This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community!
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. What is late-arriving data?
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
During every major election, the wave would crest and crash against our overwhelmed systems before receding, allowing us to assess the damage. It's midnight in the dim and cluttered office of The New York Times, currently serving as the "situation room." A powerful surge of traffic is inevitable.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure.
From a dataengineer's point of view, financial risk management is a series of data analysis activities on financial data. The financial sector imposes its unique requirements on dataengineering. Before they adopted an OLAP engine, they were using Kettle to collect data.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making.
This is a guest post by Eunice Do , DataEngineer at TripleLift , a technology company leading the next generation of programmatic advertising. What is the name of your system and where can we find out more about it? The system is the data pipeline at TripleLift. Why did you decide to build this system?
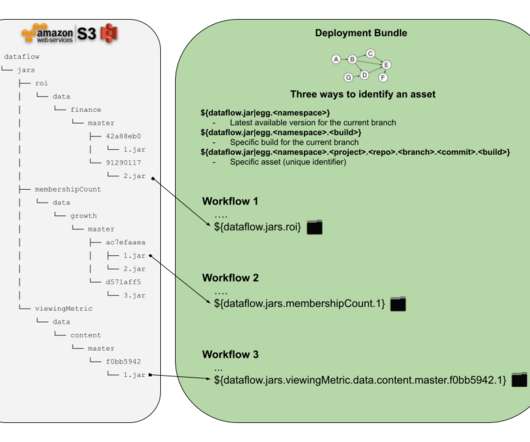
The dataflow migration command is a special feature, developed single handedly by Stephen Huenneke , to fully automate the communication and tracking of a data warehouse table changes. Running code against a production database can be slow, especially with the overhead required for distributed data processing systems like Apache Spark.
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission.
see “data pipeline” Intro The problem of managing scheduled workflows and their assets is as old as the use of cron daemon in early Unix operating systems. The design of a cron job is simple, you take some system command, you pick the schedule to run it on and you are done. Manually constructed continuous delivery system.
In this article, Rogerio Robetti discusses the challenges in auto-scaling stateful storage systems and proposes an opinionated design solution to automatically scale up (vertical) and scale out (horizontal) from a single node up to several nodes in a cluster with minimum configuration and interference of the operator. By Rogerio Robetti
As organizations continue to adopt multicloud strategies, the complexity of these environments grows, increasing the need to automate cloud engineering operations to ensure organizations can enforce their policies and architecture principles. This requires significant dataengineering efforts, as well as work to build machine-learning models.
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers. Labeling the data?
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
Due to its popularity, the number of workflows managed by the system has grown exponentially. The scheduler on-call has to closely monitor the system during non-business hours. As the usage increased, we had to vertically scale the system to keep up and were approaching AWS instance type limits.
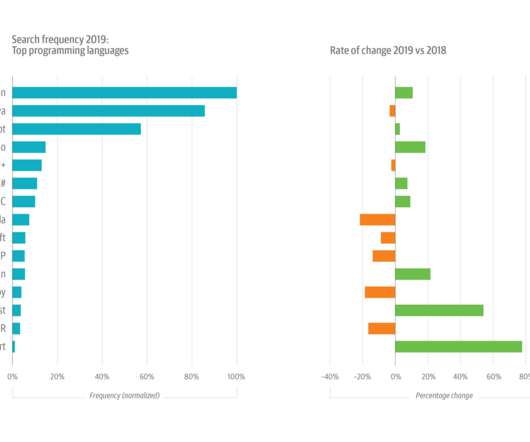
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. there’s a Python library for virtually anything a developer or data scientist might need to do. In aggregate, dataengineering usage declined 8% in 2019.
SIEM systems enable early detection of security threats and suspicious activities by analyzing vast amounts of log data in real time. Correlation Engine: SIEM systems analyze and correlate the collected data to identify patterns, anomalies, and potential security incidents.
Use cases We found several use cases where a system like AutoOptimize can bring tons of value. Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster.
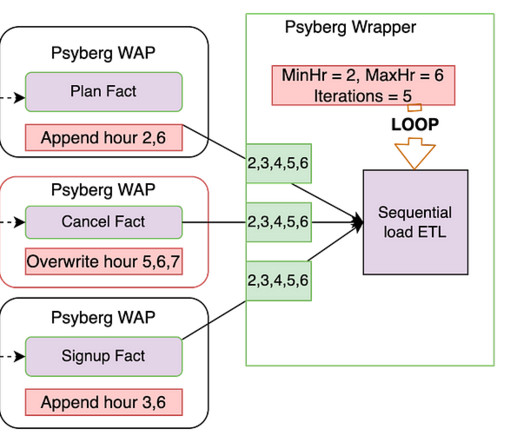
Data Load Type : The ETL can either load the missed/new data specifically or reload the entire specified range. This helps overwrite data only when required and minimizes unnecessary reprocessing. As seen above, by chaining these Psyberg workflows, we could automate the catchup for late-arriving data from hours 2 and 6.
Data Security With edge devices dispersed across various locations, securing data from creation to consumption has become a critical challenge. Unlike centralized systems, where data resides in a single, well-protected environment, edge computing increases the attack surface, making systems vulnerable to breaches.
Introduction At Netflix, hundreds of thousands of workflows and millions of jobs are running per day across multiple layers of the big data platform. Rule Execution Engine is responsible for matching the collected logs against a set of predefined rules. the scheduler, job orchestrator, and compute clusters). Unclassified errors.
Sample system diagram for an Alexa voice command. The other main use case was RENO, the Rapid Event Notification System mentioned above. Rewriting always comes with a risk, and it’s never the first solution we reach for, particularly when working with a system that’s in place and working well.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Stateful JavaScript Apps. Generous free tier.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Stateful JavaScript Apps. Generous free tier.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
When it comes to organising engineering teams, a popular view has been to organise your teams based on either Spotify's agile model (i.e. One thing stand-out to me is being intentional and practical about your engineering organisation design. squads, chapters, tribes, and guilds) or simply follow Amazon's two-pizza team model.
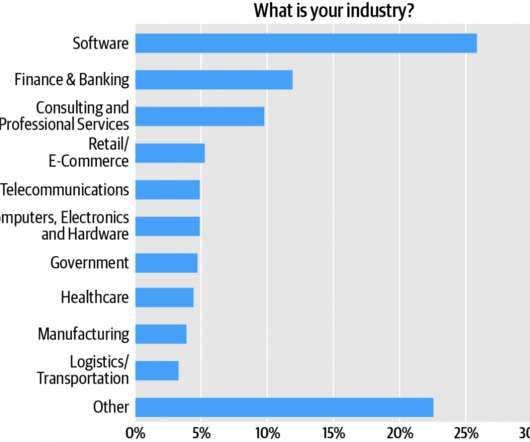
Almost one-third (29%) of respondents say their employers are migrating or implementing a majority of their systems (over 50%) using microservices. Software engineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). Adopters are betting big on microservices. What does that mean?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Advertise your job here! Cool Products and Services.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content