This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community! In this video, Sr.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
This holds true for the critical field of dataengineering as well. As organizations gather and process astronomical volumes of data, manual testing is no longer feasible or reliable. Automated testing methodologies are now imperative to deliver speed, accuracy, and integrity.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
This talk covers ways to leverage software engineering practices for dataengineering and demonstrates how measuring key performance metrics could help build more robust and reliable data pipelines.
The most commonly used one is dataflow project , which helps folks in managing their data pipeline repositories through creation, testing, deployment and few other activities. It lets you create YAML formatted mock data files based on selected tables, columns and a few rows of data from the Netflix data warehouse.
Key issues include: A shortage of edge-native dataengineers and architects. The post These 7 Edge Data Challenges Will Test Companies the Most in 2025 appeared first on Volt Active Data. Limited understanding of edge-specific use cases among traditional IT teams. High costs of training and retaining talent.
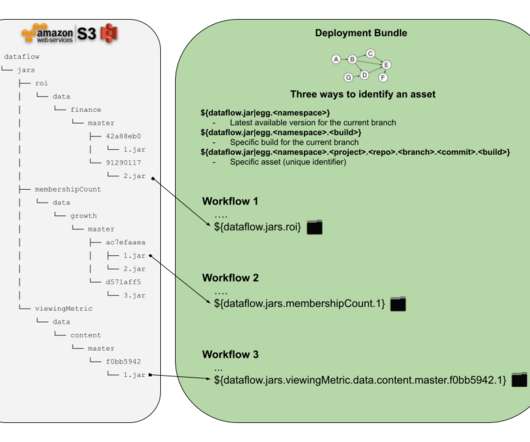
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. How do you set up your deployment logic to know when to deploy the workflow to a test or dev environment? Is a single location enough? setup.py ???
Testing automation can be painstaking. It’s also crucial to test frequently when automating IT operations so that you don’t automatically replicate mistakes. This requires significant dataengineering efforts, as well as work to build machine-learning models.
Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group. Learning through data is in Netflix’s DNA. We use A/B tests to introduce new product features, such as our daily Top 10 row that help our members discover their next favorite show.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. What will be the cost of rolling out the winning cell of an AB test to all users?
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers.
IPS enables users to continue to use the data processing patterns with minimal changes. Introduction Netflix relies on data to power its business in all phases. Users configure the workflow to read the data in a window (e.g. data arrives too late to be useful). past 3 hours or 10 days).
I focus on improving experimentation methodology to test how well the newest files are working: do they need less bits to stream while providing a higher video quality? When we test new encodes, we need effective data science methods to quickly and accurately understand whether customers are having a better experience.
On one hand, ops groups are in a good position to do this; they’re already heavily invested in testing, monitoring, version control, reproducibility, and automation. This has important implications for testing. In the last two decades, a tremendous amount of work has been done on testing and building test suites.
This article presents a list of some of the best available online Automation Testing courses and certifications you can consider. Hope this answers a few queries we receive for suggestions on Online Automation Testing Courses and Certifications. There are various courses listed on Udemy which can help people learn automation testing.
Get test automation improved (10-20%). Increase automated test cover (30-40%) and start implementing property tests like performance and load testing. Test coverage (50-70%). Introduce site-reliability engineering best-practices (SLI/SLOs). Skills++: Induct Site-reliability engineers, Dataengineers.
Fetishizing unit testing. The most important is discovering how to work with data science and artificial intelligence projects. Development timelines for these projects aren’t as predictable as traditional software; they stretch the meaning of “testing” in strange ways; they aren’t deterministic.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. This work would have not been possible without the solid, in-depth collaborations.
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
There are shadow IT teams of developers or dataengineers that spring up in areas like operations or marketing because the captive IT function is slow, if not outright incapable, of responding to internal customer demand. Iteration plans are commitments; unit tests are guarantees of quality. The scope taken out of the 1.0
Setting up a data warehouse is the first step towards fully utilizing big data analysis. Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation.
Most (74%) respondents say their teams own the build-test-deploy-maintain phases of the software lifecycle. Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. Success with containers.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next.
Depending on work you can choose a smaller team of similar expertise (for example a team with mostly frontend engineers) or a smaller team of diverse expertise (team with balanced frontend, backend, dataengineers). Thirdly, let engineers themselves choose the delivery teams and organise them around the initiative.
Here we describe the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at Netflix, including how our platform investments support running tests at scale while enabling innovation. Curious to learn about what it’s like to be a DataEngineer at Netflix?
Toby Mao , Sri Sri Perangur , Colin McFarland Another day, another custom script to analyze an A/B test. You can look at ABlaze (our centralized A/B testing platform) and take a quick look at how it’s performing. At any point a Netflix user is in many different A/B tests orchestrated through ABlaze. Not at Netflix.
Batch processing data may provide a similar impact and take significantly less time. Its easier to develop and maintain, and tends to be more familiar for analytics engineers, data scientists, and dataengineers. Additionally, if you are developing a proof of concept, the upfront investment may not be worth it.
Entirely new paradigms rise quickly: cloud computing, dataengineering, machine learning engineering, mobile development, and large language models. It’s less risky to hire adjunct professors with industry experience to fill teaching roles that have a vocational focus: mobile development, dataengineering, and cloud computing.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content