This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Modern applications rely on distributed databases to handle massive amounts of data and scale seamlessly across multiple nodes. While sharding helps distribute the load, it also introduces a major challenge cross-shard joins and data movement, which can significantly impact performance.
If you’re a developer who has ever had to troubleshoot a database issue, you know how frustrating it can be. And with cloud-native databases like PostgreSQL and MySQL, the complexity only grows. Metis has built an AI-driven database observability platform designed for developers and SREs.
In today’s world where data drives everything, managing large-scale databases and their security is both a necessity and a challenge. A few factors that organizations consider when choosing databases are primary are its cost, flexibility, and support from hosting providers.
One of the most significant challenges faced by middleware applications is optimizing database interactions. This is crucial because middleware often serves as the bridge between client applications and backend databases, handling a high volume of requests and data processing tasks.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data.
In this blog post, we’ll walk you through a hands-on demo that showcases how the Distributed Tracing app transforms raw OpenTelemetry data into actionable insights Set up the Demo To run this demo yourself, you’ll need the following: A Dynatrace tenant. If you don’t have one, you can use a trial account.
Migrating from Amazon RDS to DynamoDB can be a significant challenge, especially when transitioning from a relational database like RDS (PostgreSQL, MySQL, etc.) One of the most effective strategies for migrating data incrementally is the Dual Write approach. to DynamoDB, a NoSQL, key-value store.
To understand whats happening in todays complex software ecosystems, you need comprehensive telemetry data to make it all observable. With so many types of technologies in software stacks around the globe, OpenTelemetry has emerged as the de facto standard for gathering telemetry data. But, generating telemetry data is the easy part.
If you’re hosting your databases in the cloud, choosing the right cloud service provider is a significant decision to make for your long-term hosting costs. Over the last few weeks, we have been inundated with requests from SMB customers looking to improve the ROI on their database hosting. MongoDB® Database. EC2 instances.
Data is being generated from various sources, including electronic devices, machines, and social media, across all industries. A significant evolution is taking place in the way data is organized for further analysis. However, unless it is processed and stored effectively, it holds little value.
In this article, we’ll dive deep into the concept of database sharding, a critical technique for scaling databases to handle large volumes of data and high levels of traffic. We’ll start by defining what sharding is and why it’s essential for modern, high-performance databases.
Therefore, I found it important to write a piece based on my understanding of time series data versus relational data as someone with a unique understanding of both.
In this article, I want to share my knowledge and opinion about the data types that are often used as an identifier. These are measurements of search speed by key and data types for the key on the database side. I will use a PostgreSQL database and a demo Java service to compare query speeds.
Maintaining optimal application performance is crucial for businesses, and fast databases are vital in achieving this goal. For an effective approach to database performance, it’s crucial to have a comprehensive overview of all databases, including server-side DBs.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. However, as we highlighted previously, business data can be significantly more complex than simple metrics.
Running Databases efficiently is crucial for business success Monitoring databases is essential in large IT environments to prevent potential issues from becoming major problems that result in data loss or downtime. This makes them ideal for managing structured data.
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch data pipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Data pipeline asset management with Dataflow.
Financial data engineering in SAS involves the management, processing, and analysis of financial data using the various tools and techniques provided by the SAS software suite. Here are some key aspects of financial data engineering in SAS: 1.
When we are working with a database, optimization is crucial and key in terms of application performance and efficiency. Selection of Right Partition Key Choosing an appropriate partition key is vital for distributed databases like Cosmos DB.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. Yet, the impact of choosing the right NoSQL database goes beyond these parameters; it affects your business outcomes. How do these metrics translate into real-world value for your business?
As applications grow in complexity and user base, the demands on their underlying databases increase significantly. Efficient database scaling becomes crucial to maintain performance, ensure reliability, and manage large volumes of data. This cheatsheet provides an overview of essential techniques for database scaling.
While applications are built using a variety of technologies and frameworks, there is one thing they usually have in common: the data they work with must be stored in databases. Now, Dynatrace has gone a step further and expanded its coverage and intelligent observability into the next layer: database infrastructure.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. With the latest Data Mesh Platform, data movement in Netflix Studio reaches a new stage.
When creating applications that store and analyze large amounts of data, such as time series, log data, or event-storing ones, developing a good and future-proof data model can be a difficult task. Choosing the right data types in PostgreSQL can significantly impact your database's performance and efficiency.
