This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Dataengineering projects often require the setup and management of complex infrastructures that support dataprocessing, storage, and analysis. Traditionally, this process involved manual configuration, leading to potential inconsistencies, human errors, and time-consuming deployments.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processesdata that are newly added or updated to a dataset, instead of re-processing the complete dataset.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
This is a guest post by Eunice Do , DataEngineer at TripleLift , a technology company leading the next generation of programmatic advertising. The system is the data pipeline at TripleLift. TripleLift is an adtech company, and like most companies in this industry, we deal with high volumes of data on a daily basis.
This operational component places some cognitive load on our engineers, requiring them to develop deep understanding of telemetry and alerting systems, capacity provisioning process, security and reliability best practices, and a vast amount of informal knowledge about the cloud infrastructure.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Nonetheless, Netflix data landscape (see below) is complex and many teams collaborate effectively for sharing the responsibility of our data system management.
They’re still analysts at heart but, similar to dataengineers, they have a deep understanding of data warehouse capabilities and are pros at dataprocessing optimization and performance tuning.
Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation. This is where data is extracted, transformed, and loaded (ETL) or extracted, loaded, and transformed (ELT).
Edge computing has transformed how businesses and industries process and manage data. By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Leverage tiered storage systems that dynamically offload data based on priority.
There are several benefits of such optimizations like saving on storage, faster query time, cheaper downstream processing, and an increase in developer productivity by removing additional ETLs written only for query performance improvement. Some of the optimizations are prerequisites for a high-performance data warehouse.
For ETL and other heavy lifting of data, we mainly rely on Apache Spark. In addition to Spark, we want to support last-mile dataprocessing in Python, addressing use cases such as feature transformations, batch inference, and training. We use Apache Arrow to decode Parquet and to host an in-memory representation of data.
As Big data and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Another dimension of scalability to consider is the size of the workflow.
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. We explore all the systems necessary to make and stream content from Netflix.
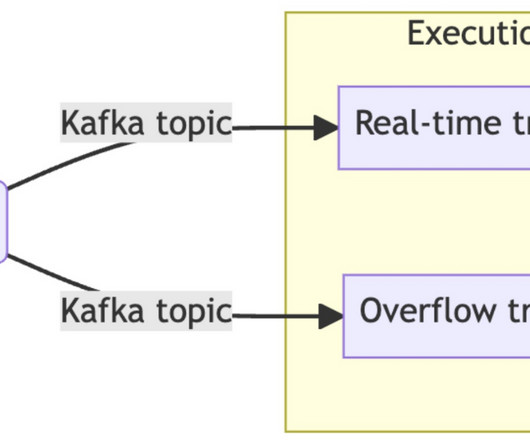
HubSpot adopted routing messages over multiple Kafka topics (called swimlanes) for the same producer to avoid the build-up in the consumer group lag and prioritize the processing of real-time traffic.
Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io's bestselling new 4-course learning track: Scalability and System Design for Developers. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io's bestselling new 4-course learning track: Scalability and System Design for Developers. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io's bestselling new 4-course learning track: Scalability and System Design for Developers. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
Created by former senior-level AWS engineers of 15 years. Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io 's bestselling new 4-course learning track: Scalability and System Design for Developers. We take you through the hiring process from start to finish.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Werner Vogels weblog on building scalable and robust distributed systems. Which makes this week a good moment to read up on some of the historical work around the costs of dataengineering. All Things Distributed. Back-to-Basics Weekend Reading - The 5 Minute Rule. By Werner Vogels on 24 August 2012 04:00 PM. Comments ().
In such a data intensive environment, making key business decisions such as running marketing and sales campaigns, logistic planning, financial analysis and ad targeting require deriving insights from these data. However, the data infrastructure to collect, store and processdata is geared toward developers (e.g.,
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. We explore all the systems necessary to make and stream content from Netflix.
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. We explore all the systems necessary to make and stream content from Netflix.
In recent times, in order to gain valuable insights or to develop the data-driven products companies such as Netflix, Spotify, Uber, AirBnB have built internal data pipelines. If built correctly, data pipelines can offer strategic advantages to the business. Depending on frameworks, dataprocessing units (a.k.a
In the era of big data and complex dataprocessing, data pipelines have emerged as a popular solution for managing and manipulating data. They provide a systematic approach to extract, transform, and load (ETL) data from various sources, enabling organizations to derive valuable insights.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big dataprocessing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Native frameworks.
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
This diverse technological landscape generates extensive and rich data from various infrastructure entities, from which, dataengineers and analysts collaborate to provide actionable insights to the engineering organization in a continuous feedback loop that ultimately enhances the business.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content