This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. All these micro-services are currently operated in AWS cloud infrastructure.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making.
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
Our customers are product and engineering teams at Netflix that build these software services and platforms. Our goal is to manage security risks to Netflix via clear, opinionated security guidance, and by providing risk context to Netflix engineering teams to make pragmatic risk decisions at scale.
As Big data and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Another dimension of scalability to consider is the size of the workflow.
This is a guest post by Eunice Do , DataEngineer at TripleLift , a technology company leading the next generation of programmatic advertising. The system is the data pipeline at TripleLift. TripleLift is an adtech company, and like most companies in this industry, we deal with high volumes of data on a daily basis.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. Please stop by our “Living Room” for an opportunity to connect or reconnect with Netflixers.
Without these integrations, projects would be stuck at the prototyping stage, or they would have to be maintained as outliers outside the systems maintained by our engineering teams, incurring unsustainable operational overhead. Importantly, all the use cases were engineered by practitioners themselves.
It also improves the engineering productivity by simplifying the existing pipelines and unlocking the new patterns. Whether in analyzing A/B tests, optimizing studio production, training algorithms, investing in content acquisition, detecting security breaches, or optimizing payments, well structured and accurate data is foundational.
Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster. Other Components Iceberg We use Apache Iceberg as the table format.
Inconsistent network performance affecting data synchronization. Introduce scalable microservices architectures to distribute computational loads efficiently. Key issues include: A shortage of edge-native dataengineers and architects. Limited understanding of edge-specific use cases among traditional IT teams.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
On top of that, there are real challenges to overcome in setting up streamlined data modeling processes, including dealing with relations between data points and simplifying the queries to make the whole set of processes scalable.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Zendesk reduced its data storage costs by over 80% by migrating from DynamoDB to a tiered storage solution using MySQL and S3. The company considered different storage technologies and decided to combine the relational database and the object store to strike a balance between querybility and scalability while keeping the costs down.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
Werner Vogels weblog on building scalable and robust distributed systems. Which makes this week a good moment to read up on some of the historical work around the costs of dataengineering. All Things Distributed. Back-to-Basics Weekend Reading - The 5 Minute Rule. By Werner Vogels on 24 August 2012 04:00 PM. Comments ().
However, the data infrastructure to collect, store and process data is geared toward developers (e.g., In AWS’ quest to enable the best data storage options for engineers, we have built several innovative database solutions like Amazon RDS, Amazon RDS for Aurora, Amazon DynamoDB, and Amazon Redshift. Big data challenges.
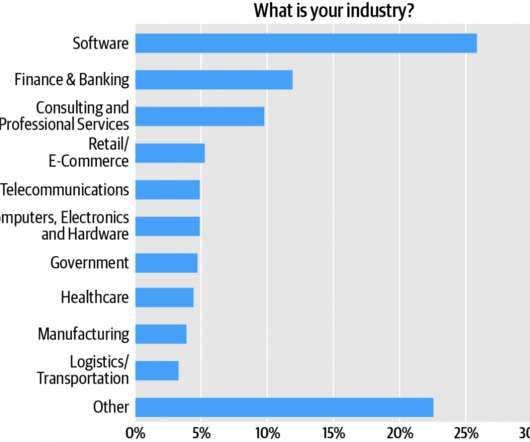
Software engineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). Adding architects and engineers, we see that roughly 55% of the respondents are directly involved in software development. Technical roles dominate, but management roles are represented, too.
In recent times, in order to gain valuable insights or to develop the data-driven products companies such as Netflix, Spotify, Uber, AirBnB have built internal data pipelines. If built correctly, data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features.
For Percona Live Europe, I’ll be presenting the tutorial Elasticsearch 101 alongside my colleagues and fellow presenters from ObjectRocket Alex Cercel, DBA, and Mihai Aldoiu, DataEngineer. Here’s a brief overview of our tutorial.
AWS recently announced the general availability (GA) of Amazon EC2 P5 instances powered by the latest NVIDIA H100 Tensor Core GPUs suitable for users that require high performance and scalability in AI/ML and HPC workloads. The GA is a follow-up to the earlier announcement of the development of the infrastructure. By Steef-Jan Wiggers
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Native frameworks.
The DAG Model and the Misconception Data pipelines are commonly implemented as Directed Acyclic Graphs (DAGs), where data flows through a series of processing steps, with each step represented as a node and the dependencies between steps represented as edges.
In this article, Rogerio Robetti discusses the challenges in auto-scaling stateful storage systems and proposes an opinionated design solution to automatically scale up (vertical) and scale out (horizontal) from a single node up to several nodes in a cluster with minimum configuration and interference of the operator. By Rogerio Robetti
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content