue since launch; 10 : say happy birthday to StackOverflow; $148 million : Uber data breach fine; 75% : streaming music industry revenue in the US; 5.2 Then please recommend my well reviewed book: Explain the Cloud Like I'm 10. They'll love it and you'll be their hero forever. $2 seconds with the system.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. Therefore, dumps are needed to capture the full state of a source. Designed with High Availability in mind.
After a decade of helping companies manage container orchestration, Kubernetes, the opensource container platform, has established itself as a mature enterprise technology. The average deployment now spans 20 clusters running 10 or more software elements across clouds and data centers. Immediate entry. Automated notifications.
The complexity of such deployments has accelerated with the adoption of emerging, open-source technologies that generate telemetry data, which is exploding in terms of volume, speed, and cardinality. How can we optimize for performance and scalability? Contextualization is one of the biggest challenges of observability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content