This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Financial dataengineering in SAS involves the management, processing, and analysis of financial data using the various tools and techniques provided by the SAS software suite. Here are some key aspects of financial dataengineering in SAS: 1.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community!
However, amidst this rapid evolution, ensuring a robust data universe characterized by high quality and integrity is indispensable. While much emphasis is often placed on refining AI models, the significance of pristine datasets can sometimes be overshadowed.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. What is late-arriving data? Let’s dive in!
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
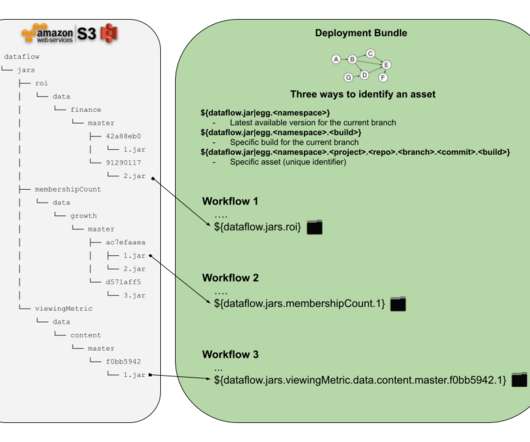
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch data pipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Data pipeline asset management with Dataflow.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. For example?—?clinical
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
Data migration is the process of moving data from one location to another, which is an essential aspect of cloud migration. Data migration involves transferring data from on-premise storage to the cloud. With the rapid adoption of cloud computing , businesses are moving their IT infrastructure to the cloud.
In software engineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go.
In the data-driven landscape of today, automation has become indispensable across industries, not just to maximize efficiency but, more importantly, to ensure quality. This holds true for the critical field of dataengineering as well. Automated testing methodologies are now imperative to deliver speed, accuracy, and integrity.
It's midnight in the dim and cluttered office of The New York Times, currently serving as the "situation room." A powerful surge of traffic is inevitable. During every major election, the wave would crest and crash against our overwhelmed systems before receding, allowing us to assess the damage.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
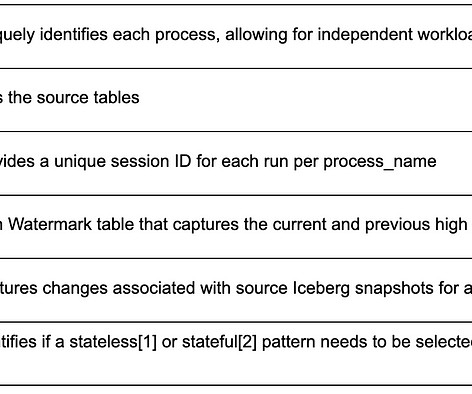
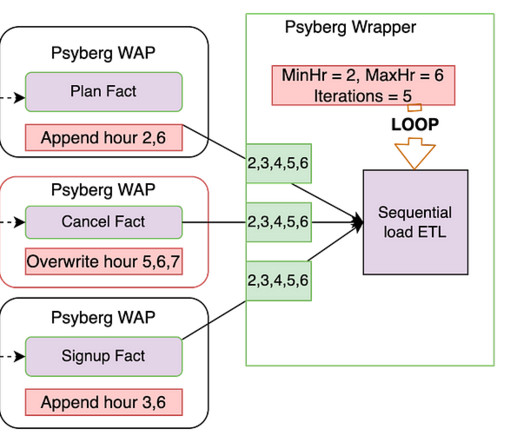
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance dataengineering team.
JAR) form to be executed as part of the user defined data pipeline. data pipeline ?—?a DAG) for the purpose of transforming data using some business logic. Netflix homegrown CLI tool for data pipeline management. task, an atomic unit of data transformation logic, a non-separable execution block in the workflow chain.
In an era characterized by an exponential increase in data generation, organizations must effectively leverage this wealth of information to maintain their competitive edge. As dataengineers, we are tasked with implementing these sophisticated solutions, ensuring organizations can derive actionable insights from vast datasets.