However, lurking beneath the surface lies a complex web of data storage and retrieval. When database problems arise, they can disrupt even the most well-crafted applications. That's why knowing how to debug mobile app database problems and optimize data storage performance is essential for developers seeking excellence.
Log-Structured Merge Trees (LSM trees) are a powerful data structure widely used in modern databases to efficiently handle write-heavy workloads. They offer significant performance benefits through batching writes and optimizing reads with sorted data structures.
Database sharding is a powerful technique employed to manage large databases more effectively. It involves partitioning a large database into smaller, more manageable parts, known as shards. The above diagram presents a visual representation of a sharded database.
A graphical user interface (GUI) helps simplify how you interact with your MySQL databases. Whether youre a developer, database administrator, or data analyst, a good GUI can make everyday tasks faster, clearer, and less error-prone. Thats where MySQL GUIs come in.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
Data Mesh?—?A A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A After evaluating the options , the team has decided to create Data Mesh as our next generation data pipeline solution.
Horizontally scalable data stores like Elasticsearch , Cassandra , and CockroachDB distribute their data across multiple nodes using techniques like consistent hashing. As nodes are added or removed, the data is reshuffled to ensure that the load is spread evenly across the new set of nodes.
Understanding the structures within a Relational Database Management System (RDBMS) is critical to optimizing performance and managing data effectively. Here's a breakdown of the concepts with examples. RDBMS Structures 1.
It is an open standard format which organizes data into key/value pairs and arrays detailed in RFC 7159. JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. You can also check out our Working with JSON Data in PostgreSQL vs. JSONB Patterns & Antipatterns.
In the era of the Internet of Things ( IoT) , the continuous influx of spatial and temporal data from interconnected devices has given rise to a vast and intricate landscape, demanding a sophisticated approach to database management.
These media focused machine learning algorithms as well as other teams generate a lot of data from the media files, which we described in our previous blog , are stored as annotations in Marken. There are many naive solutions possible for this problem for example: Write different runs in different databases. in a video file.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
They frequently articulate the need for real-time visibility into business data to support agile business decisions. But existing business intelligence (BI) tools often lack the broad context, ease of data access, and real-time insights needed to understand and improve customer experience and complex business processes.
Kafka’s ability to handle large volumes of real-time market data makes it a core infrastructure component for trading, risk management, and fraud detection. Financial institutions use Kafka to stream data from market data feeds, transaction data, and other external sources to drive decisions.
A modernized database will help you focus on building innovative solutions rather than investing your time and effort in managing these legacy systems. Based on the scale of your existing data warehouse processes or jobs, it can be an enormous task to modernize.
Recently, I faced an issue related to a very high load on the database layer. The database was having too many connections in parallel. I had to review my application’s database connection pool (DBCP) properties very closely.
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Database Systems: Modernization for Data-Driven Architectures. Time series data has become an essential part of data collection in various fields due to its ability to capture trends, patterns, and anomalies.
Data processing in the cloud has become increasingly popular due to its scalability, flexibility, and cost-effectiveness. This article will explore how these technologies can be used together to create an optimized data pipeline for data processing in the cloud.
Structured Query Language (SQL) is a simple declarative programming language utilized by various technology and business professionals to extract and transform data. To conclude, GUIs are a vital addition to ease the lives of database users and developers.
As cloud applications have become the norm, the databases that power these applications are now typically run as managed services by cloud providers. Optimize database performance. Small changes in a database can have an enormous impact on overall application performance. One place to rule them all.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































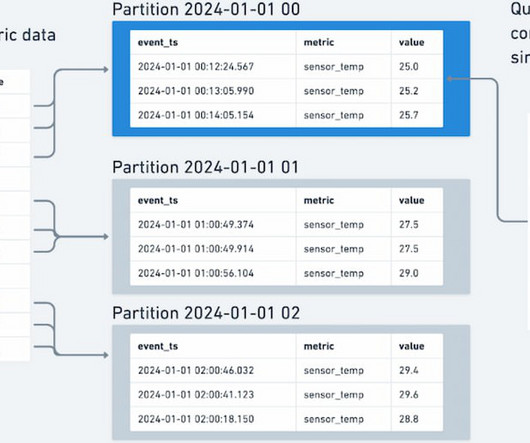









Let's personalize your content