This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s world where data drives everything, managing large-scale databases and their security is both a necessity and a challenge. An open-source database is your best bet for many reasons. Most organizations are now adopting open-source databases for some projects.
Although many companies adopt solutions such as OpenTelemetry, Prometheus, and Grafana as part of their observability strategy, they often confront a common data analysis problem: data silos. When teams, tools, and data are siloed, it’s harder for organizations to succeed. This leads to multiple tool-specific dashboards.
Because opensource software (OSS) is taking over the world, optimizing opensource contributions is becoming an essential competitive strategy. However, opensource is not a panacea. These considerations are important if developers want to maximize the impact of their contributions to opensource projects.
To understand whats happening in todays complex software ecosystems, you need comprehensive telemetry data to make it all observable. With so many types of technologies in software stacks around the globe, OpenTelemetry has emerged as the de facto standard for gathering telemetry data. But, generating telemetry data is the easy part.
One of the things I love most about OpenTelemetry (OTel) is that its vendor-neutral, which means you can send the same OpenTelemetry data to different vendors. In fact, most of the major Observability vendors out there not only support ingesting OpenTelemetry data but also actively contribute to the project, including Dynatrace.
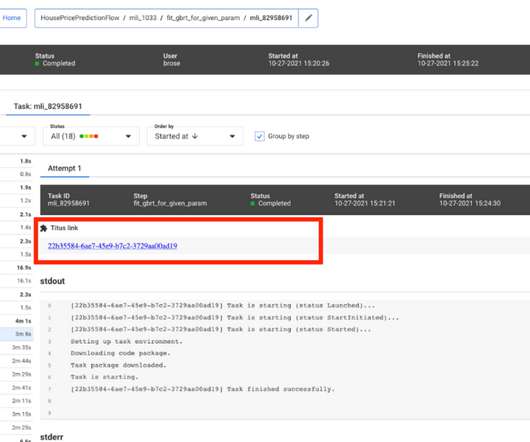
Open-Sourcing a Monitoring GUI for Metaflow, Netflix’s ML Platform tl;dr Today, we are open-sourcing a long-awaited GUI for Metaflow. The Metaflow GUI allows data scientists to monitor their workflows in real-time, track experiments, and see detailed logs and results for every executed task.
Opensource software has become a key standard for developing modern applications. From common coding libraries to orchestrating container-based computing, organizations now rely on opensource software—and the open standards that define them—for essential functions throughout their software stack.
Today’s organizations are constantly enhancing their systems and services as new opportunities arise, inspiring new forms of collaboration while relying on open ecosystems and opensource software. To realize the benefits of open ecosystems, organizations must plan for ecosystem-level observability.
These are just a few of the open-source technologies you may encounter as you research observability solutions for managing complex multicloud IT environments and the services that run on them. Of these open-source observability tools, one stands out. Source: OpenTelemetry Documentation. What is telemetry data?
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This is why were excited to announce the launch of Dynatrace Live Debugger , a revolutionary tool that provides developers with visibility and data access to their running applications. Browse your code.
For example, a supported syslog component must support the masking of sensitive data at capture to avoid transmitting personally identifiable information or other confidential data over the network. Log batching, enrichment, transformation, log source distinction, and application offloading are also regular requirements.
As organizations strive for observability and data democratization, OpenTelemetry emerges as a key technology to create and transfer observability data. This collector, fully supported and maintained by Dynatrace, is entirely opensource. A collector helps developers control their telemetry data streams for each signal.
In today's data-driven world, efficient data processing plays a pivotal role in the success of any project. Apache Spark , a robust open-sourcedata processing framework, has emerged as a game-changer in this domain.
In this hands-on lab from ScyllaDB University, you will learn how to use the ScyllaDB CDC source connector to push the row-level changes events in the tables of a ScyllaDB cluster to a Kafka server. and ScyllaDB OpenSource 4.3. What Is ScyllaDB CDC? CDC is production-ready (GA) starting from ScyllaDB Enterprise 2021.1.1
The newly introduced step-by-step guidance streamlines the process, while quick data flow validation accelerates the onboarding experience even for power users. After successfully installing OneAgent, the log ingestion wizard provides a host selector drop-down to validate the data flow. The API-based approach is the most flexible.
