This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With Dynatrace actively managing business-critical applications, some of our globally distributed enterprise customers require Dynatrace Managed to continue operating even when an entire data center goes down. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios.
IT operations analytics is the process of unifying, storing, and contextually analyzing operationaldata to understand the health of applications, infrastructure, and environments and streamline everyday operations. Here are the six steps of a typical ITOA process : Define the data infrastructure strategy.
Do you keep an eye on the support of distributions and versions of operatingsystems within your environment? With this information, you can find answers to questions such as: Which operatingsystems and versions does Dynatrace support? Which operatingsystems and versions does Dynatrace support?
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Kubernetes is emerging as the “operatingsystem” of the cloud. Kubernetes moved to the cloud in 2022.
Hyper-V plays a vital role in ensuring the reliable operations of data centers that are based on Microsoft platforms. Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. Optimize resource allocation, identify bottlenecks, and improve overall system performance.
CPU consumption in Unix/Linux operatingsystems is studied using eight different metrics: User CPU time, System CPU time, nice CPU time, Idle CPU time, Waiting CPU time, Hardware Interrupt CPU time, Software Interrupt CPU time, Stolen CPU time. User CPU Time and System CPU Time.
These rapid changes — as well as the increasing volume and variety of data created — require a new approach to observability. When an application runs on a single large computing element, a single operatingsystem can monitor every aspect of the system. Just as the code is monolithic, so is the logging.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. There is no need to plan for extra resources, update operatingsystems, or install frameworks. The provider is essentially your system administrator.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x).
AWS Lambda enables organizations to access many types of functions from AWS’ cloud-based services, such as: Data processing, to execute code based on triggers, system states, or user actions. Real-time stream processing to perform live activity tracking, data cleansing, metrics generation, and more. Data entering a stream.
They need specialized hardware, access to petabytes of images, and digital content creation applications with controlled licenses. Historically artists had these machines built for them at their desks and only had access to the data and applications when they were in the office. That is where SaltStack comes in.
Compare ease of use across compatibility, extensions, tuning, operatingsystems, languages and support providers. PostgreSQL is an open source object-relational database system with over 30 years of active development. Data encryption can be achieved with advanced security plugins like pgcrypto which are available for free.
A log is a detailed, timestamped record of an event generated by an operatingsystem, computing environment, application, server, or network device. Logs can include data about user inputs, system processes, and hardware states. But to determine root causes, logs must be analyzed. What is log analytics?
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operatingsystem and infrastructure. An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces. Observability.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operatingsystem, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
Cloud service providers, such as Amazon Web Services (AWS) , can offer infrastructure with five-nines availability by deploying in multiple availability zones and replicating data between regions. Complicating the situation further, increasingly connected services are pushing more data processing to the edge. Automate IT operations.
If the container running on the core next to your container suddenly decides to fetch a lot of data from the RAM, it will inevitably result in more cache misses for you (and hence a potential performance degradation). Linux to the rescue?
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operatingsystems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. What is a message queue?
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operatingsystems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. What is a message queue?
While the benefits of multicloud environments are crucial to agency success, they introduce complexity and overwhelming data volumes that are impossible for humans to manage alone. In contrast, observability enables teams to understand a system’s internal state by analyzing the data it generates, including logs, metrics, and traces.
As a result, teams must verify their data first because the triggering condition could be based on discovered data that is stale. With the proliferation of infrastructure-as-code tools, operations teams can: Deploy, configure, or tear down workloads into an instance in real-time.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operatingsystem, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Operatingsystem Linux is the most common operatingsystem for high-performance MySQL servers.
In general, cloud application security involves authentication and access control, data encryption, identity and user management, and vulnerability management. Combining cloud application security and observability data into a unified analytics platform is beneficial for organizations to improve their overall application security posture.
You need to ensure that you are backing up all the data. Or did you shut down a project that no longer needs to be part of the backup procedure, at least after rigorous data archiving? Check the versions of database connectors, programming languages, and proceed all the way down to the operatingsystem.
