This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. What is late-arriving data? Let’s dive in!
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
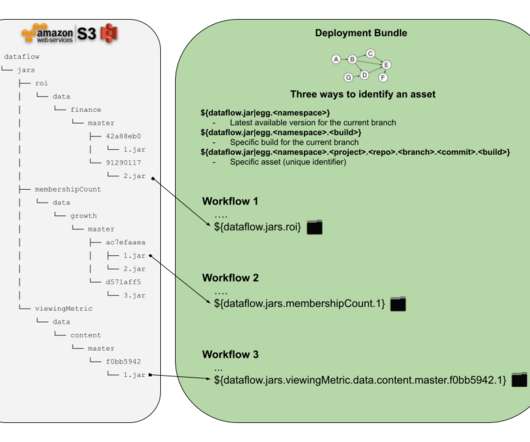
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch data pipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Data pipeline asset management with Dataflow.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. For example?—?clinical
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
JAR) form to be executed as part of the user defined data pipeline. data pipeline ?—?a DAG) for the purpose of transforming data using some business logic. Netflix homegrown CLI tool for data pipeline management. task, an atomic unit of data transformation logic, a non-separable execution block in the workflow chain.
Here we describe the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at Netflix, including how our platform investments support running tests at scale while enabling innovation. Curious to learn more about other Data Science and Engineering functions at Netflix?
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
In this tutorial, you are going to learn about QuestDB SQL extensions which prove to be very useful with time-series data. Using some sample data sets, you will learn how designated timestamps work and how to use extended SQL syntax to write queries on time-series data.
Maintaining Uber’s large-scale data warehouse comes with an operational cost in terms of ETL functions and storage. Once identified, … The post Less is More: EngineeringData Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog.
Edge computing has transformed how businesses and industries process and manage data. By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Data interception during transit. Redundancy and inefficiency in data aggregation.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
In this article, Rogerio Robetti discusses the challenges in auto-scaling stateful storage systems and proposes an opinionated design solution to automatically scale up (vertical) and scale out (horizontal) from a single node up to several nodes in a cluster with minimum configuration and interference of the operator. By Rogerio Robetti
Stephanie Lane , Wenjing Zheng , Mihir Tendulkar Source credit: Netflix Within the rapid expansion of data-related roles in the last decade, the title Data Scientist has emerged as an umbrella term for myriad skills and areas of business focus. Learning through data is in Netflix’s DNA. It can be hard to know from the outside.
After recreating the dataset, you can plot the raw numbers and perform custom analyses to understand the distribution of the data across test cells. However, the default reports only provide a summary view of the data with some powerful but limited filtering options.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
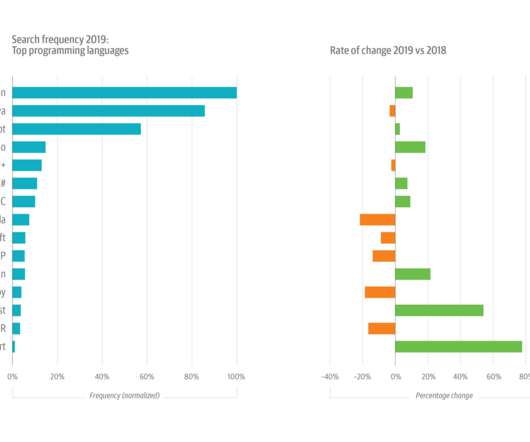
It’s also the data source for our annual usage study, which examines the most-used topics and the top search terms. [1]. This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers.
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
He specifically delved into Venice DB, the NoSQL data store used for feature persistence. At the QCon London 2024 conference, Félix GV from LinkedIn discussed the AI/ML platform powering the company’s products. By Rafal Gancarz
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Stateful JavaScript Apps. Generous free tier.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Stateful JavaScript Apps. Generous free tier.
This allows data to be sent to the device from backend services on demand, without the need for continually polling requests from the device. To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
Building data pipelines can offer strategic advantages to the business. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines. Data pipeline initiatives are generally unfinished projects. In this post, we will discuss why you should avoid building data pipelines in first place.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Cool Products and Services.
By collecting, accessing and analyzing network data from a variety of sources like VPC Flow Logs, ELB Access Logs, Custom Exporter Agents, etc, we can provide Network Insight to users through multiple data visualization techniques like Lumen , Atlas , etc. At Netflix we publish the Flow Log data to Amazon S3.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Learn how world-class tech companies crush the hiring game! Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Cool Products and Services.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content