This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Wednesday?—?December The talk also includes examples of using these tools in the Amazon Elastic Compute Cloud (Amazon EC2) cloud.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Wednesday?—?December The talk also includes examples of using these tools in the Amazon Elastic Compute Cloud (Amazon EC2) cloud.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Wednesday?—?December The talk also includes examples of using these tools in the Amazon Elastic Compute Cloud (Amazon EC2) cloud.
Instead, in the style of nanoarrow , our Fast Data library only relies on the stable Arrow C data interface , producing a hermetically sealed library with no external dependencies. A key challenge in creating a knowledge graph is entity resolution. Internally, we use a production workflow orchestrator called Maestro.
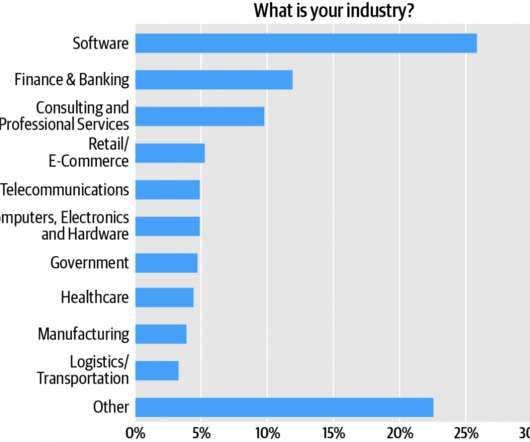
Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. That said, the audience for this survey—like those of almost all Radar surveys—is disproportionately technical. Figure 1: Respondent roles.
To learn about Analytics and Viz Engineering, have a look at Analytics at Netflix: Who We Are and What We Do by Molly Jackman & Meghana Reddy and How Our Paths Brought Us to Data and Netflix by Julie Beckley & Chris Pham. Curious to learn about what it’s like to be a DataEngineer at Netflix?
They require teams of dataengineers to spend months building complex data models and synthesizing the data before they can generate their first report. I am pleased to share some of the positive feedback from our preview customers like MLB Advanced Media, Infor, and Hotelbeds.com.
Batch processing data may provide a similar impact and take significantly less time. Its easier to develop and maintain, and tends to be more familiar for analytics engineers, data scientists, and dataengineers. Additionally, if you are developing a proof of concept, the upfront investment may not be worth it.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content