This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For ETL and other heavy lifting of data, we mainly rely on Apache Spark. In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training. Correspondingly, each application brings its own bespoke set of dependencies.
AI that is based on machine learning needs to be trained. This requires significant dataengineering efforts, as well as work to build machine-learning models. While automating IT processes without integrated AIOps can create challenges, the approach to artificial intelligence itself can also introduce potential issues.
Key issues include: A shortage of edge-native dataengineers and architects. High costs of training and retaining talent. Upskill existing teams with training in edge technologies and related disciplines like IoT and AI. Limited understanding of edge-specific use cases among traditional IT teams.
Most respondents participated in training of some form. Learning new skills and improving old ones were the most common reasons for training, though hireability and job security were also factors. Company-provided training opportunities were most strongly associated with pay increases. Demographics. Salaries by Gender.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
Service Integrations Figure 2 illustrates the integration of the services generating and applying the recommendations in the data platform. The major services are as follows: Nightingale is a service running the ML model trained using Metaflow and is responsible for generating a retry recommendation.
First, the behavior of an AI application depends on a model , which is built from source code and trainingdata. A model isn’t source code, and it isn’t data; it’s an artifact built from the two. You need a repository for models and for the trainingdata. Second, the behavior of AI systems changes over time.
A role in data science eventually seemed like a natural transition, but it wasn’t without its hurdles: With my consulting background, I had to go through a few other roles first while learning how to code on the side. Tell me about some of the exciting projects you’re a part of.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
IPS enables users to continue to use the data processing patterns with minimal changes. Introduction Netflix relies on data to power its business in all phases. As our business scales globally, the demand for data is growing and the needs for scalable low latency incremental processing begin to emerge. past 3 hours or 10 days).
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Jules Damji discusses which infrastructure should be used for distributed fine-tuning and training, how to scale ML workloads, how to accommodate large models, and how can CPUs and GPUs be utilized? By Jules Damji
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Edureka typically provides Instructor-led training courses which help aspiring candidates to learn interactively. The best courses relevant to Automation Testing on Edureka are: Selenium Certification Training Performance Testing using Jmeter Ruby with Cucumber Certification Testing. It depends on what stage of learning you are at.
Provides comparison of inference workload on P4dn GPU instances vs. AWS Trainium saving 92% energy and 90% cost, and training workload on P4dn vs. AWS Inferentia 2.6x shorter training time, saving 54% energy and 75% cost. Good discussion of the embodied carbon of silicon chip production.
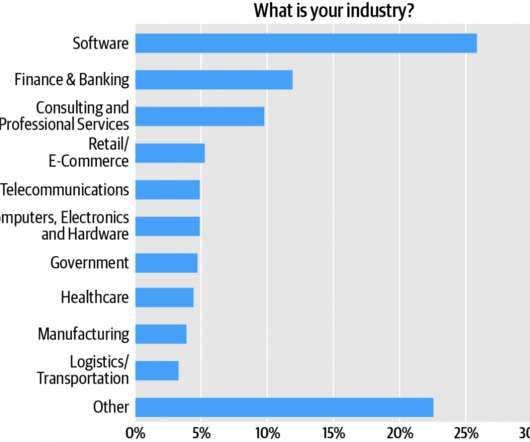
Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. That said, the audience for this survey—like those of almost all Radar surveys—is disproportionately technical. Figure 1: Respondent roles.
We’ve got you covered), partnering with friends on a fascinating open source project, our most comprehensive training course yet, plenty of speaking engagements (see our expanding portfolio of talks that we can give to your team here ), and a revisit of an old friend. A top-to-bottom review has brought it right up to date?—?you You got it!
Luckily, aircraft operating manuals and training procedures are so formalised and well established that there is no scope of performance degradation even if one or more crew members are replaced. Thirdly, let engineers themselves choose the delivery teams and organise them around the initiative.
They don’t respond to changes quickly, and that leaves them particularly vulnerable when providing training for industries where change is rapid. Staying current in the tech industry is a bit like being a professional athlete: You have to train daily to maintain your physical conditioning.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content