This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments.
To provide maximum freedom in selecting the service-level indicators that matter most to your business, Dynatrace combines SLOs with the power of Dynatrace Grail™ data lakehouse, the central data platform with heterogeneous and contextually linked data. This is where Grail, the Dynatrace central data platform, excels.
ln a world driven by macroeconomic uncertainty, businesses increasingly turn to data-driven decision-making to stay agile. That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. Cost and capacity constraints for managing this data are becoming a significant burden to overcome.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
As enterprises embrace more distributed, multicloud and applications-led environments, DevOps teams face growing operational, technological, and regulatory complexity, along with rising cyberthreats and increasingly demanding stakeholders. How do you make your changes stick — and prevent future tool sprawl?
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
In an age when people freely share even their most sensitive personal data on many online apps and services, we have grown to expect businesses will protect this information during any engagement or transaction. DevSecOps is the practice of integrating security into the DevOps workflow. Dynatrace news.
DevOps seeks to accomplish smooth and efficient software creation, delivery, monitoring, and improvement by prioritizing agility and adaptability over rigid, stage-by-stage development. What is DevOps? DevOps looks to eliminate these silos by creating a combined process that focuses on visibility-powered collaboration.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging.
In response to the scale and complexity of modern cloud-native technology, organizations are increasingly reliant on automation to properly manage their infrastructure and workflows. DevOps automation eliminates extraneous manual processes, enabling DevOps teams to develop, test, deliver, deploy, and execute other key processes at scale.
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. Inefficient or resource-intensive runners can lead to increased costs and underutilized infrastructure. Workflow overview The workflow, though simple, is highly effective.
Infrastructure complexity is costing enterprises money. AIOps offers an alternative to traditional infrastructure monitoring and management with end-to-end visibility and observability into IT stacks. As 69% of CIOs surveyed said, it’s time for a “radically different approach” to infrastructure monitoring.
.” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example. Here, we’ll tackle the basics, benefits, and best practices of IAC, as well as choosing infrastructure-as-code tools for your organization. What is infrastructure as code? Consistency.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
DevOps metrics and digital experience data are critical to this. Breaking down the silos between IT and operations to form a DevOps team, and then extending this to other departments to achieve BizDevOps, has been central to reaching this goal. Dynatrace news. Beginnings of BizDevOps. Security integration.
As organizations mature on their digital transformation journey, they begin to realize that automation – specifically, DevOps automation – is critical for rapid software delivery and reliable applications. But as multicloud environments grow, they become increasingly complex and generate massive amounts of data.
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. What is hybrid cloud architecture?
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems. What is orchestration?
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOps metrics to help you meet your DevOps goals. Dynatrace news.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
While many companies now enlist public cloud services such as Amazon Web Services, Google Public Cloud, or Microsoft Azure to achieve their business goals, a majority also use hybrid cloud infrastructure to accommodate traditional applications that can’t be easily migrated to public clouds. How to modernize for hybrid cloud.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. What these steps have in common is that monitoring tools are not in sync with new changes in code or topology and this observability data is often siloed within different tools and teams. The role of observability within DevOps.
Anyone moving to the cloud knows that it isn’t just a change from running servers in your data center to running them in someone else’s data center. If you’re doing it right, cloud represents a fundamental change in how you build, deliver and operate your applications and infrastructure. Able to provide answers, not just data.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. As cloud complexity grows, it brings more volume, velocity, and variety of log data. When trying to address this challenge, your cloud architects will likely choose Amazon Data Firehose.
Protecting IT infrastructure, applications, and data requires that you understand security weaknesses attackers can exploit. Cloud infrastructure analysis ensures the secure configuration of cloud infrastructure including virtual machines, containers, cloud-hosted databases, and serverless services. Dynatrace news.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges. How critical is the vulnerability?
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice?
As the new standard of monitoring, observability enables I&O, DevOps, and SRE teams alike to gain critical insights into the performance of today’s complex cloud-native environments. Then teams can leverage and interpret the observable data. Observability defined. Achieving meaningful observability.
They handle complex infrastructure, maintain service availability, and respond swiftly to incidents. Predictive AI uses machine learning, data analysis, statistical models, and AI methods to predict anomalies, identify patterns, and create forecasts. This data-driven approach fosters continuous refinement of processes and systems.
I have ingested important custom data into Dynatrace, critical to running my applications and making accurate business decisions… but can I trust the accuracy and reliability?” ” Welcome to the world of data observability. At its core, data observability is about ensuring the availability, reliability, and quality of data.