This is a guest post by Eunice Do , DataEngineer at TripleLift , a technology company leading the next generation of programmatic advertising. The system is the data pipeline at TripleLift. TripleLift is an adtech company, and like most companies in this industry, we deal with high volumes of data on a daily basis.
and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley. What was your path to working in data? There’s us to the right!
Data lineage, an automated visualization of the relationships for how data flows across tables and other data assets, is a must-have in the dataengineering toolbox.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. In the Reliability space, our data teams focus on two main approaches.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. This nuanced integration of data and technology empowers us to offer bespoke content recommendations. This queue ensures we are consistently capturing raw events from our global userbase.
In this tutorial, you are going to learn about QuestDB SQL extensions which prove to be very useful with time-series data. Using some sample data sets, you will learn how designated timestamps work and how to use extended SQL syntax to write queries on time-series data.
Edge computing has transformed how businesses and industries process and manage data. By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Data interception during transit. Redundancy and inefficiency in data aggregation.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Welcome to the first post in our exciting series on mastering offline data pipeline's best practices, focusing on the potent combination of Apache Airflow and data processing engines like Hive and Spark. Working together, they form the backbone of many modern dataengineering solutions.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making.
In June 2021, we asked the recipients of our Data & AI Newsletter to respond to a survey about compensation. The average salary for data and AI professionals who responded to the survey was $146,000. We didn’t use the data from these respondents; in practice, discarding this data had no effect on the results.
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful Data Processing. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep data pipeline. Audit Run various quality checks on the staged data.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Stephanie Lane , Wenjing Zheng , Mihir Tendulkar Source credit: Netflix Within the rapid expansion of data-related roles in the last decade, the title Data Scientist has emerged as an umbrella term for myriad skills and areas of business focus. Learning through data is in Netflix’s DNA. It can be hard to know from the outside.
Scripts and procedures usually focus on a particular task, such as deploying a new microservice to a Kubernetes cluster, implementing data retention policies on archived files in the cloud, or running a vulnerability scanner over code before it’s deployed. Big data automation tools. Batch process automation.
He specifically delved into Venice DB, the NoSQL data store used for feature persistence. At the QCon London 2024 conference, Félix GV from LinkedIn discussed the AI/ML platform powering the company’s products. By Rafal Gancarz
Maintaining Uber’s large-scale data warehouse comes with an operational cost in terms of ETL functions and storage. Once identified, … The post Less is More: EngineeringData Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog.
We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our big data platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis.
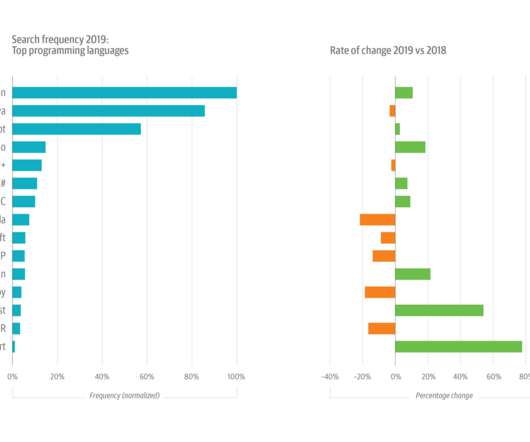
It’s also the data source for our annual usage study, which examines the most-used topics and the top search terms. [1]. This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. A drill-down into data, AI, and ML topics.
From a dataengineer's point of view, financial risk management is a series of data analysis activities on financial data. The financial sector imposes its unique requirements on dataengineering. Before they adopted an OLAP engine, they were using Kettle to collect data.
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
SIEM systems enable early detection of security threats and suspicious activities by analyzing vast amounts of log data in real time. Correlation Engine: SIEM systems analyze and correlate the collected data to identify patterns, anomalies, and potential security incidents.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content