This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
With Dynatrace actively managing business-critical applications, some of our globally distributed enterprise customers require Dynatrace Managed to continue operating even when an entire data center goes down. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes. What is RabbitMQ?
This means you no longer have to procure new hardware, which can be a time-consuming and expensive process. Security: Data is stored securely in the Dynatrace cloud (powered by Azure). All data at rest is stored in Azure Storage and is encrypted and decrypted using 256-bit AES encryption (FIPS 140-2 compliant).
Hyper-V plays a vital role in ensuring the reliable operations of data centers that are based on Microsoft platforms. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Data Store.
Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc. Redundancy by building additional data centers. this is addressed through monitoring and redundancy. Again the approach here is the same. Again the approach here is the same.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Edge computing has transformed how businesses and industries process and manage data. By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Data interception during transit. Redundancy and inefficiency in data aggregation.
Dynatrace just makes this easy—it comes out-of-the-box, no silos of data, no DIY stitching together tools, no wasted time, and no wasted resources. . A Dynatrace Managed cluster may lack the necessary hardware to process all the additional incoming data. All this automatically and with the same hardware. Your feedback.
Managing storage and performance efficiently in your MySQL database is crucial, and general tablespaces offer flexibility in achieving this. In contrast to the single system tablespace that holds system tables by default, general tablespaces are user-defined storage containers for multiple InnoDB tables.
They need specialized hardware, access to petabytes of images, and digital content creation applications with controlled licenses. Historically artists had these machines built for them at their desks and only had access to the data and applications when they were in the office. Artists need many components to be customized.
Security analytics combines data collection, aggregation, and analysis to search for and identify potential threats. Using a combination of historical data and information collected in real time, security teams can detect threats earlier in the SDLC. Here’s how. What is security analytics? Why is security analytics important?
Dynatrace can help customers monitor, troubleshoot, and optimize application performance for workloads operating on AWS Outposts, in AWS Regions, and on customer-owned hardware for a truly consistent hybrid experience.”. Joshua Burgin, General Manager, AWS Outposts, Amazon Web Services, Inc. What is AWS Outposts?
Cloud-based solutions typically aren’t a viable option or enterprises that have strict security or privacy policies that require their data to be maintained on-premise. This gives you full control over your monitoring data and the ability to scale horizontally whenever you need to. Dynatrace news. Prerequisites.
These rapid changes — as well as the increasing volume and variety of data created — require a new approach to observability. As the entire application shares the same computing environment, it collects all logs in the same location, and developers can gain insight from a single storage area.
“ Dynatrace just makes observability easy—it works out-of-the-box, no silos of data, no DIY stitching together tools, no wasted time, and no wasted resources.” There’s no other competing software that can provide this level of value with minimum effort and optimal hardware utilization that can scale up to web-scale!
Complex cloud computing environments are increasingly replacing traditional data centers. In fact, Gartner estimates that 80% of enterprises will shut down their on-premises data centers by 2025. Collect raw data in virtual and nonvirtual environments from multiple feeds, normalize and structure the data, and aggregate it for alerts.
It progressed from “raw compute and storage” to “reimplementing key services in push-button fashion” to “becoming the backbone of AI work”—all under the umbrella of “renting time and storage on someone else’s computers.” Cloud computing? And Hadoop rolled in. Until it wasn’t.
There is a countless number of enterprises, particularly Internet giants, that have explored ways to make graph data processing scalable. It has been a norm to perceive that distributed databases use the method of adding cheap PC(s) to achieve scalability (storage and computing) and attempt to store data once and for all on demand.
Virtualization is a technology that can create servers, storage devices, and networks all in virtual space. Devices connect to a virtual network to share data and resources. This allows users to interact with any hardware resource through a digital interface. How Is Virtualization Technology Used?
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Big data : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper describes the design decisions behind the Snowflake cloud-based data warehouse. An increasingly large fraction of data in modern workloads comes from less predictable and highly variable sources. joins) during query processing.
Enhanced data security, better data integrity, and efficient access to information. This article cuts through the complexity to showcase the tangible benefits of DBMS, equipping you with the knowledge to make informed decisions about your data management strategies. What are the key advantages of DBMS?
Expanding the Cloud - The AWS Storage Gateway. Today Amazon Web Services has launched the AWS Storage Gateway, making the power of secure and reliable cloud storage accessible from customersâ?? With the launch of the AWS Storage Gateway our customers can now integrate their on-premises IT environment with AWSâ??s
Easier rollout thanks to log storage best practices. We’re now allowing for even easier OneAgent rollout by freeing up the /opt mount point from any runtime data that’s produced by OneAgents. Easier rollout thanks to log storage best practices. Advanced customization of OneAgent deployments made easy.