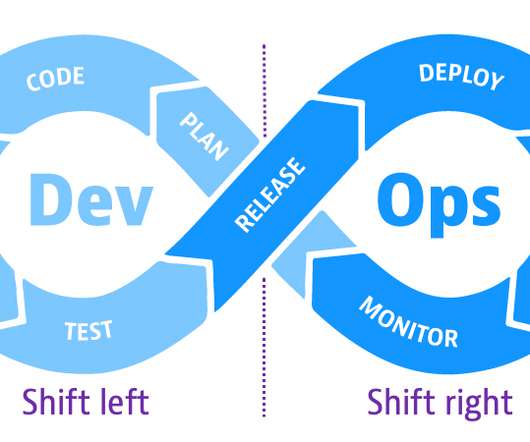
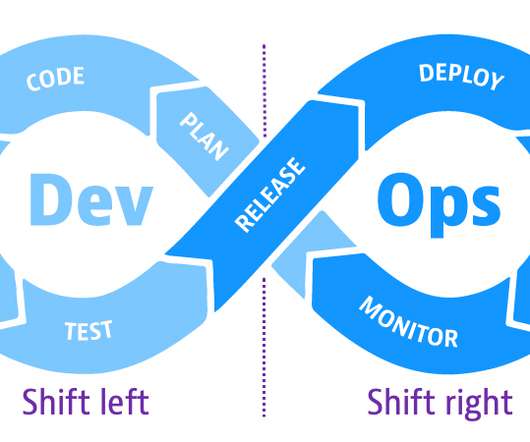
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). Dynatrace provides several ways to ingest data from external data sources. Dynatrace news.
For organizations running their own on-premises infrastructure, these costs can be prohibitive. Cloud service providers, such as Amazon Web Services (AWS) , can offer infrastructure with five-nines availability by deploying in multiple availability zones and replicating data between regions. What is always-on infrastructure?
Full-stack observability is the ability to determine the state of every endpoint in a distributed IT environment based on its telemetry data. Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. Why full-stack observability matters.
Log data provides a unique source of truth for debugging applications, optimizing infrastructure, and investigating security incidents. This contextualization of log data enables AI-powered problem detection and root cause analysis at scale. Dynamic landscape and data handling requirements result in manual work.
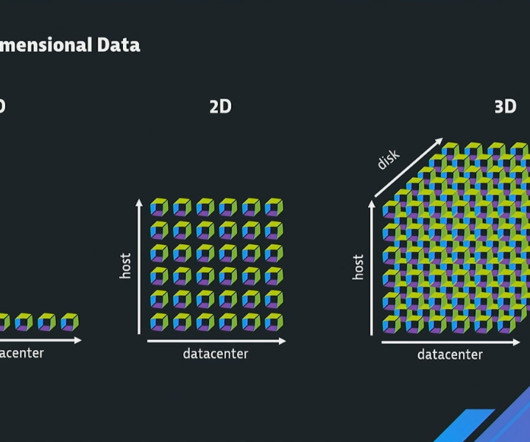
Considering the latest State of Observability 2024 report, it’s evident that multicloud environments not only come with an explosion of data beyond humans’ ability to manage it. It’s increasingly difficult to ingest, manage, store, and sort through this amount of data. You can find the list of use cases here.
But IT teams need to embrace IT automation and new data storage models to benefit from modern clouds. As they enlist cloud models, organizations now confront increasing complexity and a data explosion. Data explosion hinders better data insight. Log management and analytics have become a particular challenge.
AI data analysis can help development teams release software faster and at higher quality. So how can organizations ensure data quality, reliability, and freshness for AI-driven answers and insights? And how can they take advantage of AI without incurring skyrocketing costs to store, manage, and query data?
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. Can’t we just fold it into existing DevOps best practices? Why: Data Makes It Different. The new category is often called MLOps.
In those cases, what should you do if you want to be proactive and ensure that your infrastructure is always up and running? You could of course create a custom device in Dynatrace and send data to it using our API or an ActiveGate extension. Visualize your synthetic monitor data. Easy and flexible infrastructure monitoring.
Over the last year, Dynatrace extended its AI-powered log monitoring capabilities by providing support for all log data sources. We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks. Duration: 163.41
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. The ability to effectively manage multi-cluster infrastructure is critical to consistent and scalable service delivery.
Navigate digital infrastructure complexity In today’s rapidly evolving digital environment, organizations face increasing pressure from customers and competitors to deliver faster, more secure innovations. The effectiveness of this automation relies on the quality of the underlying data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content