This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. Give us a holler if you are interested in a thought exchange.
By Astha Singhal , Lakshmi Sudheer , Julia Knecht The Application Security teams at Netflix are responsible for securing the software footprint that we create to run the Netflix product, the Netflix studio, and the business. Our customers are product and engineering teams at Netflix that build these software services and platforms.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior SoftwareEngineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
Introduce scalable microservices architectures to distribute computational loads efficiently. Interoperability Between Edge Devices Edge ecosystems often involve a heterogeneous mix of devices from different manufacturers, each with proprietary software and communication protocols. High costs of training and retaining talent.
As Big data and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Another dimension of scalability to consider is the size of the workflow.
In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training. Occasionally, these use cases involve terabytes of data, so we have to pay attention to performance. Internally, we use a production workflow orchestrator called Maestro.
Whether in analyzing A/B tests, optimizing studio production, training algorithms, investing in content acquisition, detecting security breaches, or optimizing payments, well structured and accurate data is foundational. Users configure the workflow to read the data in a window (e.g. data arrives too late to be useful).
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Who's Hiring? Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
Scrapinghub is hiring a Senior SoftwareEngineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Try out their platform.
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior SoftwareEngineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior SoftwareEngineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
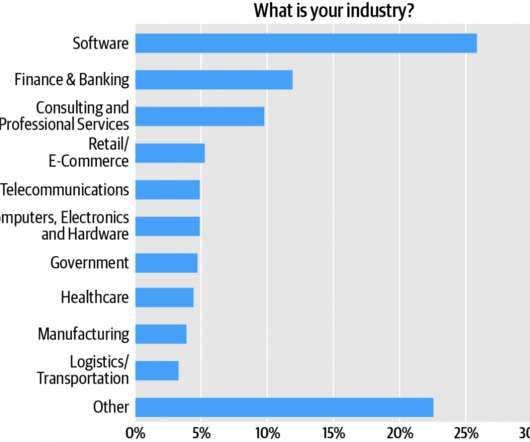
Success with microservices means owning the software lifecycle. Most (74%) respondents say their teams own the build-test-deploy-maintain phases of the software lifecycle. Softwareengineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). Success with containers.
Lastly, we will talk about the internal platform and product divide – one key reason why data pipeline initiatives typically fail – and why it is better working backward from the product. Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. A data pipeline is a software which runs on hardware.
Today, I am excited to share with you a brand new service called Amazon QuickSight that aims to simplify the process of deriving insights from a wide variety of data sources in a fast and affordable manner. QuickSight is a fast, cloud native, scalable, business intelligence service for the 1/10th the cost of old-guard BI solutions.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Native frameworks.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content