This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. In the Reliability space, our data teams focus on two main approaches.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
This is a guest post by Eunice Do , DataEngineer at TripleLift , a technology company leading the next generation of programmatic advertising. The system is the data pipeline at TripleLift. TripleLift is an adtech company, and like most companies in this industry, we deal with high volumes of data on a daily basis.
Edge computing has transformed how businesses and industries process and manage data. By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Data interception during transit. Redundancy and inefficiency in data aggregation.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Setting up a data warehouse is the first step towards fully utilizing big data analysis. Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation.
Our goal is to manage security risks to Netflix via clear, opinionated security guidance, and by providing risk context to Netflix engineering teams to make pragmatic risk decisions at scale. We’ve also discovered, through interviews with engineers, that self-service guidance doesn’t stand on its own.
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior Software Engineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint.
Zendesk reduced its data storage costs by over 80% by migrating from DynamoDB to a tiered storage solution using MySQL and S3. The company considered different storage technologies and decided to combine the relational database and the object store to strike a balance between querybility and scalability while keeping the costs down.
He specifically delved into Venice DB, the NoSQL data store used for feature persistence. At the QCon London 2024 conference, Félix GV from LinkedIn discussed the AI/ML platform powering the company’s products. By Rafal Gancarz
Building data pipelines can offer strategic advantages to the business. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines. Data pipeline initiatives are generally unfinished projects. In this post, we will discuss why you should avoid building data pipelines in first place.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here.
In the era of big data and complex data processing, data pipelines have emerged as a popular solution for managing and manipulating data. They provide a systematic approach to extract, transform, and load (ETL) data from various sources, enabling organizations to derive valuable insights.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Werner Vogels weblog on building scalable and robust distributed systems. Which makes this week a good moment to read up on some of the historical work around the costs of dataengineering. All Things Distributed. Back-to-Basics Weekend Reading - The 5 Minute Rule. By Werner Vogels on 24 August 2012 04:00 PM. Comments ().
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior Software Engineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint.
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior Software Engineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint.
We live in a world where massive volumes of data are generated from websites, connected devices and mobile apps. In such a data intensive environment, making key business decisions such as running marketing and sales campaigns, logistic planning, financial analysis and ad targeting require deriving insights from these data.
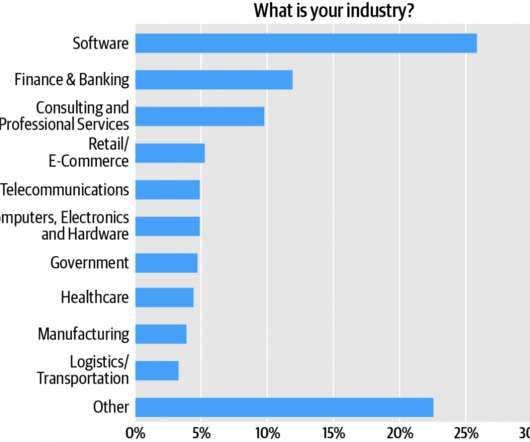
Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. However, relationships in the data hint at several critical factors for success. Figure 1: Respondent roles. Monolithic UI.
For Percona Live Europe, I’ll be presenting the tutorial Elasticsearch 101 alongside my colleagues and fellow presenters from ObjectRocket Alex Cercel, DBA, and Mihai Aldoiu, DataEngineer. Here’s a brief overview of our tutorial.
AWS recently announced the general availability (GA) of Amazon EC2 P5 instances powered by the latest NVIDIA H100 Tensor Core GPUs suitable for users that require high performance and scalability in AI/ML and HPC workloads. The GA is a follow-up to the earlier announcement of the development of the infrastructure. By Steef-Jan Wiggers
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content