This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we launched the new Dynatrace experience, we introduced major updates to the platform, including Grail ™, our innovative data lakehouse unifying observability, security, and business data, and Dynatrace Query Language ( DQL ) for accessing and exploring unified data.
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.
Cloud service providers (CSPs) share carbon footprint data with their customers, but the focus of these tools is on reporting and trending, effectively targeting sustainability officers and business leaders. We implemented a wasted energy metric in the app to enhance practitioner actionability.
Welcome, data enthusiasts! Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. In this blog series, we’ll guide you through creating powerful dashboards that transform complex data into actionable insights.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. However, your responsibilities might change or expand, and you need to work with unfamiliar data sets. Your trained eye can interpret them at a glance, a skill that sets you apart.
Exploratory analytics now cover more bespoke scenarios, allowing you to access any element of test results stored in the Dynatrace Grail data lakehouse. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. The new Dynatrace Synthetic app allows you to analyze these results.
Recently, I encountered a task where a business was using AWS Elastic Beanstalk but was struggling to understand the system state due to the lack of comprehensive metrics in CloudWatch. By default, CloudWatch only provides a few basic metrics such as CPU and Networks.
Quick and easy network infrastructure monitoring. Would you like to access all your monitoring data on a single platform? Dynatrace has you covered—Dynatrace extensions collect the necessary data and offer improved visibility wherever you need a single platform for IM and APM purposes. Start monitoring in minutes.
In today’s complex IT environments, the sheer volume of data created makes it impossible for humans to monitor, comprehend, or troubleshoot problems before they impact the experience of your end users. Still, you might have use cases that rely on important custom data streams. Now you can: Alert on the outage of a custom data source.
With all the data collected and powered by our Davis AI-driven causation engine, Dynatrace automatically identifies slowdowns in your applications and services and points you to their root cause. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Network services visibility (DNS, NTP, ActiveDirectory).
Why browser and HTTP monitors might not be sufficient In modern IT environments, which are complex and dynamically changing, you often need deeper insights into the Transport or Network layers. Is it a bug in the codebase, a malfunctioning backend service, an overloaded hosting infrastructure, or perhaps a misconfigured network?
Complexity and data volume for IT infrastructure soars to new heights. The volume of data and events grows in tandem with the rising complexity of IT infrastructure. Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools. How SNMP traps help detect problems.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. This has resulted in visibility gaps, siloed data, and negative effects on cross-team collaboration. At the same time, the number of individual observability and security tools has grown.
Large enterprise environments are often distributed across multiple data centers around the world. Unnecessary traffic between such data centers can result in wasted resources, unpredictable downtimes, and lost business. preventing unrelated traffic between data centers and regions. optimizing traffic routing.
Mobile applications (apps) are an increasingly important channel for reaching customers, but the distributed nature of mobile app platforms and delivery networks can cause performance problems that leave users frustrated, or worse, turning to competitors. Here are some ways observability data is important to mobile app performance monitoring.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Welcome back to our power dashboarding blog series , data enthusiasts! You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). exploring your data when you know your desired outcome but are unfamiliar with the available data.
This challenge has given rise to the discipline of observability engineering, which concentrates on the details of telemetry data to fine-tune observability use cases. To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus.
In today’s data-driven world, businesses across various industry verticals increasingly leverage the Internet of Things (IoT) to drive efficiency and innovation. Both methods allow you to ingest and process raw data and metrics. The ADS-B protocol differs significantly from web technologies.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
Dynatrace and the Dynatrace Intelligent Observability Platform have added support for the newly introduced Amazon VPC Flow Logs to Amazon Kinesis Data Firehose. This support enables customers to define specific endpoint delivery of real-time streaming data to platforms such as Dynatrace. What is VPC Flow Logs? Why Dynatrace?
In a digital-first world, site reliability engineers and IT data analysts face numerous challenges with data quality and reliability in their quest for cloud control. Increasingly, organizations seek to address these problems using AI techniques as part of their exploratory data analytics practices.
