This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re excited to share that Dynatrace has been recognized in the DevOps: Observability category of InfoWorlds 2024 Technology of the Year awards! In todays digital landscape, organizations face intricate challenges that demand more than basic monitoring. Register now !
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. Let’s explore some of the advantages of monitoring GitHub runners using Dynatrace. Extending this visibility into your CI/CD pipelines offers even greater value.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments.
To provide maximum freedom in selecting the service-level indicators that matter most to your business, Dynatrace combines SLOs with the power of Dynatrace Grail™ data lakehouse, the central data platform with heterogeneous and contextually linked data. This is where Grail, the Dynatrace central data platform, excels.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOpsmonitoring tools has grown exponentially. But when and how does DevOpsmonitoring fit into the process? And how do DevOpsmonitoring tools help teams achieve DevOps efficiency?
In the ever-evolving world of DevOps , the ability to gain deep insights into system behavior, diagnose issues, and improve overall performance is one of the top priorities. Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems.
With Metis, were making database troubleshooting as seamless as any other part of the DevOps workflow. For SREs, this means better proactive monitoring, fewer database-related incidents, and greater stability in production environments.
ln a world driven by macroeconomic uncertainty, businesses increasingly turn to data-driven decision-making to stay agile. That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. Cost and capacity constraints for managing this data are becoming a significant burden to overcome.
Manual approaches lack continuous monitoring, making them ill-equipped to prevent issues before they arise. Processes are time-intensive. Custom scripts and manual workflows demand substantial time and effort, creating inefficiencies. Reactivity. The skills gap creates inefficiencies.
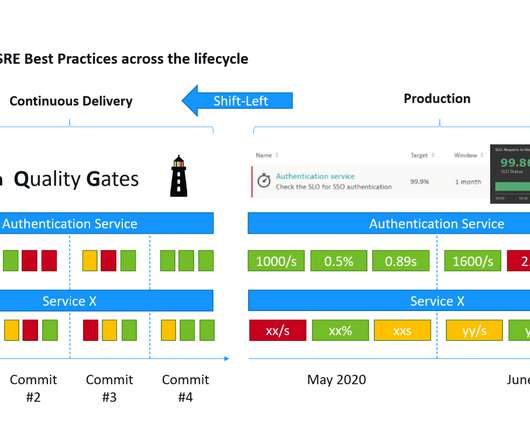
This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates. Dynatrace news.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. Dynatrace news.
What should they do first to set your organization on the path to DevOps automation? By the time your SRE sets up these DevOps automation best practices, you have had to push unreliable releases into production. Most importantly, the right modern observability platform is key to a successful DevOps and SRE implementation.
Zabbix is a universal monitoring tool that combines data collection , data visualization , and problem notification. My first encounter with this monitoring system was in 2014 when I joined a project where Zabbix was already in use for monitoring network devices (routers, switches).
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOps metrics to help you meet your DevOps goals. Dynatrace news.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging.
To keep up with current demands, DevOps and platform engineering teams need a solution that can fully embrace and understand complexity, delivering precise answers that enable the creation of trustworthy automation. The effectiveness of this automation relies on the quality of the underlying data.
DevOps seeks to accomplish smooth and efficient software creation, delivery, monitoring, and improvement by prioritizing agility and adaptability over rigid, stage-by-stage development. What is DevOps? As DevOps pioneer Patrick Debois first described it in 2009, DevOps is not a specific technology, but a tactical approach.
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems. What is orchestration?
DevOps metrics and digital experience data are critical to this. Breaking down the silos between IT and operations to form a DevOps team, and then extending this to other departments to achieve BizDevOps, has been central to reaching this goal. Dynatrace news. Beginnings of BizDevOps. Security integration.
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
This need is amplified by an increasingly complex regulatory and compliance landscape, where global standards demand stringent measures to protect data, ensure service continuity, and mitigate risks. It gives you visibility into which components are monitored and which are not and helps automate time-consuming compliance configuration checks.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. Continuous delivery seeks to make releases regular and predictable events for DevOps staff, and seamless for end-users.
