This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The results are biased by the survey’s recipients (subscribers to O’Reilly’s Data & AI Newsletter ). Our audience is particularly strong in the software (20% of respondents), computer hardware (4%), and computer security (2%) industries—over 25% of the total. But more women than men saw their salaries decrease (10% versus 7%).
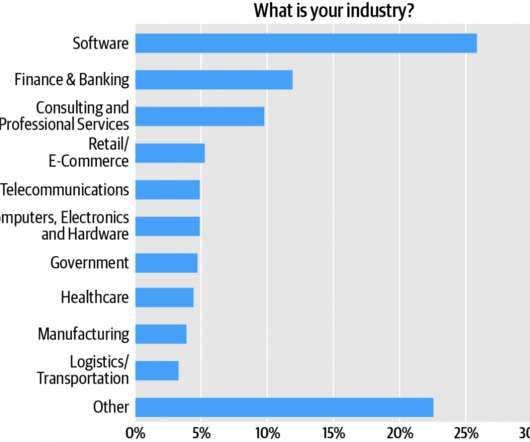
Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. Combined, technology verticals—software, computers/hardware, and telecommunications—account for about 35% of the audience (Figure 2).
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next.
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content