Any service provider tries to reach several metrics in their activity. One group of these metrics is service quality. Quality metrics contain: The ratio of successfully processed requests. But what is the metric that shows service hardware monopolization by a group of users? Number of requests dependent curves.
I love data. I have spent virtually my entire career looking at data. Synthetic data, networkdata, system data, and the list goes on. As much as I love data, data is cold, it lacks emotion. As much as I love data, data is cold, it lacks emotion. Often, 4s is too slow.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. As cloud complexity grows, it brings more volume, velocity, and variety of log data. They also need a high-performance, real-time analytics platform to make that data actionable.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. OpenTelemetry, the open source observability tool, has emerged as an industry-standard solution for instrumenting application telemetry data to make it observable.
This is the ability to see into and measure the current state of a system based on the data it generates, which typically includes logs, metrics, traces, end-user experiences, and context across cloud, multi-cloud, and hybrid environments. This blog originally appeared in Federal News Network. First, let’s discuss observability.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. The network latency between cluster nodes should be around 10 ms or less. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
Redis , short for Remote Dictionary Server, is a BSD-licensed, open-source in-memory key-value data structure store written in C language by Salvatore Sanfillipo and was first released on May 10, 2009. Instead, Redis stores data in data structures which makes it very flexible to use. Data Structures in Redis.
The massive volumes of log data associated with a breach have made cybersecurity forensics a complicated, costly problem to solve. As organizations adopt more cloud-native technologies, observability data—telemetry from applications and infrastructure, including logs, metrics, and traces—and security data are converging.
Youll also learn strategies for maintaining data safety and managing node failures so your RabbitMQ setup is always up to the task. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. We expect complete and accurate data at the end of each run.
Amazon's worldwide financial operations team has the incredible task of tracking all of that data (think petabytes). At Amazon's scale, a miscalculated metric, like cost per unit, or delayed data can have a huge impact (think millions of dollars). The team is constantly looking for ways to get more accurate data, faster.
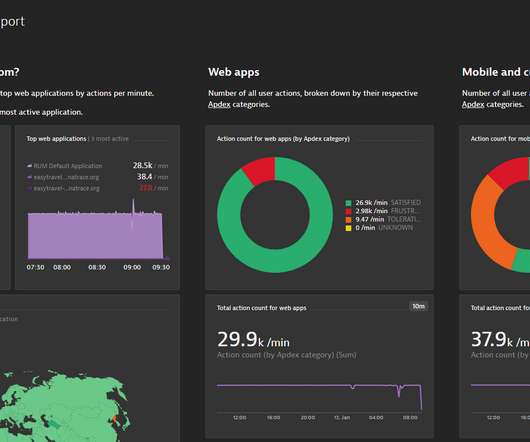
Custom charts allow you to visualize metric performance over time, and USQL tiles allow you to dig deep into user session monitoring data. To access a dashboard report link or to unsubscribe from a scheduled report, you need to have network access to the respective Dynatrace environment.
Understanding that the first mile of getting data in can often be the hardest, Dynatrace continues to invest in log ingest, offering a range of out-of-the-box solutions within the Dynatrace Platform and apps. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Such on-premises environments are usually large, typically consisting of thousands of hosts that are organized in physical data centers. As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. Events and alerts.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. To reduce your CloudWatch costs and throttling, you can now select from additional services and metrics to monitor. Get up to 300 new AWS metrics out of the box. Dynatrace news.
As cloud and big data complexity scales beyond the ability of traditional monitoring tools to handle, next-generation cloud monitoring and observability are becoming necessities for IT teams. These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards.
and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley. What was your path to working in data? There’s us to the right!
Whenever you need to observe another data point, you can easily cover it with a new configuration. The IP address of network devices has changed? Calling it a console of transportation hubs seems reasonable, as the extension itself is only one way to get the data. Extensions bring you a load of metrics.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content