This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we launched the new Dynatrace experience, we introduced major updates to the platform, including Grail ™, our innovative data lakehouse unifying observability, security, and business data, and Dynatrace Query Language ( DQL ) for accessing and exploring unified data.
When first working on a new site-speed engagement, you need to work out quickly where the slowdowns, blindspots, and inefficiencies lie. Gathering Data. Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages.
In 2019, according to Evans Data Corporation, there were 23.9 In an attempt to hold their place within the market, developers are having to speed their process up whilst delivering products of ever-increasing quality. Often speed and quality seem at odds with one another, but in reality, this isn’t the case.
AI transformation, modernization, managing intelligent apps, safeguarding data, and accelerating productivity are all key themes at Microsoft Ignite 2024. Adopting AI to enhance efficiency and boost productivity is critical in a time of exploding data, cloud complexities, and disparate technologies.
Welcome, data enthusiasts! Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. In this blog series, we’ll guide you through creating powerful dashboards that transform complex data into actionable insights.
We are in the era of data explosion, hybrid and multicloud complexities, and AI growth. Dynatrace analyzes billions of interconnected data points to deliver answers, not just data and dashboards sending signals without a path to resolution. Picture gaining insights into your business from the perspective of your users.
Metrics matter. As objective measurements, they allow us to make data-driven decisions. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. Metric calculations help you design custom dashboards that meet the requirements of specific teams. Dynatrace news.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
Performance, errors, and user experience Dynatrace has long understood the importance of performance as a foundational component of user experience and the impact that page speed and any friction introduced by errors have on user behavior. The addition of more and more metrics over time has only made this increasingly complex.
In today’s data-driven world, businesses across various industry verticals increasingly leverage the Internet of Things (IoT) to drive efficiency and innovation. Both methods allow you to ingest and process raw data and metrics. The ADS-B protocol differs significantly from web technologies.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Thus, Grail was born.
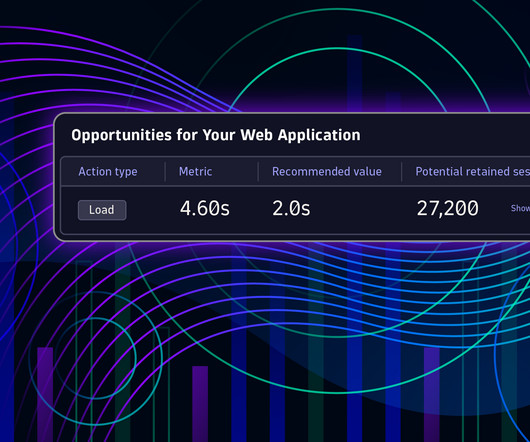
With Dynatrace, you can also validate your findings against Real User Monitoring data or even drill down to the code level to pinpoint the root cause of a change in performance. Recently introduced improvements to Visually complete and new web performance metrics for Real User Monitoring are now available for Synthetic Monitoring as well.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
Automating quality gates is ideal, as it minimizes manually checking and validating key metrics throughout the SDLC. By actively monitoring metrics such as error rate, success rate, and CPU load, quality gates instill confidence in teams during software releases. Several tools can be used to collect metrics in load/performance testing.
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
Grail: Enterprise-ready data lakehouse Grail, the Dynatrace causational data lakehouse, was explicitly designed for observability and security data, with artificial intelligence integrated into its foundation. Tables are a physical data model, essentially the type of observability data that you can store.
In a digital-first world, site reliability engineers and IT data analysts face numerous challenges with data quality and reliability in their quest for cloud control. Increasingly, organizations seek to address these problems using AI techniques as part of their exploratory data analytics practices.
Software and data are a company’s competitive advantage. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. The only way to address these challenges is through observability data — logs, metrics, and traces. Teams interact with myriad data types.
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Performance is usually a primary concern when using stream processing frameworks.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. This nuanced integration of data and technology empowers us to offer bespoke content recommendations. This queue ensures we are consistently capturing raw events from our global userbase.
I have ingested important custom data into Dynatrace, critical to running my applications and making accurate business decisions… but can I trust the accuracy and reliability?” ” Welcome to the world of data observability. At its core, data observability is about ensuring the availability, reliability, and quality of data.
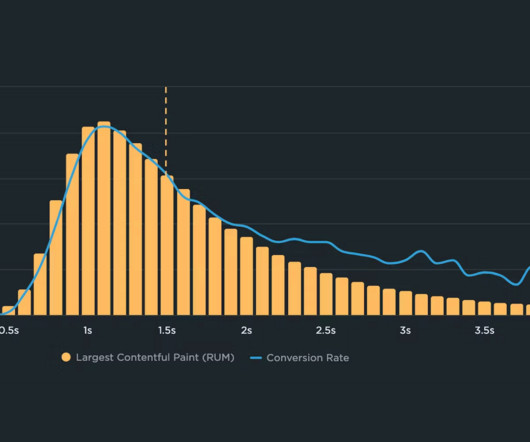
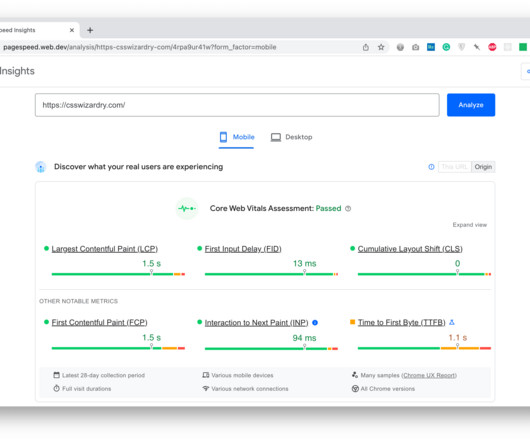
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
Redis , short for Remote Dictionary Server, is a BSD-licensed, open-source in-memory key-value data structure store written in C language by Salvatore Sanfillipo and was first released on May 10, 2009. Instead, Redis stores data in data structures which makes it very flexible to use. Data Structures in Redis.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. The New Decision Matrix: Beyond Performance Metrics Performance metrics are pivotal, no doubt. Factors like read and write speed, latency, and data distribution methods are essential.