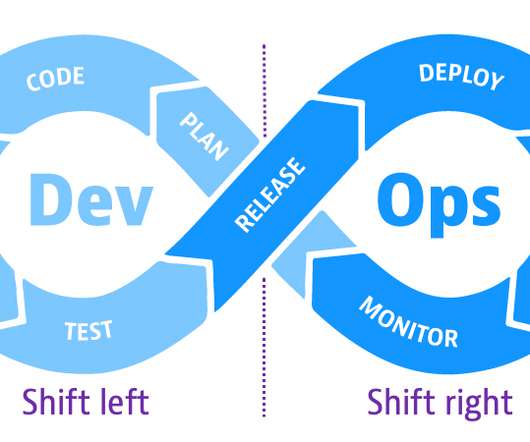
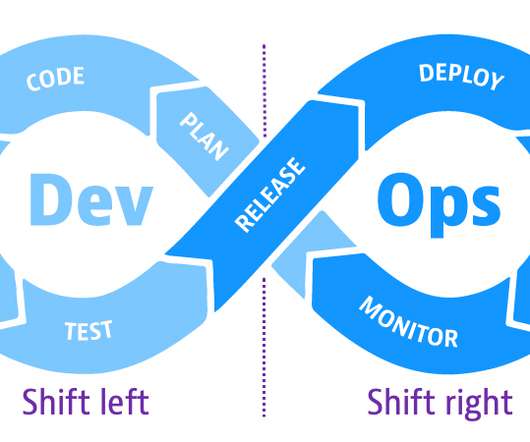
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Logs can include data about user inputs, system processes, and hardware states. What is log monitoring? Dynatrace news. billion in 2020 to $4.1
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. What these steps have in common is that monitoring tools are not in sync with new changes in code or topology and this observability data is often siloed within different tools and teams. Automation presents a solution.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert.
To keep up, we’ve seen growing interest in DevOps and continuous delivery , as organizations aim to deliver new digital services and experiences faster. However, it isn’t as simple as just implementing a DevOps toolset, analyzing DevOps metrics, or investing in DevOpsmonitoring capabilities. What is DevOps?
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. As cloud complexity grows, it brings more volume, velocity, and variety of log data. When trying to address this challenge, your cloud architects will likely choose Amazon Data Firehose.
I have ingested important custom data into Dynatrace, critical to running my applications and making accurate business decisions… but can I trust the accuracy and reliability?” ” Welcome to the world of data observability. At its core, data observability is about ensuring the availability, reliability, and quality of data.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
As a result, API monitoring has become a must for DevOps teams. So what is API monitoring? What is API Monitoring? API monitoring is the process of collecting and analyzing data about the performance of an API in order to identify problems that impact users. The need for API monitoring.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). Dynatrace’s Real User Monitoring (RUM) offering provides observability to every end-user that uses your mobile or web applications.
AIOps offers an alternative to traditional infrastructure monitoring and management with end-to-end visibility and observability into IT stacks. But increasing complexity and lacking visibility creates a problem: Enterprises invest more resources into monitoring and don’t get the data and answers they need.
As the world becomes increasingly interconnected with the proliferation of IoT devices and a surge in applications, digital transactions, and data creation, mobile monitoring — monitoring mobile applications — grows ever more critical.
Log data provides a unique source of truth for debugging applications, optimizing infrastructure, and investigating security incidents. This contextualization of log data enables AI-powered problem detection and root cause analysis at scale. Dynamic landscape and data handling requirements result in manual work.
AI data analysis can help development teams release software faster and at higher quality. So how can organizations ensure data quality, reliability, and freshness for AI-driven answers and insights? And how can they take advantage of AI without incurring skyrocketing costs to store, manage, and query data?
With this integration, Dynatrace customers can now leverage Terraform to manage their monitoring infrastructure as code,” said Asad Ali, Senior Director of Sales Engineering at Dynatrace. What is monitoring as code? What are the benefits of monitoring as code? across their complete Dynatrace instance.”. Step 1: Write.
Over the last year, Dynatrace extended its AI-powered log monitoring capabilities by providing support for all log data sources. We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks.
Monitoring application and website performance has become critical to delivering a smooth digital experience to users. To proactively identify and fix performance problems, modern DevOps teams rely heavily on monitoring solutions. This directly impacts key business metrics like customer conversions, engagement, and revenue.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content