This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community!
In softwareengineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go. Posted with permission.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior SoftwareEngineer at Netflix.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. For example?—?clinical
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Here we describe the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at Netflix, including how our platform investments support running tests at scale while enabling innovation. Curious to learn more about other Data Science and Engineering functions at Netflix?
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
This approach has also allowed us to build strong relationships with central engineering teams at Netflix (Data Platform, Developer Tools, Cloud Infrastructure, IAM Product Engineering) that will continue to serve as central points of leverage for security in the long term.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior SoftwareEngineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Who's Hiring? Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
First, the behavior of an AI application depends on a model , which is built from source code and training data. A model isn’t source code, and it isn’t data; it’s an artifact built from the two. You need a repository for models and for the training data. Models almost certainly react to incoming data; that’s their point.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior SoftwareEngineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior SoftwareEngineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
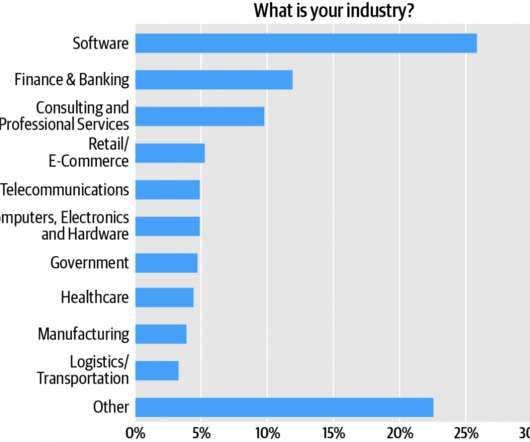
Softwareengineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). software and systems architects, technical leads—architects represent almost 28% of the sample. However, relationships in the data hint at several critical factors for success. Monolithic UI.
STP213 Scaling global carbon footprint management — Blake Blackwell Persefoni Manager DataEngineering and Michael Floyd AWS Head of Sustainability Solutions. SUS312 How innovators are driving more sustainable manufacturing — Marcus Ulmefors Northvolt Director Data and ML Platforms and Muhammad Sajid AWS SA. AWS Inferentia 2.6x
Over specialisation is considered good in industries such as healthcare and aviation but in softwareengineering over specialisation can be a blocker. Unlike healthcare and aviation where practices don't change over the decades, software technology is changing every day. product) don't change over a long period. Probably yes.
Entirely new paradigms rise quickly: cloud computing, dataengineering, machine learning engineering, mobile development, and large language models. To further complicate things, topics like cloud computing, software operations, and even AI don’t fit nicely within a university IT department.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content