If you could measure the impact of site speed on your business, how valuable would that be for you? Here's the truth: The business folks in your organization probably don't care about page speedmetrics. But that doesn't mean they don't care about page speed. Say hello to correlation charts – your new best friend.
Sure, we can glean plenty of insights about a site’s performance and even spot issues that ought to be addressed to speed things up. There are even many ways we can configure Lighthouse to measure performance in simulated situations, such as slow internet connection speeds or creating separate reports for mobile and desktop.
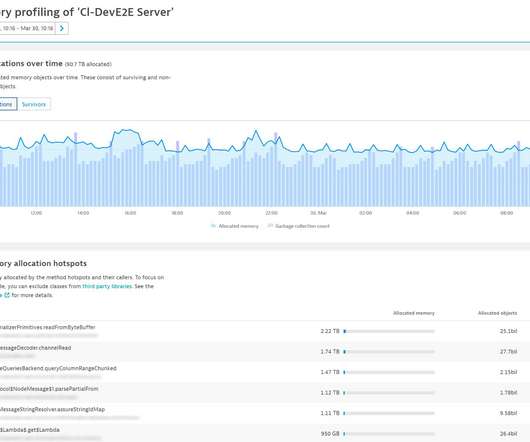
Any significant reduction in allocations will inevitably speed up your code. To see why, navigate to the Suspension chart on the JVM metrics tab. . By reducing the number of allocated objects, you can both speed up your code and reduce object churn and garbage collection events. Speed up application code itself.
This is an update to my 2020 article Site-Speed Topography. Around two and a half years ago, I debuted my Site-Speed Topography technique for getting broad view of an entire site’s performance from just a handful of key URLs and some readily available metrics. What Is Site-Speed Topography? Are any metrics over budget?
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Besides organizations wanting to learn how they can replicate the improvement in speed and quality, we keep hearing more questions around how we include security into our processes. As I love metrics and data driven decisions, I was all ears ??. 4 Steering efforts with data science. Next: A blog focusing on tooling.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes.
Annie leads the Chrome SpeedMetrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty SpeedMetrics team at Google.
Speed and scalability are significant issues today, at least in the application landscape. Among the critical enablers for fast data access implementation within in-memory data stores are the game changers in recent times, which are technologies like Redis and Memcached. However, the question arises of choosing the best one.
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. This data provides organizations with end-to-end visibility of the entire user journey across the tech stack. Speed index. Load event start. Load event end.
If you’re happy just to trust me, then this is all you need to know right now: Google takes URL-level Core Web Vitals data from CrUX into account when deciding where to rank you in a search results page. All Core Web Vitals data used to rank you is taken from actual Chrome-based traffic to your site. You should get in touch.
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
By Gim Mahasintunan on behalf of Data Platform Engineering. Supporting a rapidly growing base of engineers of varied backgrounds using different data stores can be challenging in any organization. In this blog post, we are thrilled to share that we are open-sourcing one such tool: the Netflix Data Explorer.
How does this affect your page speed, your Core Web Vitals, your search rank, your business, and most important – your users? For almost fifteen years, I've been writing about page bloat, its impact on site speed, and ultimately how it affects your users and your business. Keep scrolling for the latest trends and analysis.
As a full stack monitoring platform, Dynatrace collects a huge number of metrics for each OneAgent monitored host in your environment. Depending on the types of technologies you’re running on your individual hosts, the average number of metrics is about 500 per computational node. New metric identifiers and structure.
Seeking insights from data Every organization depends on data to make decisions. However, too often teams are forced to rely on disjointed data that lacks context, which leads to poor decision-making and wasted resources. This problem has worsened as enterprise operational complexity has grown.
Data proliferation—as well as a growing need for data analysis—has accelerated. According to recent Dynatrace data, 59% of CIOs say the increasing complexity of their technology stack could soon overload their teams without a more automated approach to IT operations. Digital transformation shows no signs of slowing down.
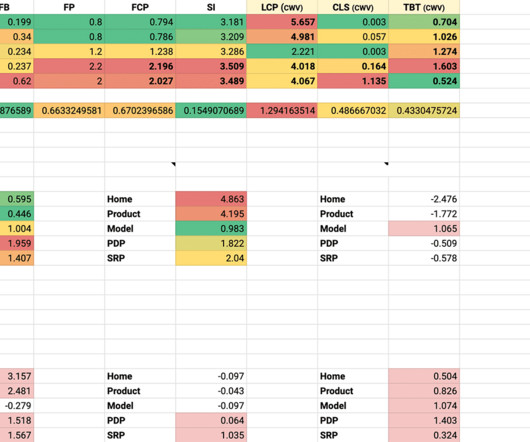
In the waterfall charts above, we notice we have both light and dark green in the CSS responses: the light green can be considered latency, while the dark green is when we’re actually downloading data. This is because, at present, algorithms like Gzip and Brotli become more effective the more historical data they have to play with.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content