This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
For instance, a streaming service can employ vector search to recommend films tailored to individual viewing histories and ratings, while a retail brand can analyze customer sentiments to fine-tune marketing strategies.
Without a defined schema, it can be difficult to determine whether missing data was intentional or due to a logging error. Automating Performance Tuning with Autoscalers Tuning the performance of our Apache Flink jobs is currently a manual process.
Expect to spend time fine-tuning automation scripts as you find the right balance between automated and manual processing. This requires significant dataengineering efforts, as well as work to build machine-learning models. By tuning workflows, you can increase their efficiency and effectiveness.
The Engineer enjoys making data available by piping it in from new sources in optimal ways, building robust data models, prototyping systems, and doing project-specific engineering.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
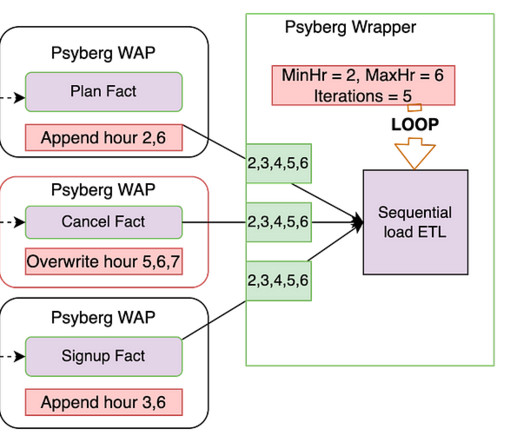
This helps overwrite data only when required and minimizes unnecessary reprocessing. As seen above, by chaining these Psyberg workflows, we could automate the catchup for late-arriving data from hours 2 and 6. The DataEngineer does not need to perform any manual intervention in this case and can thus focus on more important things!
Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster. Orient: Gather tuning parameters for a particular table that changed.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Please share your experience by adding your comments below and stay tuned for more on data lineage at Netflix in the follow up blog posts. .
And in order to gain visibility into these logs, we need to somehow ingest and enrich this data. It is easier to tune a large Spark job for a consistent volume of data. In other words, we are able to ensure that our Spark app does not “eat” more data than it was tuned to handle. We named this library Sqooby.
The folks on the Cloud DataEngineering (CDE) team, the ones building the paved path for internal data at Netflix, graciously helped us scale it up and make adjustments, but it ended up being an involved process as we kept growing. We’ll be writing about those new features as well — stay tuned for future posts.
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers.
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
It is a general-purpose workflow orchestrator that provides a fully managed workflow-as-a-service (WAAS) to the data platform at Netflix. It serves thousands of users, including data scientists, dataengineers, machine learning engineers, software engineers, content producers, and business analysts, for various use cases.
Jules Damji discusses which infrastructure should be used for distributed fine-tuning and training, how to scale ML workloads, how to accommodate large models, and how can CPUs and GPUs be utilized? By Jules Damji
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
He specifically delved into Venice DB, the NoSQL data store used for feature persistence. At the QCon London 2024 conference, Félix GV from LinkedIn discussed the AI/ML platform powering the company’s products. By Rafal Gancarz
Because you are changing team composition, you need robust norms of conduct and engineering practices in place. Secondly, fine-tune team composition based on work. Thirdly, let engineers themselves choose the delivery teams and organise them around the initiative.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content