This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To provide maximum freedom in selecting the service-level indicators that matter most to your business, Dynatrace combines SLOs with the power of Dynatrace Grail™ data lakehouse, the central data platform with heterogeneous and contextually linked data. This is where Grail, the Dynatrace central data platform, excels.
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOpsmetrics to help you meet your DevOps goals.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. This has resulted in visibility gaps, siloed data, and negative effects on cross-team collaboration. At the same time, the number of individual observability and security tools has grown.
DevOpsmetrics and digital experience data are critical to this. Breaking down the silos between IT and operations to form a DevOps team, and then extending this to other departments to achieve BizDevOps, has been central to reaching this goal. Dynatrace news. Beginnings of BizDevOps. Security integration.
ln a world driven by macroeconomic uncertainty, businesses increasingly turn to data-driven decision-making to stay agile. That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. Cost and capacity constraints for managing this data are becoming a significant burden to overcome.
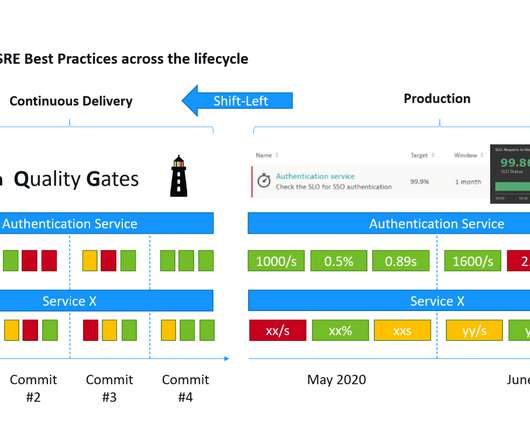
This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates. Dynatrace news.
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. Automating GitHub runner data ingestion with Dynatrace workflows Workflows within the Dynatrace SaaS platform are a robust tool for automating complex processes.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging.
In the ever-evolving world of DevOps , the ability to gain deep insights into system behavior, diagnose issues, and improve overall performance is one of the top priorities. Monitoring: Understanding System State Monitoring focuses on collecting and analyzing data about the state of a system or application.
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
Over the last year, Dynatrace extended its AI-powered log monitoring capabilities by providing support for all log data sources. We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
With the most important components becoming release candidates , Dynatrace now supports the full OpenTelemetry specification on all runtimes and automatically adds intelligence to metrics at enterprise scale. So these metrics are immensely valuable to SRE and DevOps teams. First, it’s about getting the data. Not to worry.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. What these steps have in common is that monitoring tools are not in sync with new changes in code or topology and this observability data is often siloed within different tools and teams. The role of observability within DevOps.
Should business data be part of your observability solution? Technology and business leaders express increasing interest in integrating business data into their IT observability strategies, citing the value of effective collaboration between business and IT.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). In the workshop, I also answered the question: How can we measure those metrics (=SLIs) that are behind our objectives?
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
To keep up, we’ve seen growing interest in DevOps and continuous delivery , as organizations aim to deliver new digital services and experiences faster. However, it isn’t as simple as just implementing a DevOps toolset, analyzing DevOpsmetrics, or investing in DevOps monitoring capabilities. What is DevOps?
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. As cloud complexity grows, it brings more volume, velocity, and variety of log data. They also need a high-performance, real-time analytics platform to make that data actionable.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges. How critical is the vulnerability?
I have ingested important custom data into Dynatrace, critical to running my applications and making accurate business decisions… but can I trust the accuracy and reliability?” ” Welcome to the world of data observability. At its core, data observability is about ensuring the availability, reliability, and quality of data.
AWS is on a journey to revolutionize DevOps using the latest technologies. We are starting to treat DevOps, and the toolchains around it, as a data science problem – And when we think of it this way, code, logs, and application metrics are all data that we can optimize with machine learning (ML).
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. But there is a lack of time for DevOps , SRE , and developers to analyze all this data to identify whether there’s a user impacting problem and if so – what the root cause is to fix it fast. Dynatrace news.
As the new standard of monitoring, observability enables I&O, DevOps, and SRE teams alike to gain critical insights into the performance of today’s complex cloud-native environments. Then teams can leverage and interpret the observable data. Observability defined. Achieving meaningful observability.
Predictive AI uses machine learning, data analysis, statistical models, and AI methods to predict anomalies, identify patterns, and create forecasts. Predictive AI empowers site reliability engineers (SREs) and DevOps engineers to detect anomalies and irregular patterns in their systems long before they escalate into critical incidents.
Let’s take a closer look and clear up any confusion about what it is, the telemetry data it covers, and the benefits it can provide. Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces.
DevOpsmetrics and digital experience data are critical to this. Breaking down the silos between IT and operations to form a DevOps team, and then extending this to other departments to achieve BizDevOps, has been central to reaching this goal. Dynatrace news. Beginnings of BizDevOps. Security integration.
Full-stack observability is the ability to determine the state of every endpoint in a distributed IT environment based on its telemetry data. A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Watch webinar now!
In a digital-first world, site reliability engineers and IT data analysts face numerous challenges with data quality and reliability in their quest for cloud control. Increasingly, organizations seek to address these problems using AI techniques as part of their exploratory data analytics practices.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time.
But this is often not as intuitively simple as it should be in other solutions where DevOps teams must click through a series of screens and dashboards to get to the root cause. The post Identify issues immediately with actionable metrics and context in Dynatrace Problem view appeared first on Dynatrace blog.
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
AIOps (Artificial Intelligence for IT Operations) is a cutting-edge solution that combines AI, ML, and automation to enhance DevOps practices and streamline IT operations. AIOps offers a solution by leveraging AI and ML algorithms to analyze this data in real time, identify patterns, and provide actionable insights.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a software engineer takes nine hours to remediate a problem within a production application. Challenges organizations face in using observability and security data to drive automation. In-context topology identification.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Ensure that you get the most out of your product.
Dynatrace enables various teams, such as developers, threat hunters, business analysts, and DevOps, to effortlessly consume advanced log insights within a single platform. Existing siloed tools lead to inefficient workflows, fragmented data, and increased troubleshooting times.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events.
They observe the telemetry data (logs, metrics, traces) emitted from the application/microservice using various observability tools and make informed decisions regarding scaling, maintaining, or troubleshooting applications in the production environment. And most importantly, what is in it for developers, DevOps, and SRE folks?
Although many companies adopt solutions such as OpenTelemetry, Prometheus, and Grafana as part of their observability strategy, they often confront a common data analysis problem: data silos. When teams, tools, and data are siloed, it’s harder for organizations to succeed. This leads to multiple tool-specific dashboards.
Read our case study to learn more about it, or listen in to my podcasts with CTO Bernd Greifeneder and DevOps Lead Anita Engleder. Instead of starting with the tooling we should first focus on how we changed our process, which KPIs we introduced and how we steer our security efforts using a data driven approach!”
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content