Failures are a given and everything will eventually fail over time: from routers to hard disks, from operatingsystems to memory units corrupting TCP packets, from transient errors to permanent failures. This is a given, whether you are using the highest quality hardware or lowest cost components. Primitives not frameworks.
Considerations for setting the architectural foundations for a fast data platform. Google was among the pioneers that created “web scale” architectures to analyze the massive data sets that resulted from “crawling” the web that gave birth to Apache Hadoop, MapReduce, and NoSQL databases. Back in the days of Web 1.0,
When it comes to hardware support to mitigate software security issues, there is a significant gap between what is available in products today and known solutions. Attestation—Providing systems the means to attest or verify the integrity of their components. The data in the above definition could also include instructions.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
In todays data-driven world, the ability to effectively monitor and manage data is of paramount importance. Redis, a powerful in-memory data store, is no exception. This ensures each Redis instance optimally uses the in-memory data store and aligns with the operatingsystem’s efficiency.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. A reduced throughput could generally indicate that the server gets fewer queries.
During compatibility testing of an application, we check the compatibility of the application with multiple devices, hardware, software versions, network, operatingsystems, and browsers, etc. OperatingSystem. The iOS app should work well on the networks of different bandwidths, speeds, data transfer rates, etc.
In today’s data-driven world, the ability to effectively monitor and manage data is of paramount importance. Redis®, a powerful in-memory data store, is no exception. This ensures each Redis® instance optimally uses the in-memory data store and aligns with the operatingsystem’s efficiency.
The layers of platforms start at the bottom with hardware choices such as which CPU architectures and vendors you want to use. The next layer is operatingsystem platforms, what flavor of Linux, what version of Windows etc. However there were teams doing very different things on AWS, and they each built their own platform layer.
P1967R14 #embed – a scannable, tooling-friendly binary resource inclusion mechanism by JeanHeyd Meneide enables #include for binary data a portable way to pull binary data into a program without external tools and build system support. Each of these approaches come with benefits and drawbacks.
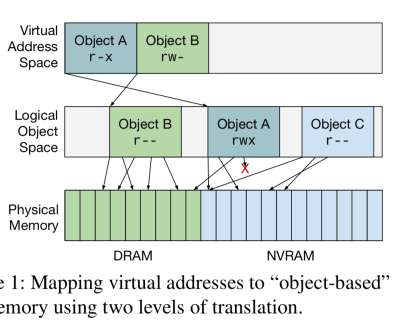
…software operating on persistent data structures requires "global" pointers that remain valid after a process terminates, while hardware requires that a diverse set of devices all have the same mappings they need for bulk transfers to and from memory, and that they be able to do so for a potentially heterogeneous memory system.
In this post, I argue that software and data interoperability, a hallmark of the modern computer ecosystem, is at the core of several widespread security problems. An alternate approach is to tie data and potentially software to specific physical instances of a digital system. Individualizing digital systems.
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. USENIX ATC is a top-tier venue with a broad range of systems research papers from both industry and academia. Final words.
A three-tier system is a software application architecture that consists of a presentation layer, application layer, and data, or core, layer. The benefit of this system is that each tier runs independently from the other tiers, so they can be updated or scaled without impacting the other tiers. Three-Tier. Multi-Tier.
From operatingsystems to versions to hardware specs, mobile devices stand unique even after being billions in number. But testing this is essential too because data communication over the network cannot be eliminated by putting all the files into the device storage.
In this blog post, we will discuss the best practices on the MongoDB ecosystem applied at the OperatingSystem (OS) and MongoDB levels. We’ll also go over some best practices for MongoDB security as well as MongoDB data modeling. Without further ado, let’s start with the OS settings. For example: $ /opt/mongodb/4.0.6/bin/mongos
Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability. Let’s now look at the operatingsystem level. Why should you care? Not all writes are equal either.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operatingsystems are designed, and the way applications operate on data. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc.
Existing cache and main memory compression techniques compress data in small fixed-size blocks, typically cache lines. … to realize these insights, hardware needs to access data at object granularity and must have control over pointers between objects. ” The big idea. Implications. This is where Hotpads comes in.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content