Structured Query Language (SQL) is a simple declarative programming language utilized by various technology and business professionals to extract and transform data. Visualization & Reporting: Can the tool generate reports or visual representations like ER diagrams, data charts, or query execution plans?
Netflix has open-sourced Escrow Buddy, which helps Security and IT teams ensure they have valid FileVault recovery keys for all their Macs in MDM. To be a client systems engineer is to take joy in small endpoint automations that make your fellow employees’ day a little better.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. DJ stands out as an opensource solution that is actively developed and stress-tested at Netflix.
OpenTelemetry (OTel) is an opensource framework for generating, ingesting, transforming, and exporting telemetry data. Backed by most of the industrys major observability vendors, OpenTelemetry has become one of the CNCF s most active opensource projects, second only to Kubernetes. And why shouldnt we?
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Failures are injected using Chaos Mesh , an opensource chaos engineering platform integrated with Kubernetes deployment.
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. With the latest Data Mesh Platform, data movement in Netflix Studio reaches a new stage.
Monitoring Time-Series IoT Device Data Time-series data is crucial for IoT device monitoring and data visualization in industries such as agriculture, renewable energy, and meteorology. In this tutorial, we will guide you through the process of setting up a monitoring system for IoT device data.
Whether youre a developer, database administrator, or data analyst, a good GUI can make everyday tasks faster, clearer, and less error-prone. Its built for users who want more than just basic queryingNavicat includes tools for data modeling, automation, team collaboration, and cloud integrations. Thats where MySQL GUIs come in.
In today’s data-driven world, businesses across various industry verticals increasingly leverage the Internet of Things (IoT) to drive efficiency and innovation. Dynatrace offers a feature-rich agent, Dynatrace OneAgent ® , and an agentless opensource approach perfectly tailored for edge-IoT use cases, leveraging OpenTelemetry.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Thus, Grail was born.
PostgreSQL is, without a doubt, one of the most popular opensource databases in the world. Well, there are many reasons, but if I had to pick just one, I’d say its extensibility. PostgreSQL isnt just a database; its an ecosystem of extensions that can transform it to tackle any upcoming challenges. By enabling […]
Modern IT organizations are generating more data from more tools and technologies than ever. Data is proliferating in separate silos from containers and Kubernetes to opensource APIs and software to serverless compute services, such as AWS and Azure. However, they had numerous custom applications with separate APIs.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. However, there are many obstacles and limitations along the way to becoming a data-driven organization. Understanding the context.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Open-source software drives a vibrant Kubernetes ecosystem. Java, Go, and Node.js
Those in the observability space are no strangers to OpenTelemetry (OTel) , a vendor-neutral, opensource project of the Cloud Native Computing Foundation (CNCF). Since its inception, it has become one of the CNCFs most active opensource projects second only to Kubernetes. However, gRPC is not yet supported. Learn more.
OpenTelemetry Astronomy Shop is a demo application created by the OpenTelemetry community to showcase the features and capabilities of the popular open-source OpenTelemetry observability standard. metrics from span data. Afterward, the demo starts instantly, and the load generator automatically begins creating data.
Software and data are a company’s competitive advantage. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. The only way to address these challenges is through observability data — logs, metrics, and traces. Teams interact with myriad data types.
It is an open standard format which organizes data into key/value pairs and arrays detailed in RFC 7159. JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. You can also check out our Working with JSON Data in PostgreSQL vs. JSONB Patterns & Antipatterns.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several datasources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. The rise of big data, cryptocurrencies, and AI means the IT sector contributes significantly to global greenhouse gas emissions. However, this trend is now reversing. The time to act is now.
You’re gathering a lot of data, but you can’t make sense of it. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. In practice, histograms are useful when the measurement distribution is relevant and the data sets are large.
This article is part of a series exploring a workshop guiding you through the opensource project Fluent Bit, what it is, a basic installation, and setting up the first telemetry pipeline project. Are you ready to get started with cloud-native observability with telemetry pipelines?
BindPlane OP is a powerful open-source tool that makes it easy to build and manage telemetry pipelines to ship data from IT environments of any kind and size to any analysis tool or storage destination. The vendor-agnostic toolset is excellent for reducing data costs and getting the most out of your data.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. Organizations usually implement observability using a combination of instrumentation methods including open-source instrumentation tools, such as OpenTelemetry.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content