Cloud computing is a model of computing that delivers computing services over the internet, including storage, data processing, and networking. It allows users to access and use shared computing resources, such as servers, storage, and applications, on demand and without the need to manage the underlying infrastructure.
By migrating to SaaS, customers can reduce hardware expenses, enabling them to concentrate on accelerating innovation with Dynatrace. Reassure customers about their data. Verify with the customer that the dashboards are fully operational, and data is coming through as expected. Start small if you need to.
Youll also learn strategies for maintaining data safety and managing node failures so your RabbitMQ setup is always up to the task. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
Narrowing the gap between serverless and its state with storage functions , Zhang et al., Shredder is " a low-latency multi-tenant cloud store that allows small units of computation to be performed directly within storage nodes. " A tenant should not be able to see the code or data of other tenants (isolation).
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the Big Data community quite a long time ago. This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs.
A decade ago, while working for a large hosting provider, I led a team that was thrown into turmoil over the purchasing of server and storagehardware in preparation for a multi-million dollar super-bowl ad campaign. Our procurement decisions were based on trace data that was pulled from a handful of fragmented monitoring solutions.
Before we talk about migrations, we must talk about how we gather the data to make better migration decisions – this is where our OneAgent differentiates itself from other approaches! There is no code or configuration change necessary to capture data and detect existing services. This is LIVE data queryable through an API!
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Storage The type of storage and disk used for database servers can have a significant impact on performance and reliability. Setting oom_score_adj to -800.
Logs can include data about user inputs, system processes, and hardware states. Log files contain much of the data that makes a system observable: for example, records of all events that occur throughout the operating system, network devices, pieces of software, or even communication between users and application systems.
Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them. Additionally, a message queue can smooth out spiky workloads by enabling the producers and consumers to work at a consistent pace without losing data. A producer creates the message, and a consumer processes it.
Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them. Additionally, a message queue can smooth out spiky workloads by enabling the producers and consumers to work at a consistent pace without losing data. A producer creates the message, and a consumer processes it.
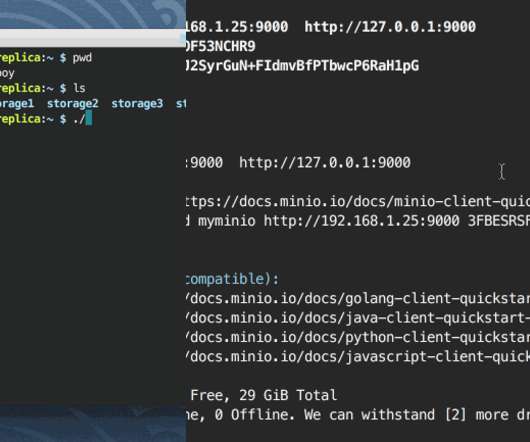
So I was researching object storage and I came across the open source distributed object storage software, Minio. After all they are both object storage solutions. The difference here is that Minio can be deployed on your own hardware.
Traditionally records in a database were stored as such: the data in a row was stored together for easy and fast retrieval. Combined with the rise of data warehouse workloads, where there is often significant redundancy in the values stored in columns, and database models based on column oriented storage took off.
It’s to ensure that our data is durable after each write operation and to make it persistent and consistent without compromising the performance. In terms of MongoDB, it achieves WAL and data durability using a combination of both Journaling and Checkpoints. Starting with the basics, why is WAL needed in the first place?
Oracle requires more complex ongoing administration, as all database configurations must evolve in conjunction with the data schemas and custom code. Data encryption can be achieved with advanced security plugins like pgcrypto which are available for free. CitusDB – distributes data and queries horizontally across nodes.
Encrypting data at rest in a database management system (DBMS) refers to securing data by encrypting it when it is not being used or accessed. This is often done to protect sensitive data from unauthorized access or theft. Disk-level encryption is a security measure that encrypts all data stored on a disk or storage device.
File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. What is a distributed storage backend? SOSP’19. This is not surprising in hindsight.
Regarding MySQL backups , knowing how to secure your data is crucial. Dive in to uncover the essentials of different backup types, command-line tools, and strategic practices for robust data protection. MySQL is a popular open-source relational database management system for online applications and data warehousing.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content